






















Rapid ML experimentation for enterprises with Amazon SageMaker AI and Comet
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.

This post was written with Sarah Ostermeier from Comet.
As enterprise organizations scale their machine learning (ML) initiatives from proof of concept to production, the complexity of managing experiments, tracking model lineage, and managing reproducibility grows exponentially. This is primarily because data scientists and ML engineers constantly explore different combinations of hyperparameters, model architectures, and dataset versions, generating massive amounts of metadata that must be tracked for reproducibility and compliance. As the ML model development scales across multiple teams and regulatory requirements intensify, tracking experiments becomes even more complex. With increasing AI regulations, particularly in the EU, organizations now require detailed audit trails of model training data, performance expectations, and development processes, making experiment tracking a business necessity and not just a best practice.
Amazon SageMaker AI provides the managed infrastructure enterprises need to scale ML workloads, handling compute provisioning, distributed training, and deployment without infrastructure overhead. However, teams still need robust experiment tracking, model comparison, and collaboration capabilities that go beyond basic logging.
Comet is a comprehensive ML experiment management platform that automatically tracks, compares, and optimizes ML experiments across the entire model lifecycle. It provides data scientists and ML engineers with powerful tools for experiment tracking, model monitoring, hyperparameter optimization, and collaborative model development. It also offers Opik, Comet’s open source platform for LLM observability and development.
Comet is available in SageMaker AI as a Partner AI App, as a fully managed experiment management capability, with enterprise-grade security, seamless workflow integration, and a straightforward procurement process through AWS Marketplace.
The combination addresses the needs of an enterprise ML workflow end-to-end, where SageMaker AI handles infrastructure and compute, and Comet provides the experiment management, model registry, and production monitoring capabilities that teams require for regulatory compliance and operational efficiency. In this post, we demonstrate a complete fraud detection workflow using SageMaker AI with Comet, showcasing reproducibility and audit-ready logging needed by enterprises today.
Enterprise-ready Comet on SageMaker AI
Before proceeding to setup instructions, organizations must identify their operating model and based on that, decide how Comet is going to be set up. We recommend implementing Comet using a federated operating model. In this architecture, Comet is centrally managed and hosted in a shared services account, and each data science team maintains fully autonomous environments. Each operating model comes with their own sets of benefits and limitations. For more information, refer to SageMaker Studio Administration Best Practices.
Let’s dive into the setup of Comet in SageMaker AI. Large enterprise generally have the following personas:
- Administrators – Responsible for setting up the common infrastructure services and environment for use case teams
- Users – ML practitioners from use case teams who use the environments set up by platform team to solve their business problems
In the following sections, we go through each persona’s journey.
Comet works well with both SageMaker AI and Amazon SageMaker. SageMaker AI provides the Amazon SageMaker Studio integrated development environment (IDE), and SageMaker provides the Amazon SageMaker Unified Studio IDE. For this post, we use SageMaker Studio.
Administrator journey
In this scenario, the administrator receives a request from a team working on a fraud detection use case to provision an ML environment with a fully managed training and experimentation setup. The administrator’s journey includes the following steps:
- Follow the prerequisites to set up Partner AI Apps. This sets up permissions for administrators, allowing Comet to assume a SageMaker AI execution role on behalf of the users and additional privileges for managing the Comet subscription through AWS Marketplace.
- On the SageMaker AI console, under Applications and IDEs in the navigation pane, choose Partner AI Apps, then choose View details for Comet.
The details are shown, including the contract pricing model for Comet and infrastructure tier estimated costs.
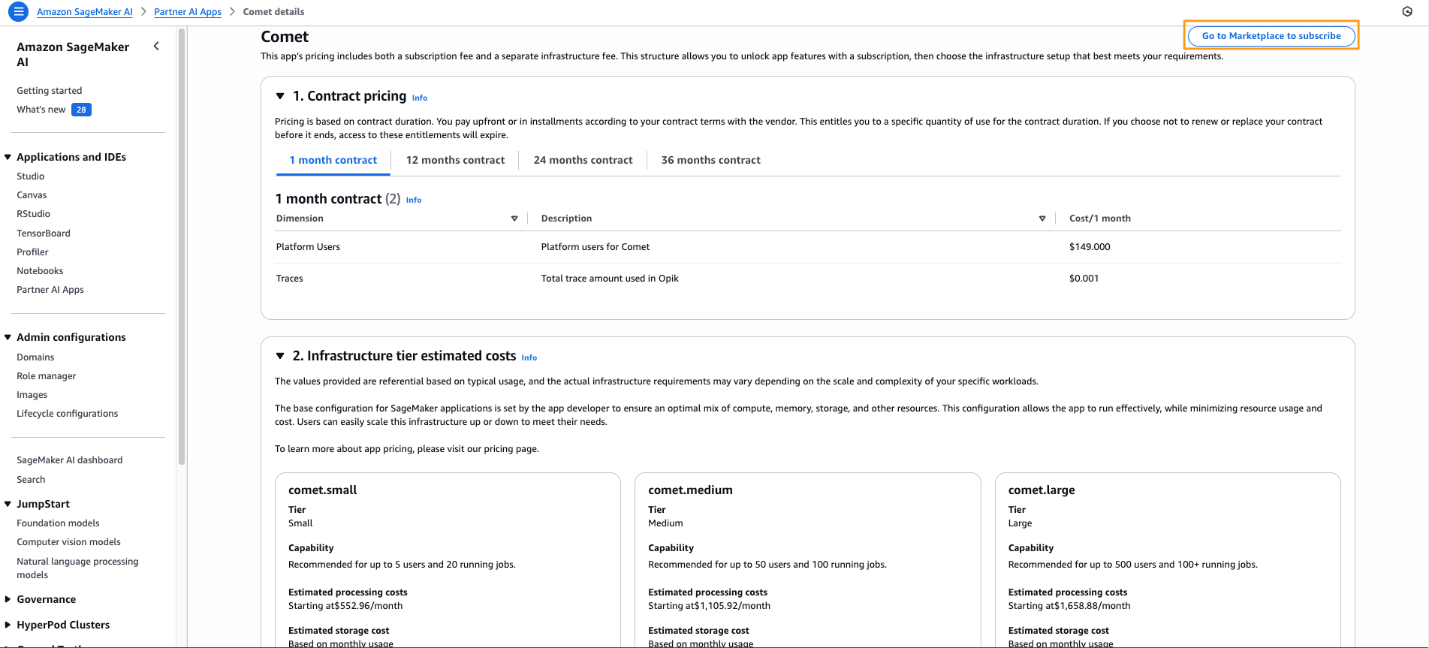
Comet provides different subscription options ranging from a 1-month to 36-month contract. With this contract, users can access Comet in SageMaker. Based on the number of users, the admin can review and analyze the appropriate instance size for the Comet dashboard server. Comet supports 5–500 users running more than 100 experiment jobs..
- Choose Go to Marketplace to subscribe to be redirected to the Comet listing on AWS Marketplace.
- Choose View purchase options.
- In the subscription form, provide the required details.
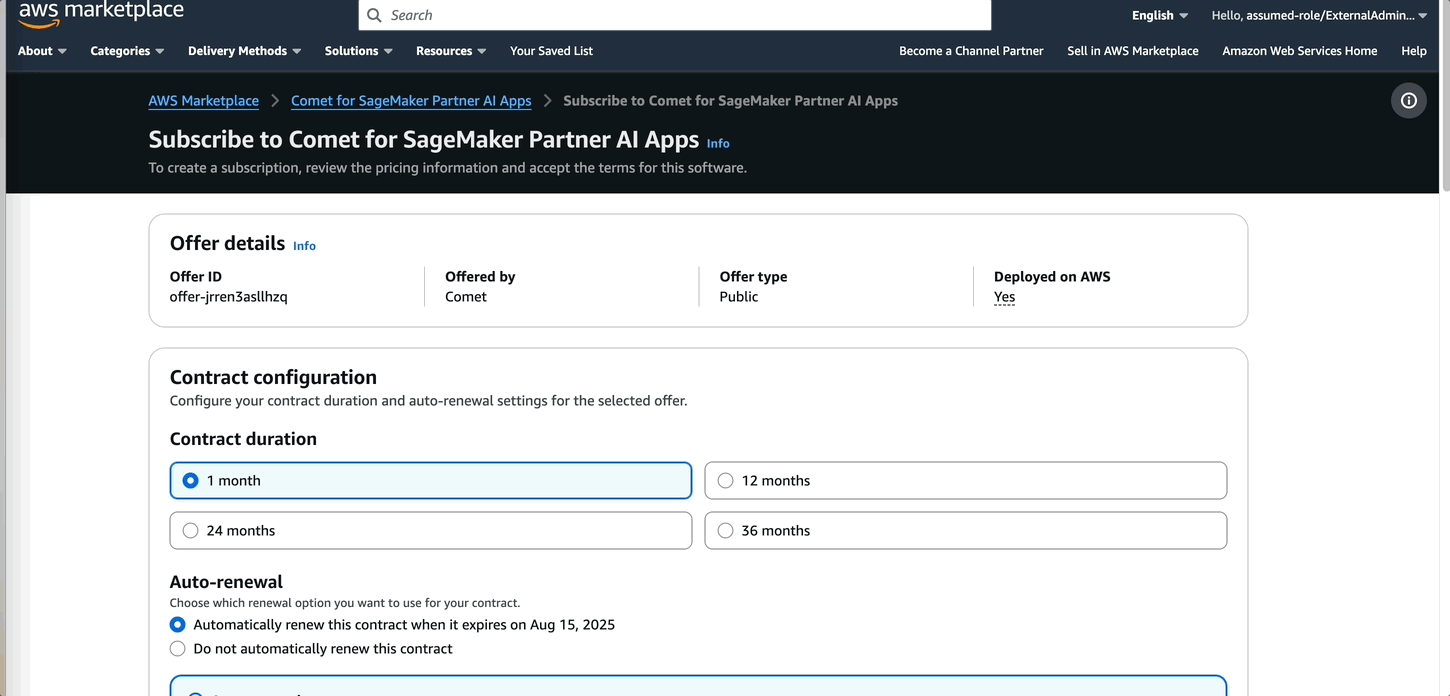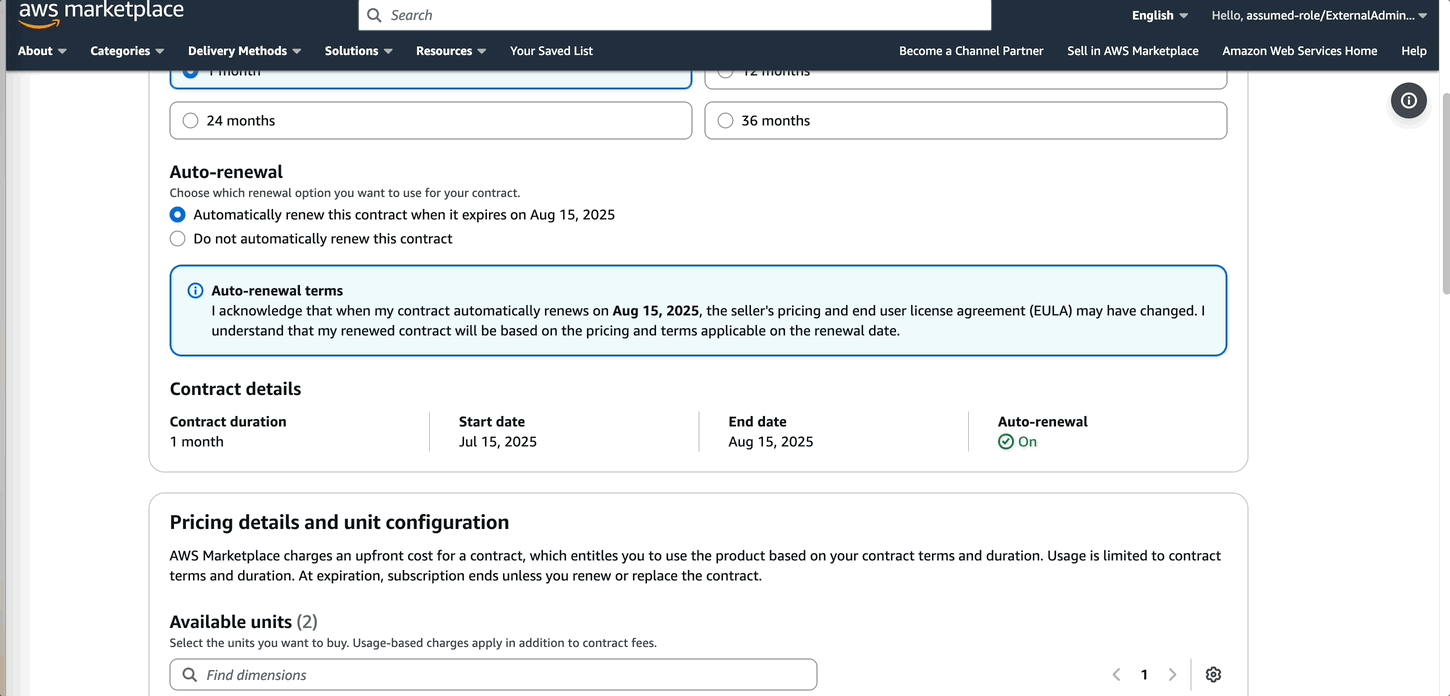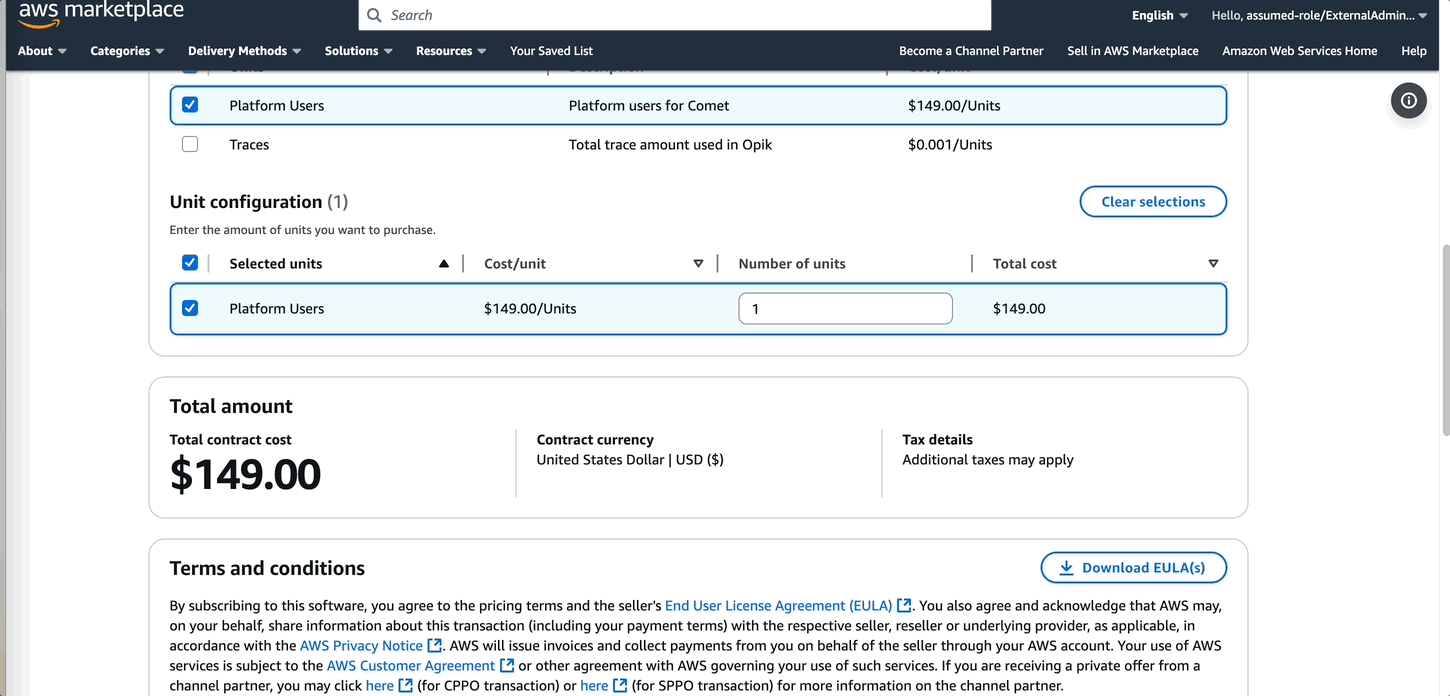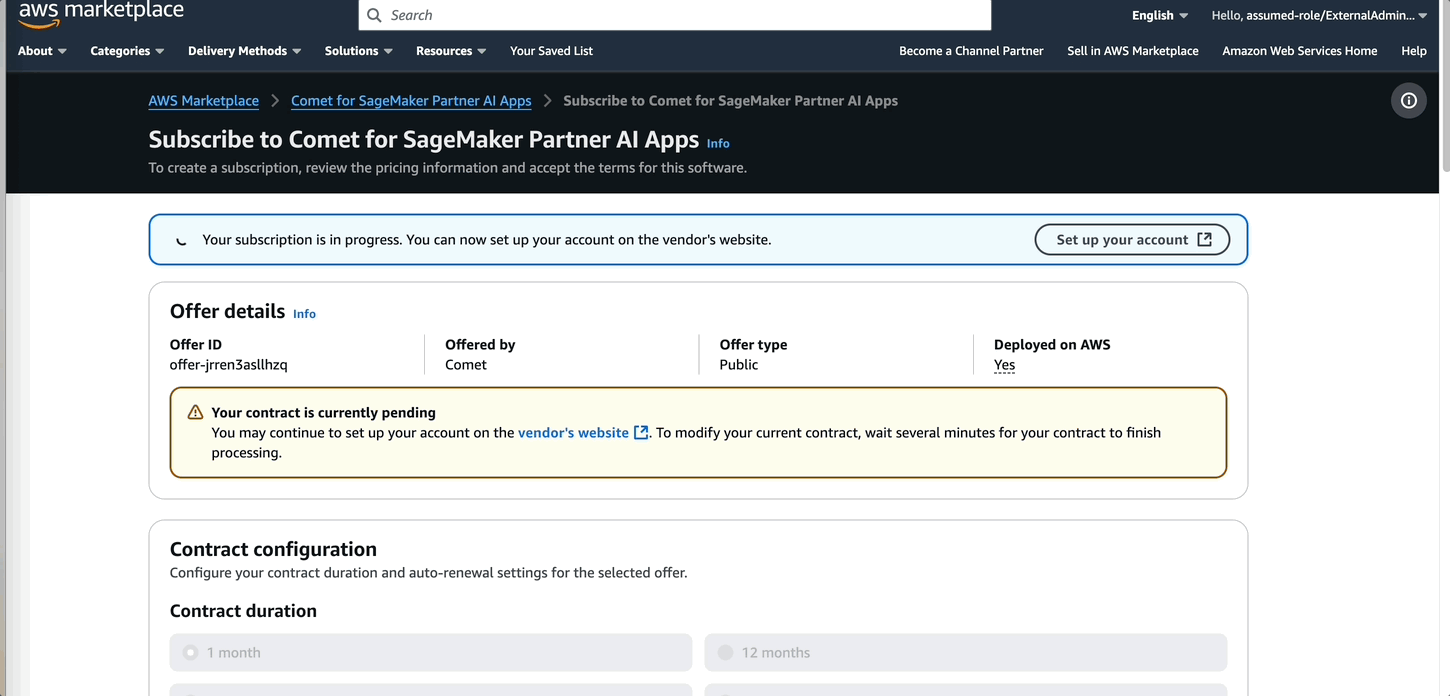
When the subscription is complete, the admin can start configuring Comet.
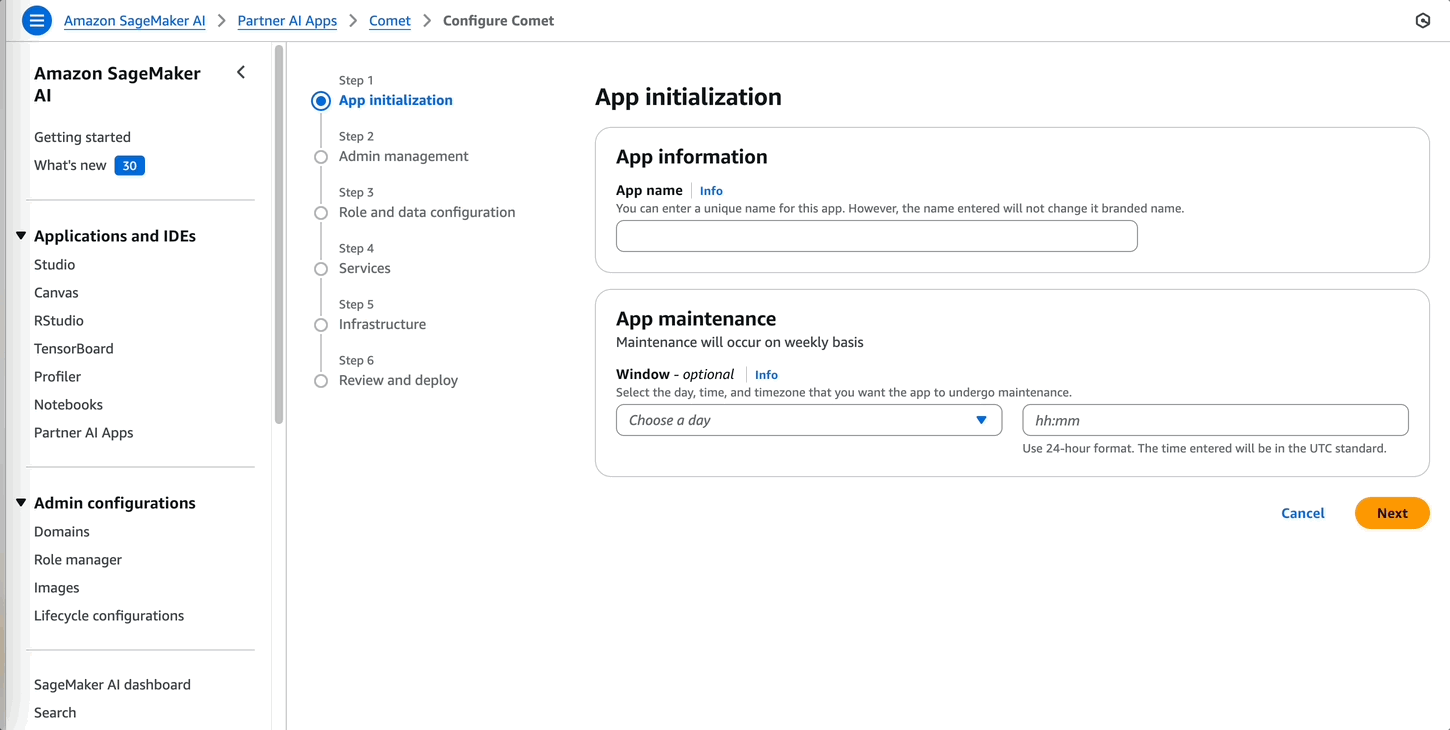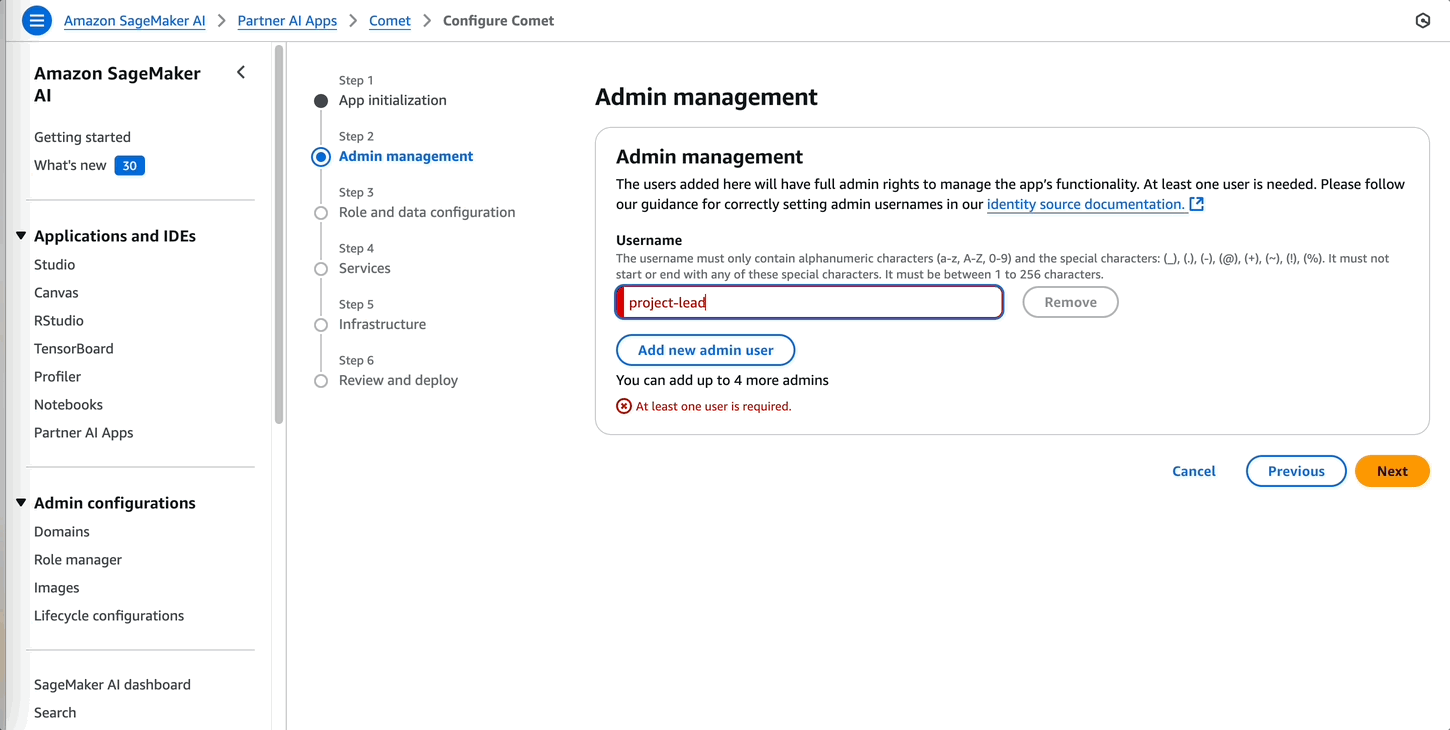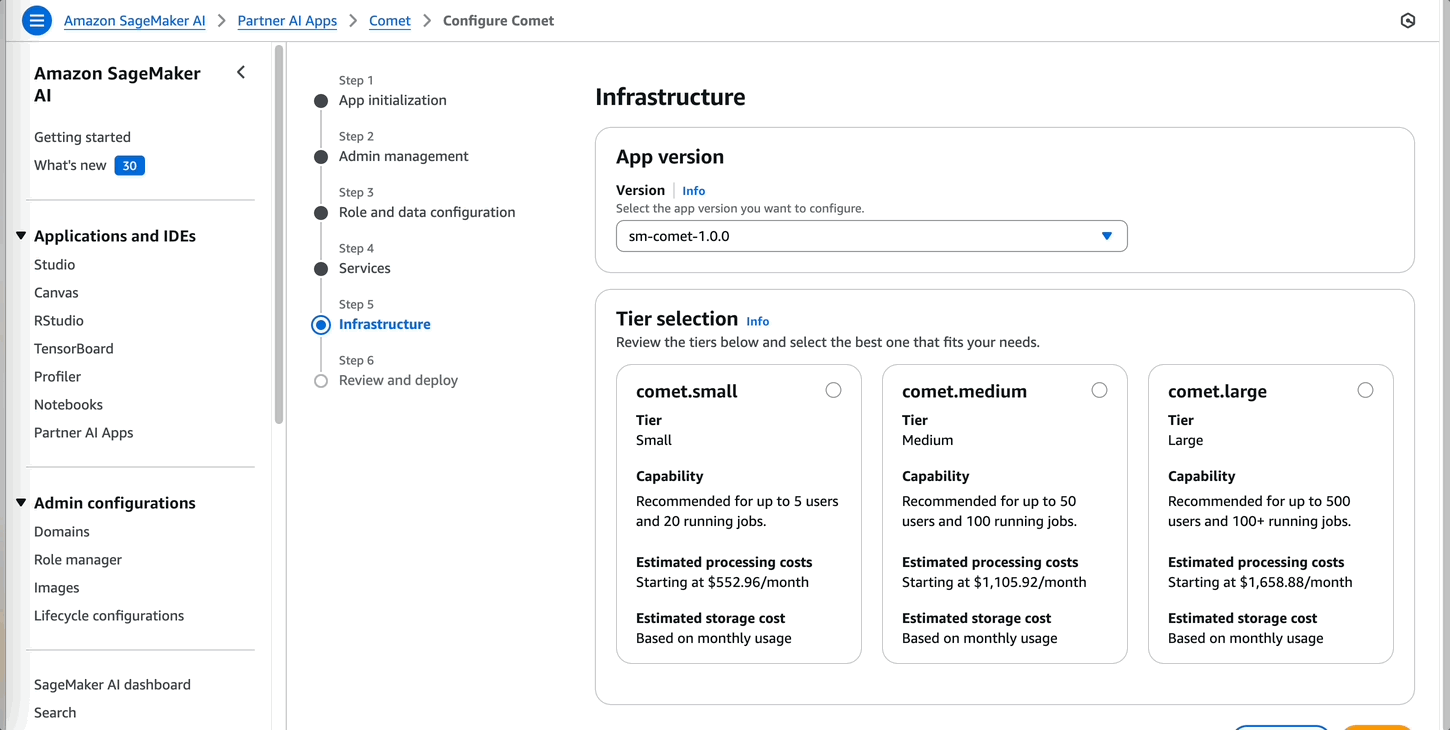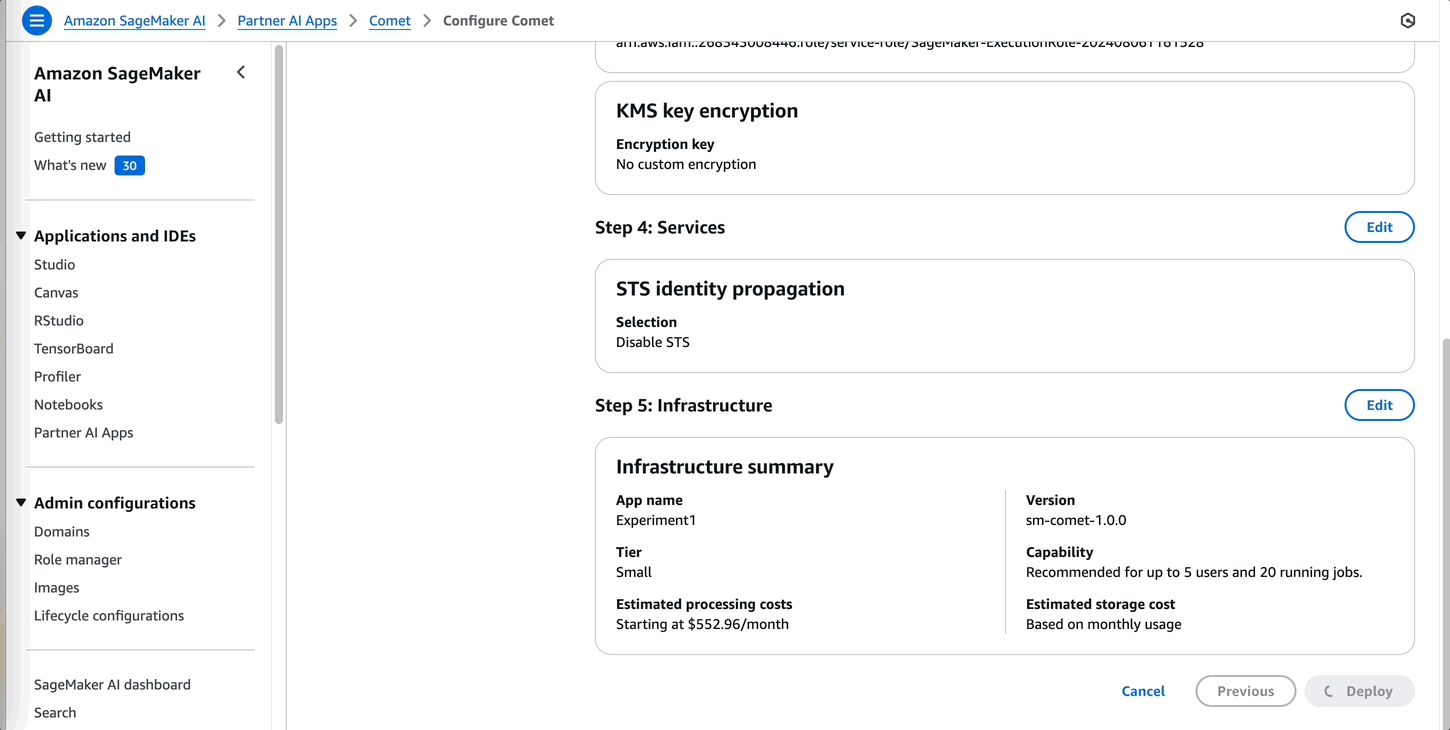
- While deploying Comet, add the project lead of the fraud detection use case team as an admin to manage the admin operations for the Comet dashboard.
It takes a few minutes for the Comet server to be deployed. For more details on this step, refer to Partner AI App provisioning.
- Set up a SageMaker AI domain following the steps in Use custom setup for Amazon SageMaker AI. As a best practice, provide a pre-signed domain URL for the use case team member to directly access the Comet UI without logging in to the SageMaker console.
- Add the team members to this domain and enable access to Comet while configuring the domain.
Now the SageMaker AI domain is ready for users to log in to and start working on the fraud detection use case.
User journey
Now let’s explore the journey of an ML practitioner from the fraud detection use case. The user completes the following steps:
- Log in to the SageMaker AI domain through the pre-signed URL.
You will be redirected to the SageMaker Studio IDE. Your user name and AWS Identity and Access Management (IAM) execution role are preconfigured by the admin.
- Create a JupyterLab Space following the JupyterLab user guide.
- You can start working on the fraud detection use case by spinning up a Jupyter notebook.
The admin has also set up required access to the data through an Amazon Simple Storage Service (Amazon S3) bucket.
- To access Comet APIs, install the comet_ml library and configure the required environment variables as described in Set up the Amazon SageMaker Partner AI Apps SDKs.
- To access the Comet UI, choose Partner AI Apps in the SageMaker Studio navigation pane and choose Open for Comet.

Now, let’s walk through the use case implementation.
Solution overview
This use case highlights common enterprise challenges: working with imbalanced datasets (in this example, only 0.17% of transactions are fraudulent), requiring multiple experiment iterations, and maintaining full reproducibility for regulatory compliance. To follow along, refer to the Comet documentation and Quickstart guide for additional setup and API details.
For this use case, we use the Credit Card Fraud Detection dataset. The dataset contains credit card transactions with binary labels representing fraudulent (1) or legitimate (0) transactions. In the following sections, we walk through some of the important sections of the implementation. The entire code of the implementation is available in the GitHub repository.
Prerequisites
As a prerequisite, configure the necessary imports and environment variables for the Comet and SageMaker integration:
Prepare the dataset
One of Comet’s key enterprise features is automatic dataset versioning and lineage tracking. This capability provides full auditability of what data was used to train each model, which is critical for regulatory compliance and reproducibility. Start by loading the dataset:
Start a Comet experiment
With the dataset artifact created, you can now start tracking the ML workflow. Creating a Comet experiment automatically begins capturing code, installed libraries, system metadata, and other contextual information in the background. You can log the dataset artifact created earlier in the experiment. See the following code:
Preprocess the data
The next steps are standard preprocessing steps, including removing duplicates, dropping unneeded columns, splitting into train/validation/test sets, and standardizing features using scikit-learn’s StandardScaler. We wrap the processing code in preprocess.py and run it as a SageMaker Processing job. See the following code:
After you submit the processing job, SageMaker AI launches the compute instances, processes and analyzes the input data, and releases the resources upon completion. The output of the processing job is stored in the S3 bucket specified.
Next, create a new version of the dataset artifact to track the processed data. Comet automatically versions artifacts with the same name, maintaining complete lineage from raw to processed data.
The Comet and SageMaker AI experiment workflow
Data scientists prefer rapid experimentation; therefore, we organized the workflow into reusable utility functions that can be called multiple times with different hyperparameters while maintaining consistent logging and evaluation across all runs. In this section, we showcase the utility functions along with a brief snippet of the code inside the function:
- train() – Spins up a SageMaker model training job using the SageMaker built-in XGBoost algorithm:
- log_training_job() – Captures the training metadata and metrics and links the model asset to the experiment for complete traceability:
- log_model_to_comet() – Links model artifacts to Comet, captures the training metadata, and links the model asset to the experiment for complete traceability:
- deploy_and_evaluate_model() – Performs model deployment and evaluation, and metric logging:
The complete prediction and evaluation code is available in the GitHub repository.
Run the experiments
Now you can run multiple experiments by calling the utility functions with different configurations and compare experiments to find the most optimal settings for the fraud detection use case.
For the first experiment, we establish a baseline using standard XGBoost hyperparameters:
While running a Comet experiment from a Jupyter notebook, we need to end the experiment to make sure everything is captured and persisted in the Comet server. See the following code: experiment_1.end()
When the baseline experiment is complete, you can run additional experiments with different hyperparameters. Check out the notebook to see the details of both experiments.
When the second experiment is complete, navigate to the Comet UI to compare these two experiment runs.
View Comet experiments in the UI
To access the UI, you can locate the URL in the SageMaker Studio IDE or by executing the code provided in the notebook: experiment_2.url
The following screenshot shows the Comet experiments UI. The experiment details are for illustration purposes only and do not represent a real-world fraud detection experiment.
This concludes the fraud detection experiment.
Clean up
For the experimentation part, SageMaker processing and training infrastructure is ephemeral in nature and shuts down automatically when the job is complete. However, you must still manually clean up a few resources to avoid unnecessary costs:
- Shut down the SageMaker JupyterLab Space after use. For instructions, refer to Idle shutdown.
- The Comet subscription renews based on the contract chosen. Cancel the contract when there is no further requirement to renew the Comet subscription.
Advantages of SageMaker and Comet integration
Having demonstrated the technical workflow, let’s examine the broader advantages this integration provides.
Streamlined model development
The Comet and SageMaker combination reduces the manual overhead of running ML experiments. While SageMaker handles infrastructure provisioning and scaling, Comet’s automatic logging captures hyperparameters, metrics, code, installed libraries, and system performance from your training jobs without additional configuration. This helps teams focus on model development rather than experiment bookkeeping.Comet’s visualization capabilities extend beyond basic metric plots. Built-in charts enable rapid experiment comparison, and custom Python panels support domain-specific analysis tools for debugging model behavior, optimizing hyperparameters, or creating specialized visualizations that standard tools can’t provide.
Enterprise collaboration and governance
For enterprise teams, the combination creates a mature platform for scaling ML projects across regulated environments. SageMaker provides consistent, secure ML environments, and Comet enables seamless collaboration with complete artifact and model lineage tracking. This helps avoid costly mistakes that occur when teams can’t recreate previous results.
Complete ML lifecycle integration
Unlike point solutions that only address training or monitoring, Comet paired with SageMaker supports your complete ML lifecycle. Models can be registered in Comet’s model registry with full version tracking and governance. SageMaker handles model deployment, and Comet maintains the lineage and approval workflows for model promotion. Comet’s production monitoring capabilities track model performance and data drift after deployment, creating a closed loop where production insights inform your next round of SageMaker experiments.
Conclusion
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.
To enhance your SageMaker workflows with comprehensive experiment management, deploy Comet directly in your SageMaker environment through the AWS Marketplace, and share your feedback in the comments.
For more information about the services and features discussed in this post, refer to the following resources:
- Set up Partner AI Apps
- Comet Quickstart
- GitHub notebook
- Comet Documentation
- Opik open source platform for LLM observability
About the authors
 Vikesh Pandey is a Principal GenAI/ML Specialist Solutions Architect at AWS, helping large financial institutions adopt and scale generative AI and ML workloads. He is the author of book “Generative AI for financial services.” He carries more than 15 years of experience building enterprise-grade applications on generative AI/ML and related technologies. In his spare time, he plays an unnamed sport with his son that lies somewhere between football and rugby.
Vikesh Pandey is a Principal GenAI/ML Specialist Solutions Architect at AWS, helping large financial institutions adopt and scale generative AI and ML workloads. He is the author of book “Generative AI for financial services.” He carries more than 15 years of experience building enterprise-grade applications on generative AI/ML and related technologies. In his spare time, he plays an unnamed sport with his son that lies somewhere between football and rugby.
 Naufal Mir is a Senior GenAI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning workloads to SageMaker. He previously worked at financial services institutes developing and operating systems at scale. Outside of work, he enjoys ultra endurance running and cycling.
Naufal Mir is a Senior GenAI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning workloads to SageMaker. He previously worked at financial services institutes developing and operating systems at scale. Outside of work, he enjoys ultra endurance running and cycling.
 Sarah Ostermeier is a Technical Product Marketing Manager at Comet. She specializes in bringing Comet’s GenAI and ML developer products to the engineers who need them through technical content, educational resources, and product messaging. She has previously worked as an ML engineer, data scientist, and customer success manager, helping customers implement and scale AI solutions. Outside of work she enjoys traveling off the beaten path, writing about AI, and reading science fiction.
Sarah Ostermeier is a Technical Product Marketing Manager at Comet. She specializes in bringing Comet’s GenAI and ML developer products to the engineers who need them through technical content, educational resources, and product messaging. She has previously worked as an ML engineer, data scientist, and customer success manager, helping customers implement and scale AI solutions. Outside of work she enjoys traveling off the beaten path, writing about AI, and reading science fiction.



![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)








