























Rocket Close transforms mortgage document processing with Amazon Bedrock and Amazon Textract
Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction.

This post is cowritten by Jeremy Little and Chris Day from Rocket Close.
Rocket Close, a Detroit-based title and appraisal management company within the Rocket Companies environment, has enhanced mortgage document processing by transforming a time-consuming manual process into an efficient automated solution. Processing approximately 2,000 abstract package files daily, with each file averaging 75 pages, the company faced a major operational challenge: manual extraction took on average 10 hours per package, creating considerable resource allocation burdens and workflow bottlenecks.
Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction. Amazon Bedrock is a fully managed service that provides a serverless and more secure way to build and scale generative AI applications. It offers a single API to access a choice of leading FMs from various AI companies. Designed to scale to over 500,000 documents annually, this transformation positions Rocket Close at the forefront of technological innovation in the mortgage industry, supporting faster customer service and sustainable business growth.
This post explores how this solution was developed and implemented, demonstrating how generative AI can transform document-intensive processes in the mortgage industry.
Challenges of manual processing at scale
Rocket Close processes a high volume of complex documentation as part of its title and appraisal management services. Rocket Close is dedicated to helping clients realize their dream of homeownership and financial freedom by making complex processes simpler through technology-driven solutions. By analyzing a wide range of data points, Rocket Close can quickly and accurately assess the risk associated with a loan, so they can make more informed lending decisions and get their clients the financing they need.Rocket Close faced a critical bottleneck that threatened their growth and profitability:
- Volume overload – 2,000 abstract packages daily, each averaging 75 pages
- Time-intensive workflow – 10 hours per package due to recent volume spikes, with an estimated 30 minutes of actual manual processing effort per package
- Financial impact – Considerable costs per file, with complex cases resulting in even higher expenses, totaling millions in annual processing costs
- Scalability limits – Manual processes couldn’t keep pace with growing demand
- Quality concerns – Human error and inconsistencies in data extraction
With approximately 1,000 hours of manual processing effort required daily, Rocket Close needed a solution that could maintain accuracy while dramatically reducing processing time.
Understanding abstract document packages
Abstract document packages are comprehensive collections of legal documents related to property ownership and transactions. These packages typically contain 50–100 pages of various document types bundled together, often with inconsistent formatting, varying quality, and complex structures. Each package requires thorough examination to extract critical information about property ownership, liens, mortgages, and legal status. The packages present unique challenges for automated processing due to their heterogeneous nature. Documents within a single package might include typed texts, layouts, handwritten notes, tables, forms, signatures, and stamps. Additionally, the ordering and presence of specific documents can vary significantly between packages, requiring sophisticated document segmentation and classification capabilities.
The solution handles over 60 different document classes that fall into several major categories:
- Mortgage documents – These include primary mortgage instruments such as mortgage agreements, deeds of trust, and security instruments. These documents establish the terms of loans secured by real property and contain critical information about loan amounts, interest rates, and repayment terms.
- Chain of title documents – This category encompasses various deed types (warranty deed, quitclaim deed, special warranty deed) that document the historical transfers of property ownership. These documents establish the legal chain of title and are essential for verifying clean ownership.
- Judgment documents – These include civil judgments, abstracts of judgment, and various notices of lien that might affect property ownership. These documents record legal claims against property owners that might impact title status.
- Tax documents – This category includes tax-related filings such as notice of federal tax lien and notice of state tax lien that represent potential claims against the property for unpaid taxes.
- Legal documents – These encompass various legal filings, including pending lawsuits, complaints for foreclosure, affidavits of heirship, and other court documents that might affect property ownership status.
Solution architecture
The AWS GenAIIC and Rocket Close teams collaboratively developed a solution that uses generative AI capabilities to automate the abstract package processing workflow. The following diagram shows the overall solution pipeline of the two-stage process using Amazon Textract for OCR processing and Amazon Bedrock for intelligent information extraction.
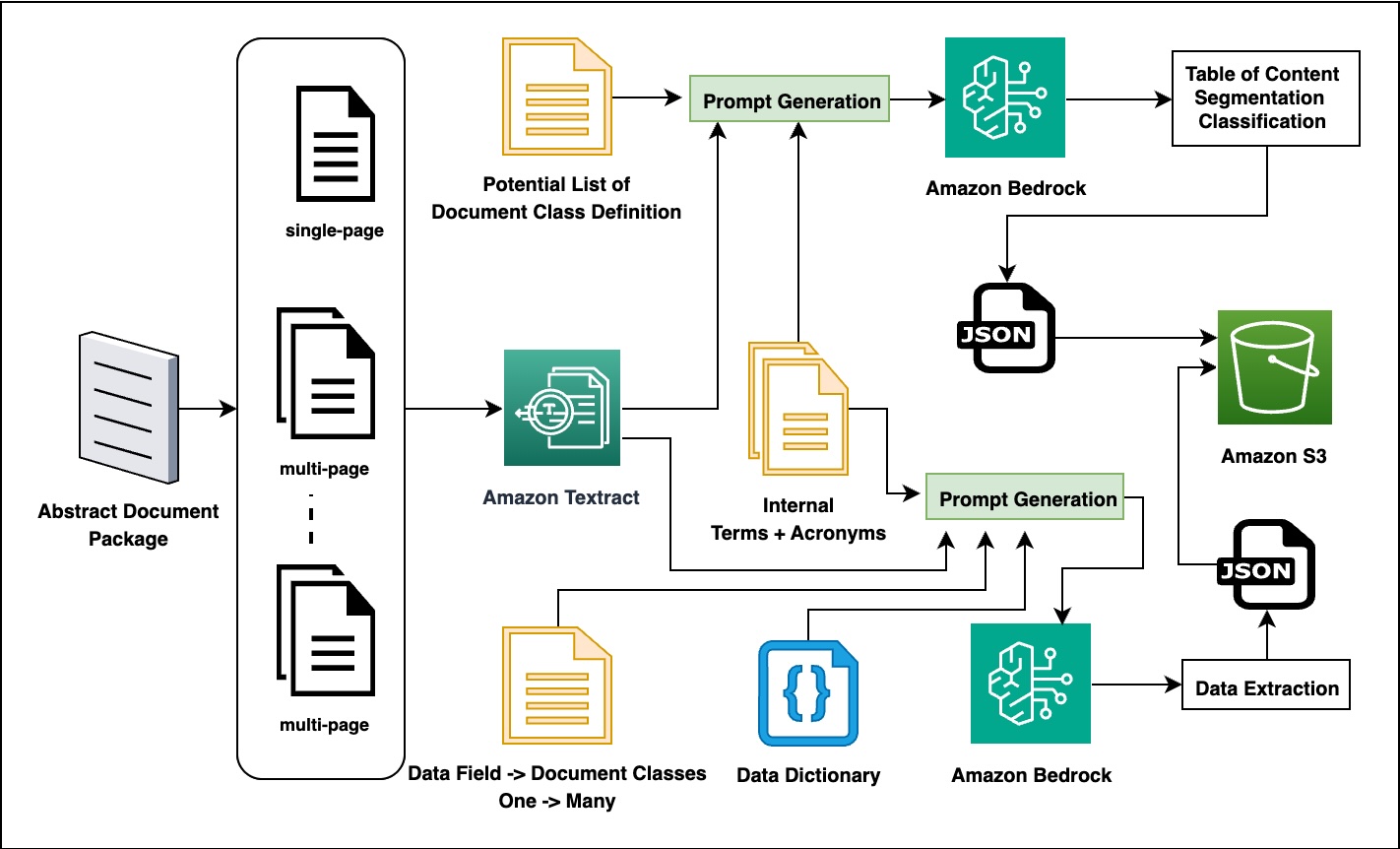
The first stage of the pipeline uses Amazon Textract to convert document images into machine-readable text. The system processes PDF documents through advanced OCR features that detect layout, tables, forms, and signatures while preserving the document’s structural hierarchy. The extracted content is then converted to markdown format, maintaining both human readability and machine processability, and stored in Amazon Simple Storage Service (Amazon S3) and locally for further processing.
The second stage uses Amazon Bedrock FMs to perform comprehensive document analysis and data extraction. The system first classifies and segments documents by analyzing their content and creating a table of contents, using domain-specific knowledge resources. Then, based on the document type, it extracts relevant data fields using specialized prompts combined with domain knowledge. The extracted information is converted into standardized JSON format for seamless integration with other systems.
The solution’s effectiveness relies on several innovative technical approaches:
- Advanced prompt engineering – The team developed specialized prompts that strategically guide the behavior of the large language model (LLM) for different document processing tasks. Document analysis prompts combine content with classification guidelines to facilitate accurate document segmentation, and information extraction prompts incorporate field definitions and domain knowledge to target specific data elements within documents. These carefully crafted prompts include illustrative examples and precise formatting instructions that enable the model to produce consistent, structured outputs across various document types and formats.
- Domain-specific knowledge integration – The system incorporates industry-specific knowledge to help enhance extraction accuracy through several complementary approaches. A data field to document class mapping makes sure the system targets the appropriate information in each document type, and comprehensive data dictionaries provide clear field definitions and expected formats for extraction. Mortgage industry glossaries help the system accurately interpret specialized terminology and acronyms common in the financial domain. This domain knowledge is dynamically incorporated into prompts during processing, significantly improving the system’s ability to extract accurate information from complex documents.
- Domain-aware evaluation framework – The project’s success hinged on a sophisticated evaluation system that used more than basic accuracy metrics. The solution includes a comprehensive framework with metrics tailored to different field types, facilitating accurate assessment of extraction quality across the mortgage domain.
The team implemented specialized approaches including exact and fuzzy string matching, numeric comparisons with configurable tolerance, and mortgage-specific metrics for state codes, deed types, transaction types, and document references. Domain-specific matching functions handle variations in specialized content, and field-type specific metrics apply appropriate comparison methods.
Results and impact
The proof of concept demonstrated strong results that exceeded expectations and validated the approach’s effectiveness for Rocket Close’s document processing needs.
The solution underwent rigorous performance testing across multiple evaluation rounds. The initial validation phase tested 28 random samples containing 655 data fields, achieving an overall accuracy of 90.53%. This early success demonstrated the viability of the approach and provided confidence to proceed with more extensive testing.
The second round focused on targeted testing with 52 samples that had 1:1 mapping to ground truth data, encompassing 2,249 data fields. The system achieved 91.28% accuracy during this phase, confirming consistent performance across different document types and validating the extraction methodology against verified baseline data. This phase was particularly important for establishing confidence in the Amazon Textract and custom processing pipeline’s ability to handle diverse document formats.
The final evaluation involved large-scale verification that processed 1,792 samples containing over 44,000 data fields, achieving an overall accuracy of 89.71%. This extensive testing validated the solution’s scalability and reliability across a representative sample of Rocket Close’s document volume, demonstrating that the AWS infrastructure maintains high accuracy even when processing large batches of diverse documents in parallel.
This solution, powered by AWS, helps deliver considerable business value across multiple dimensions. The automated system reduces processing time from 30 minutes per package to under 2 minutes, making processing 15 times faster. This acceleration enables faster customer service and higher throughput. From a financial perspective, the solution considerably reduces processing costs, delivering notable savings per file. With thousands of files processed daily (approximately 2,000 files), this represents potential annual savings at an enterprise scale. The automated system also delivers enhanced quality and consistency, maintaining 90% overall accuracy while reducing human error and standardizing output formats. This consistency improves downstream processes and decision-making, facilitating reliable data for business operations. Furthermore, the cloud-based architecture provides improved scalability by handling increasing document volumes without proportional staffing increases, supporting business growth without linear cost increases. It’s designed to scale elastically to handle over 500,000 documents annually, with the ability to automatically scale during peak processing periods, positioning Rocket Close for future expansion without infrastructure constraints.
Lessons learned
The proof of concept engagement revealed several valuable insights that can guide similar document processing implementations on AWS.
Prompt engineering proved critical, because carefully crafted prompts that incorporate domain knowledge significantly improve extraction accuracy. The team developed specialized prompts that combine document content with classification guidelines and domain-specific knowledge.
The two-stage pipeline architecture demonstrated strong effectiveness for this use case. Separating OCR and LLM processing allows for better optimization of each stage. Amazon Textract handles the complex task of extracting text from various document formats while preserving structural information, and Amazon Bedrock (using Anthropic’s Claude) focuses on understanding the content and extracting relevant information.
Domain-specific knowledge integration emerged as another key success factor. Incorporating mortgage-specific terminology and document understanding significantly improves results. The solution uses data dictionaries, glossaries, and document class definitions to help enhance extraction accuracy.
The engagement also highlighted evaluation complexity as an important consideration. Developing sophisticated, domain-aware evaluation metrics is essential for accurately measuring performance. The evaluation framework employs specialized metrics tailored to different field types, including state code matching, deed type matching, and transaction type matching.
Finally, scalability considerations proved crucial from the initial design phase. The solution architecture must be designed from the start to handle high volumes of documents efficiently. The two-stage pipeline approach with Amazon Textract and Amazon Bedrock helps provide the necessary scalability.
What’s next
Following the successful proof of concept, Rocket Close is positioned to move forward with production implementation.
The next phase involves moving from POC to production deployment with a containerized architecture that can handle enterprise-scale document processing. The team plans to establish continuous improvement processes by creating feedback loops to improve extraction accuracy over time. This iterative approach allows the system to learn from processing results and adapt to evolving document patterns.
An important consideration for long-term success is developing a model update strategy. Rocket Close will create a strategy for updating LLM models as new versions become available from Amazon Bedrock, making sure the solution benefits from the latest advancements in language model capabilities.
Finally, the proven approach will be expanded to additional workflows beyond the initial scope. Rocket Close plans to apply the solution to loan and mortgage payoff processing, purchase agreement processing, and title clearance documentation, extending the benefits of automated document processing across more of their operations.
Conclusion
The Rocket Close and AWS Generative AI Innovation Center collaboration demonstrates the transformative potential of generative AI in document-intensive industries. By automating the complex task of abstract package processing, Rocket Close has positioned itself to achieve major operational efficiencies, cost savings, and improved scalability. The solution’s strong 90% overall accuracy, combined with the dramatic reduction in processing time from hours to minutes, showcases how generative AI can solve real-world business challenges in the mortgage and title industry.
As Rocket Close moves toward production implementation, the foundation established during this proof of concept will enable continued innovation and process optimization across their document processing workflows.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




