























Manufacturing intelligence with Amazon Nova Multimodal Embeddings
In this post, we build a multimodal retrieval system for aerospace manufacturing documents using Amazon Nova Multimodal Embeddings on Amazon Bedrock and Amazon S3 Vectors. We evaluate the system on 26 manufacturing queries and compare generation quality between a text-only pipeline and the multimodal pipeline.

If you work in aerospace, automotive, or heavy industry manufacturing, your organization likely maintains vast repositories of technical documents. These documents combine written specifications with engineering diagrams, CAD drawings, inspection photographs, thermal analysis plots, and fatigue curves. A text query about maximum wall temperature at the nozzle throat might have its answer locked inside a thermal contour plot rather than written prose. Text-only retrieval systems can’t surface that information because they don’t see the image content.
Amazon Nova Multimodal Embeddings addresses this gap by mapping text, images, and document pages into a shared vector space. A text query can retrieve an engineering diagram, and an image query can retrieve a written specification, because both modalities share the same coordinate system.
In this post, we build a multimodal retrieval system for aerospace manufacturing documents using Amazon Nova Multimodal Embeddings on Amazon Bedrock and Amazon S3 Vectors. We evaluate the system on 26 manufacturing queries and compare generation quality between a text-only pipeline and the multimodal pipeline.
Why multimodal retrieval matters for manufacturing
Most manufacturing documents combine text, diagrams, and images. A single work order might contain written assembly procedures alongside annotated photographs of completed steps. An inspection report pairs pass/fail measurements with radiographic images of weld joints. A material certification includes both tabular mechanical properties and S-N fatigue curves that an engineer must reference during design review.
Consider a few concrete examples of visual information from the dataset used in this post: A torque specification table is depicted inside an engineering drawing rather than stored as standalone text. A color-coded thermal contour plot is used to visualize peak temperatures across a rocket engine nozzle. A manufacturing process flow chart labels quality hold points visually with decision diamonds and color-coded gates, and the associated cycle times appear as annotations on the diagram itself.
Text-only retrieval systems handle these documents by extracting text through OCR, then embedding and indexing the extracted strings. This works when answers appear in the written portions of a document, but text-only systems miss the spatial relationships in diagrams, the visual patterns in inspection images, and the quantitative information encoded in plots and charts. When you make a search for the type of bearings used in the turbopump, the answer might appear as a labeled callout on a cross-section diagram that OCR either misreads or strips of its spatial context.
Multimodal embeddings take a different approach. Instead of converting images to text and then embedding the text, the model processes the image directly and produces a vector in the same space as text embeddings. A text query about turbopump bearings can match against the cross-section diagram in our dataset based on visual understanding, not just whatever text OCR managed to extract.
Amazon Nova Multimodal Embeddings overview
Amazon Nova Multimodal Embeddings is available in Amazon Bedrock and generates embeddings for text, images, and multipage documents. Text, image, and document modalities project into a single shared vector space, which means you can compute cosine similarity between a text embedding and an image embedding directly.
You can configure embedding dimensions from 256, 384, 1024, or 3072. Higher dimensions capture more semantic detail but require more storage and compute for similarity search. For the evaluation in this post, we use 1024 dimensions as a practical balance between retrieval quality and cost. The model also supports a DOCUMENT_IMAGE detail level, a processing mode designed for pages containing mixed content such as charts, tables, and annotated diagrams.
For retrieval workloads, the model accepts a purpose parameter set to either GENERIC_INDEX (for documents being indexed) or GENERIC_RETRIEVAL (for queries). This asymmetric embedding approach improves the vector space for retrieval without requiring manual query formatting.
Solution overview
We built two parallel retrieval pipelines on the same dataset to compare their downstream generation quality.
Dataset – 15 standalone technical images (CAD diagrams, inspection reports, test plots, material specifications, process flow charts) and five multi-page PDFs (assembly procedures, hot-fire test reports, engineering change notices, material certifications, non-conformance reports). These documents contain synthetic aerospace manufacturing data.
Pipeline A, Multimodal – Embed each image directly and each PDF page as a document image using Amazon Nova Multimodal Embeddings, then ingest into an Amazon Simple Storage Service (Amazon S3) Vectors index.
Pipeline B, Text-only baseline – Send each image and PDF page to Amazon Nova 2 Lite for OCR text extraction, embed the extracted text using Amazon Nova Multimodal Embeddings (text-only input), then ingest into a separate Amazon S3 Vectors index. The following prompt is used for the OCR step:
Note: OCR prompt for text extraction
"Extract ALL visible text from this image exactly as it appears. Include all numbers, labels, annotations, table contents, headers, and footnotes. Preserve the structure (tables, lists, sections) as much as possible. Return only the extracted text, no commentary."Evaluation – Run 26 manufacturing queries against the multimodal index for retrieval metrics (Recall@K, Mean Reciprocal Rank (MRR), NDCG@K). Then, for both pipelines, retrieve context and generate answers using Amazon Nova 2 Lite, scoring each answer against ground truth with a large language model (LLM) judge.
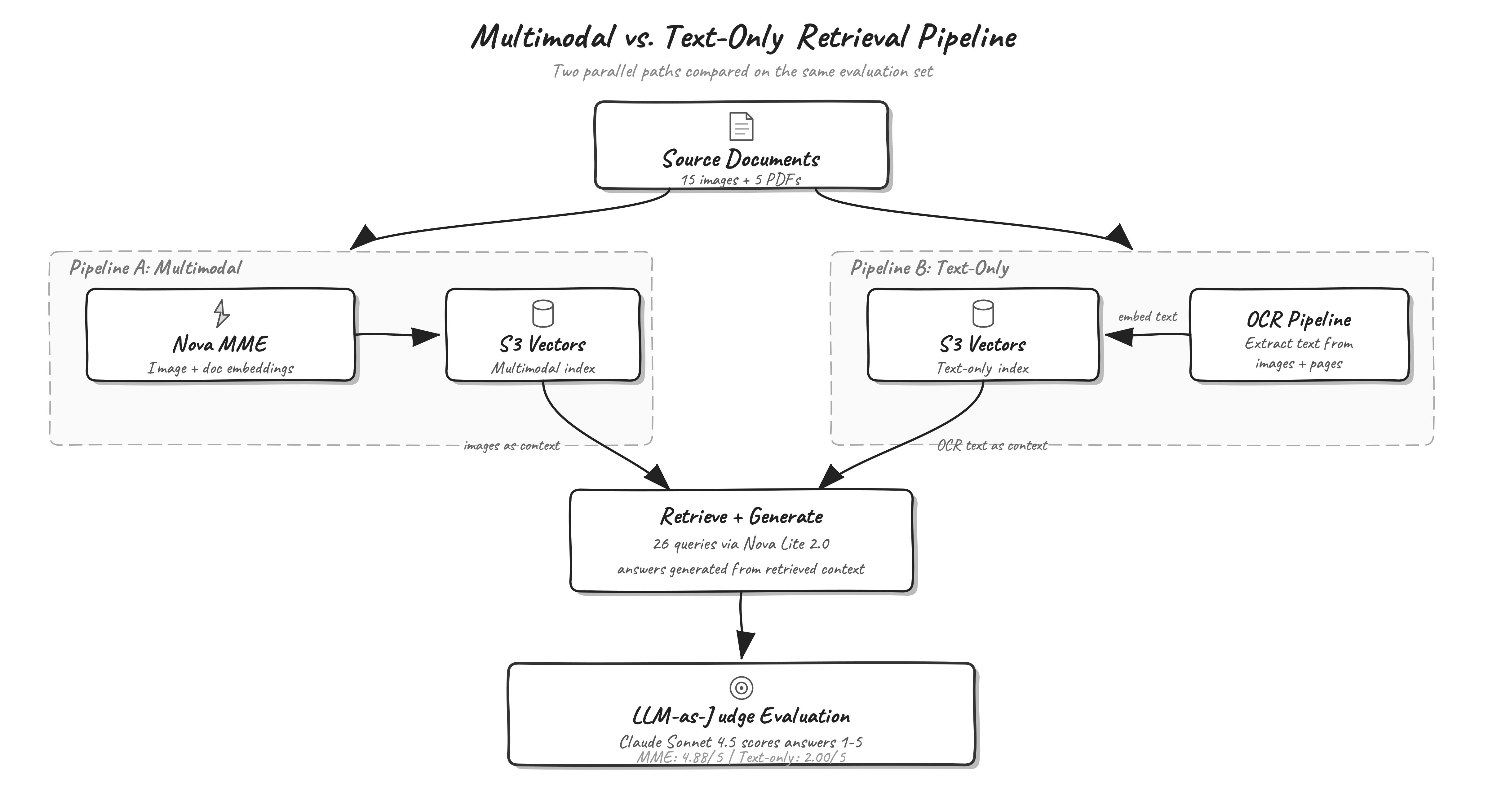
The following diagram shows the end-to-end pipeline architecture. Source documents flow through two parallel paths: Pipeline A embeds images directly with Amazon Nova Multimodal Embeddings, while Pipeline B extracts text through OCR before embedding. Both pipelines store vectors in Amazon S3 Vectors. At query time, retrieved context feeds into Amazon Nova 2 Lite for answer generation, and an LLM judge scores each answer against ground truth.
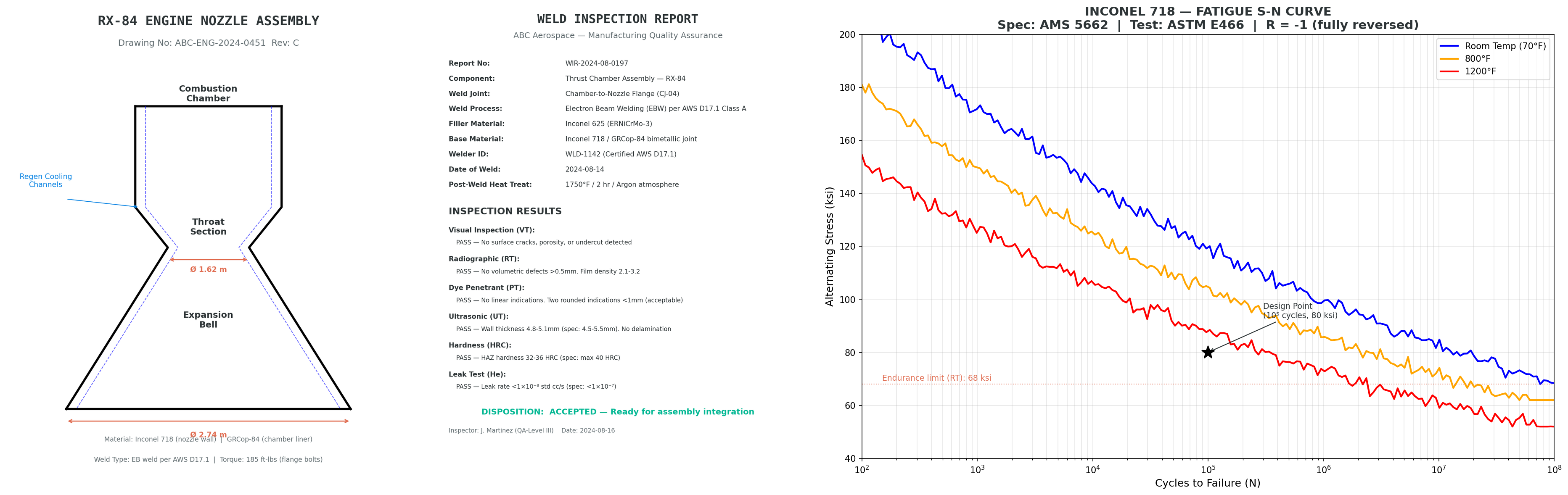
 The following figure shows three sample documents from the dataset. From left to right: a nozzle assembly CAD diagram, a weld inspection report, and an Inconel 718 fatigue S-N curve. Each document type presents information that’s difficult to capture through text extraction alone.
The following figure shows three sample documents from the dataset. From left to right: a nozzle assembly CAD diagram, a weld inspection report, and an Inconel 718 fatigue S-N curve. Each document type presents information that’s difficult to capture through text extraction alone.
Solution walkthrough
This section walks through the key implementation steps, from generating embeddings to building the vector index and running queries. The complete code is available in the companion notebook on GitHub.
Prerequisites
To follow along with this post, you need the following resources and access configured in your AWS account:
- An AWS account with access to Amazon Bedrock in
us-east-1 - Model access enabled for
amazon.nova-2-multimodal-embeddings-v1:0andus.amazon.nova-2-lite-v1:0 - An Amazon SageMaker AI notebook instance or local Python environment
- Python 3.10+ with
boto3,numpy,pandas,matplotlib,Pillow,pdf2image, andtqdm - IAM permissions for Amazon Bedrock
InvokeModel, Amazon S3, and Amazon S3 Vectors APIs
The sample code in this post is provided for educational purposes and hasn’t been reviewed for production use. Review and test it against your organization’s security requirements before deploying to production environments.
Generating multimodal embeddings
Generating an embedding for a manufacturing image requires a single InvokeModel call to Amazon Bedrock. The request specifies the image bytes, the desired embedding dimension, and the detail level. For standalone images like CAD diagrams, we use STANDARD_IMAGE. For PDF pages with mixed text and graphics, DOCUMENT_IMAGE produces better results because the model applies additional processing for tabular and chart content.
import base64, json, boto3
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
with open("dataset/nozzle_assembly_diagram.png", "rb") as f:
b64_data = base64.b64encode(f.read()).decode("utf-8")
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 1024,
"image": {
"format": "png",
"detailLevel": "STANDARD_IMAGE",
"source": {"bytes": b64_data},
},
},
}
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request_body),
accept="application/json",
contentType="application/json",
)
embedding = json.loads(response["body"].read())["embeddings"][0]["embedding"]
print(f"Embedding dimension: {len(embedding)}") # 1024Building the Amazon S3 Vectors index
Amazon S3 Vectors provides a managed vector storage and query layer. We create a vector bucket and an index configured for cosine similarity, then ingest embeddings in batches of 50.
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Create vector bucket and index
s3vectors.create_vector_bucket(vectorBucketName="manufacturing-vectors")
s3vectors.create_index(
vectorBucketName="manufacturing-vectors",
indexName="manufacturing-multimodal",
dataType="float32",
dimension=1024,
distanceMetric="cosine",
)
# Ingest a batch of embeddings with metadata
vectors = [
{
"key": "img-nozzle_assembly_diagram",
"data": {"float32": embedding},
"metadata": {
"source_file": "nozzle_assembly_diagram.png",
"type": "image",
},
}
]
s3vectors.put_vectors(
vectorBucketName="manufacturing-vectors",
indexName="manufacturing-multimodal",
vectors=vectors,
)Querying the index
At query time, we generate a text embedding with GENERIC_RETRIEVAL purpose, then call query_vectors to retrieve the most similar documents. The GENERIC_RETRIEVAL purpose tells the model to improve the embedding for query-document matching.
query = "What is the torque specification for the chamber flange bolts?"
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": 1024,
"text": {"truncationMode": "END", "value": query},
},
}
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID, body=json.dumps(request_body),
accept="application/json", contentType="application/json",
)
query_embedding = json.loads(response["body"].read())["embeddings"][0]["embedding"]
results = s3vectors.query_vectors(
vectorBucketName="manufacturing-vectors",
indexName="manufacturing-multimodal",
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True,
)
for v in results["vectors"]:
print(f" {v['key']} (distance: {v['distance']:.4f})")This query retrieves the torque specifications image and the flange bolt pattern diagram as the top results, both of which contain the answer. A text-only system would need the OCR extraction to have correctly captured the torque values from the engineering drawing, which is not always reliable for complex technical diagrams.
Evaluation methodology
We evaluated the system in two stages: retrieval quality (does the system find the right documents?) and generation quality (can a language model produce a correct answer from the retrieved context?). The evaluation dataset contains 26 queries derived from the aerospace manufacturing documents, each with ground truth relevant document IDs and a reference answer. The following subsections describe how each stage works.
Retrieval evaluation
For each query, we generate a text embedding with GENERIC_RETRIEVAL purpose, query the multimodal S3 Vectors index, and compare the returned documents against the ground truth relevant document IDs.
query = "What is the torque specification for the chamber flange bolts?"
query_embed = generate_text_embedding(
query, dim=1024, purpose="GENERIC_RETRIEVAL"
)
results = s3vectors.query_vectors(
vectorBucketName="manufacturing-vectors",
indexName="manufacturing-multimodal",
queryVector={"float32": query_embed},
topK=10,
returnDistance=True,
returnMetadata=True,
)
retrieved_ids = [v["key"] for v in results["vectors"]]We compute three metrics at K=3, 5, and 10: Recall@K (fraction of relevant documents found in the top K results), MRR (measuring how high the first relevant result appears), and NDCG@K (Normalized Discounted Cumulative Gain, giving more credit when relevant documents rank higher).
Generation evaluation with LLM-as-Judge
For generation evaluation, both pipelines retrieve the top five results for each query. The multimodal pipeline passes the retrieved images directly to Amazon Nova 2 Lite as multimodal context. The text-only pipeline passes the OCR-extracted text as string context.
def generate_answer_multimodal(query, retrieved_keys):
"""Pass retrieved images directly as multimodal context."""
content_blocks = []
for key in retrieved_keys[:5]:
img_path = vector_key_to_image_path(key)
with open(img_path, "rb") as f:
img_bytes = f.read()
content_blocks.append({"text": f"Retrieved document:"})
content_blocks.append({
"image": {"format": "png", "source": {"bytes": img_bytes}}
})
content_blocks.append({
"text": (
f"Review each image above carefully. "
f"Answer the following question concisely and precisely.\n\n"
f"Question: {query}\n\nAnswer:"
)
})
response = bedrock_runtime.converse(
modelId="us.amazon.nova-2-lite-v1:0",
messages=[{"role": "user", "content": content_blocks}],
inferenceConfig={"maxTokens": 500, "temperature": 0.1},
)
return response["output"]["message"]["content"][0]["text"]Each generated answer is scored against the ground truth reference using Anthropic Claude Sonnet 4.5 as an LLM judge. The judge receives the query, the ground truth answer, and the generated answer, then assigns a score from 1–5 with a brief explanation.
def judge_correctness(query, generated_answer, ground_truth):
prompt = (
"You are an evaluation judge. Score the generated answer compared "
"to the ground truth on a scale of 1-5.\n\n"
"1 = Completely wrong or irrelevant\n"
"2 = Partially relevant but mostly incorrect\n"
"3 = Somewhat correct but missing key information\n"
"4 = Mostly correct with minor omissions\n"
"5 = Fully correct and complete\n\n"
f"Question: {query}\n"
f"Ground Truth: {ground_truth}\n"
f"Generated Answer: {generated_answer}\n\n"
'Respond with ONLY a JSON object: '
'{"score": <1-5>, "reason": ""}'
)
response = bedrock_runtime.converse(
modelId="us.anthropic.claude-sonnet-4-5-20250929-v1:0",
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 200, "temperature": 0.0},
)
return response["output"]["message"]["content"][0]["text"] By evaluating retrieval and generation separately, you can pinpoint where each pipeline succeeds or fails. A pipeline might retrieve the correct document but still produce a wrong answer if the generator can’t extract the information from the provided context format.
Evaluation results
We evaluated the multimodal pipeline on 26 queries derived from the aerospace manufacturing dataset. Each query has one or more ground truth relevant document IDs. Retrieval metrics measure how well the system surfaces the correct documents at different values of K (the number of results returned).
Multimodal retrieval metrics
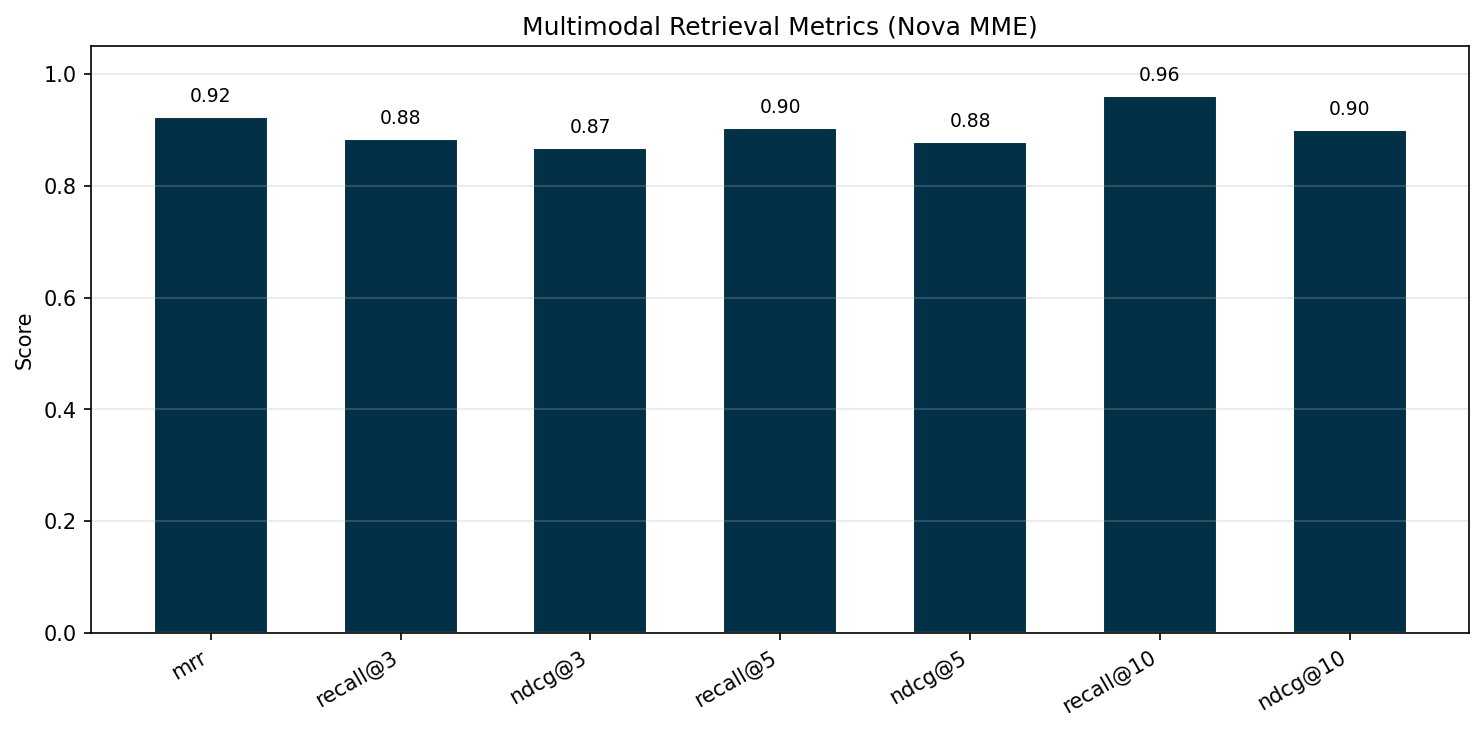
The multimodal pipeline achieves 90 percent recall at K=5, meaning it surfaces most relevant documents within the first five results, rising to 96 percent at K=10. An MRR of 0.92 indicates that the first relevant result typically appears in position 1. The two queries where recall falls below 1.0 at K=10 involve documents with relevant information split across a PDF and a standalone image, where one of the two relevant sources appears outside the top 10.
The following chart shows multimodal retrieval metrics at K=3, 5, and 10. MRR measures how high the first relevant result appears. Recall@K measures the fraction of relevant documents found in the top K results. NDCG@K measures ranking quality, giving more credit when relevant documents appear higher in the list.
Generation quality: text-only vs. multimodal
Retrieval metrics measure whether the system finds the right documents. Generation metrics measure whether a downstream language model can produce a correct answer from the retrieved context. We passed the top five retrieved results from each pipeline to Amazon Nova 2 Lite for answer generation, then scored each answer against ground truth using Anthropic Claude Sonnet 4.5 as an LLM judge on a 1–5 scale.
| Pipeline | Average judge score | Normalized (0–1) |
| Multimodal (MME) | 4.88 / 5 | 0.977 |
| Text-only (OCR) | 2.00 / 5 | 0.400 |
Table 2: Generation quality scored by LLM-as-Judge. The multimodal pipeline retrieves and passes images directly to the generator, while the text-only pipeline passes OCR-extracted text.
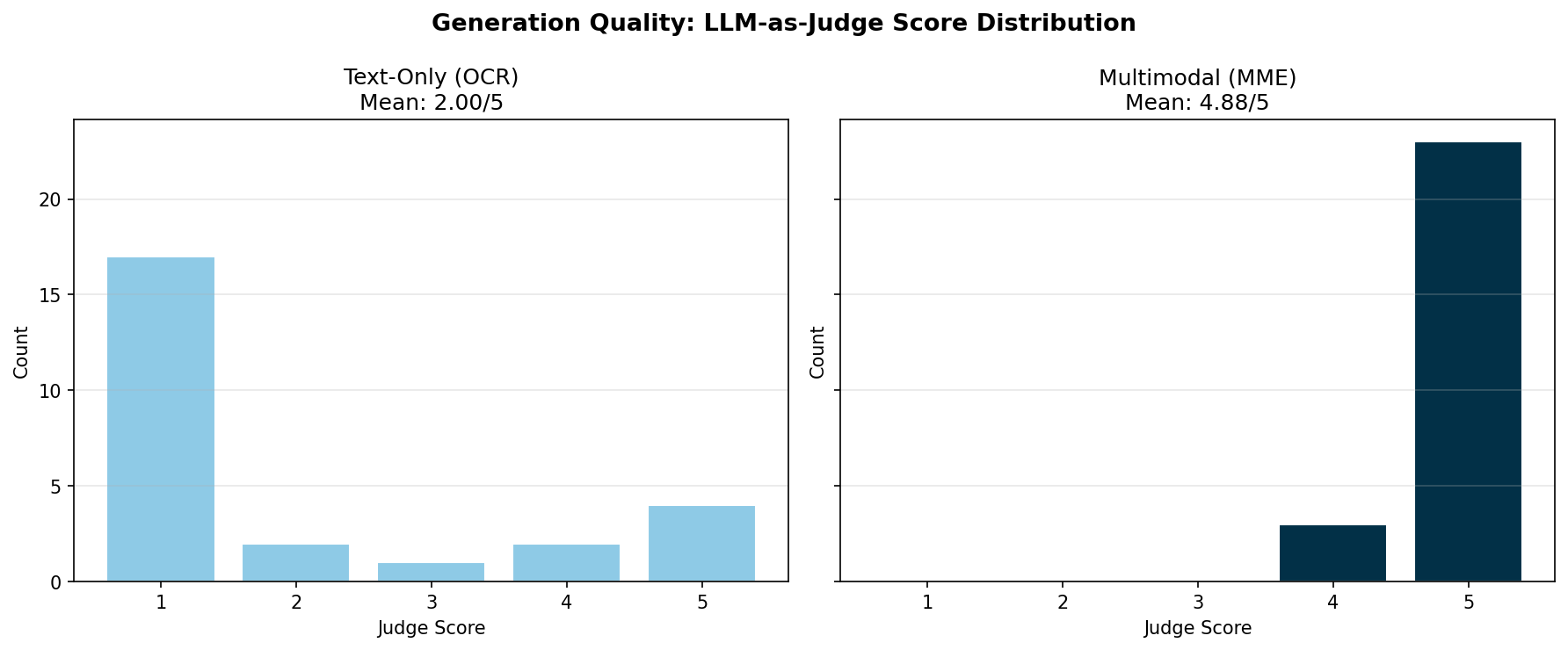
The multimodal pipeline scored better on 88 percent of queries (23 of 26), averaging 4.88 out of 5. The text-only pipeline averages 2.00, with 17 out of 26 queries scoring 1 (completely wrong). Visual content like thermal analysis contour plots, fatigue curves, process flow diagrams, and CAD callout labels showed the biggest improvement. For the few queries where both pipelines score well (4 or 5), the answer happens to appear as clearly formatted text that OCR captures reliably, such as material names or numeric values in tabular layouts.
The following chart shows the distribution of LLM judge scores (1–5) for both pipelines. The multimodal pipeline clusters at 5, while the text-only pipeline clusters at 1 for queries that require visual content understanding.
These results show that retrieval quality directly affects answer quality. When the system retrieves the right documents but passes only OCR text to the generator, it loses the visual information that the answer depends on. The multimodal pipeline avoids this lossy conversion by passing the original images to a multimodal generator.
Implementation complexity and cost
Beyond accuracy, the multimodal pipeline is more straightforward to build and cheaper to run. The text-only pipeline requires two model calls per document (one for OCR text extraction and one for text embedding) plus prompt engineering to handle diverse document layouts. The multimodal pipeline requires a single embedding call per document with no intermediate extraction step, reducing both implementation complexity and per-document ingestion cost by roughly half.
Cleanup
To avoid ongoing costs, delete the S3 Vectors indexes and bucket after completing the evaluation. The companion notebook on GitHub includes these cleanup commands (commented out for safety). The following snippet shows how to delete the indexes and vector bucket:
# Delete indexes
s3vectors.delete_index(vectorBucketName=S3_VECTOR_BUCKET, indexName=MME_INDEX)
s3vectors.delete_index(vectorBucketName=S3_VECTOR_BUCKET, indexName=TEXT_ONLY_INDEX)
# Delete vector bucket
s3vectors.delete_vector_bucket(vectorBucketName=S3_VECTOR_BUCKET)Amazon Bedrock embedding inference is priced per request with no persistent infrastructure to manage.
Conclusion
Multimodal embeddings close a retrieval gap that text-only systems can’t address for document collections with significant visual content. On the aerospace manufacturing dataset in this post, the multimodal pipeline achieved 90 percent recall at K=5 (96 percent at K=10) and near-perfect generation quality (4.88/5), while the text-only pipeline scored 2.00/5 because OCR couldn’t reliably capture information from engineering diagrams, thermal plots, and process flow charts.
With Amazon Nova Multimodal Embeddings on Amazon Bedrock, you can build this capability without managing embedding model infrastructure. Amazon S3 Vectors provides a vector storage and query layer that requires no cluster management or capacity planning.
To try this yourself, clone the companion code sample from GitHub and run it in Amazon SageMaker AI or your local environment. You can adapt the pipeline to your own manufacturing documents by replacing the sample dataset and queries. For more patterns and examples, see the following resources:
- Amazon Nova Multimodal Embeddings documentation
- Crossmodal search with Amazon Nova Multimodal Embeddings
- Amazon Nova Multimodal Embeddings technical report
- Amazon S3 Vectors documentation





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




