![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









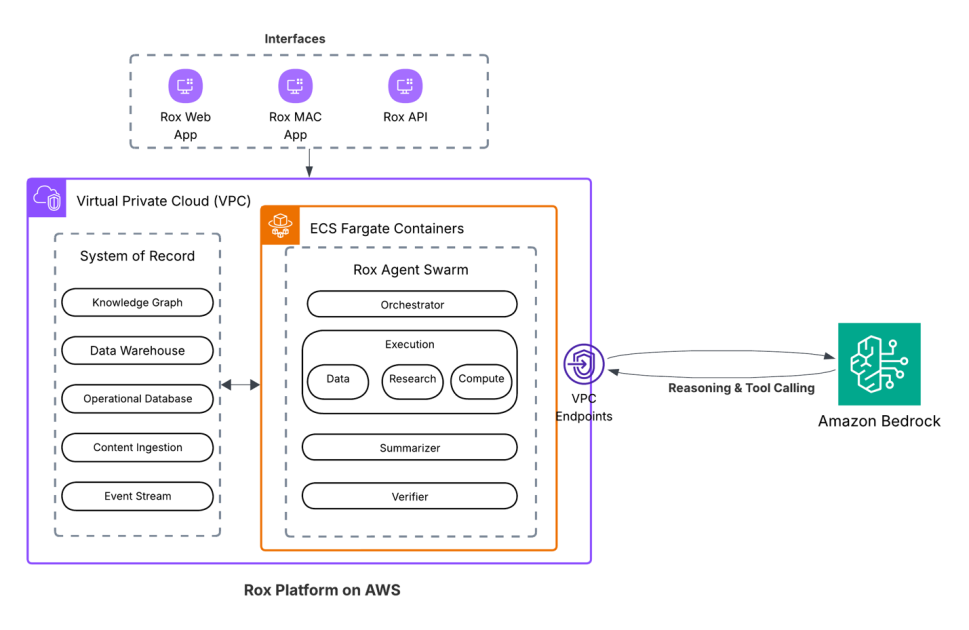
Get started with Amazon Titan Text Embeddings V2: A new state-of-the-art embeddings model on Amazon Bedrock
Embeddings are integral to various natural language processing (NLP) applications, and their quality is crucial for optimal performance. They are commonly used in knowledge bases to represent textual data as dense vectors, enabling efficient similarity search and retrieval. In Retrieval Augmented Generation (RAG), embeddings are used to retrieve relevant passages from a corpus to provide […]

Embeddings are integral to various natural language processing (NLP) applications, and their quality is crucial for optimal performance. They are commonly used in knowledge bases to represent textual data as dense vectors, enabling efficient similarity search and retrieval. In Retrieval Augmented Generation (RAG), embeddings are used to retrieve relevant passages from a corpus to provide context for language models to generate informed, knowledge-grounded responses. Embeddings also play a key role in personalization and recommendation systems by representing user preferences, item characteristics, and historical interactions as vectors, allowing calculation of similarities for personalized recommendations based on user behavior and item embeddings. As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
In September of 2023, we announced the launch of Amazon Titan Text Embeddings V1, a multilingual text embeddings model that converts text inputs like single words, phrases, or large documents into high-dimensional numerical vector representations. Since then, many of our customers have used the V1 model, which supported over 25 languages, with an input up to 8,192 tokens and outputs vector of 1,536 dimensions for high accuracy and low latency. The model was made available as a serverless offering via Amazon Bedrock, simplifying embedding generation and integration with downstream applications. We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app.
Today, we are happy to announce Amazon Titan Text Embeddings V2, our second-generation embeddings model for Amazon Bedrock. The new model is optimized for the most common use cases we see with many of our active customers, including RAG, multi-language, and code embedding use cases. The following table summarizes the key differences compared to V1.
| Feature | Amazon Titan Text Embeddings V1 | Amazon Titan Text Embeddings V2 |
| Output dimension support | 1536 | 256, 512, 1024 |
| Language support | 25+ | 100+ |
| Unit vector normalization support | No | Yes |
| Price per million tokens | $0.10 | $0.02 per 1 million tokens, or $0.00002 per 1,000 tokens |
With these new features, we expect many more customers choosing Amazon Titan Text Embeddings V2 to build common generative artificial intelligence (AI) applications. In this post, we discuss the benefits of the V2 model, how to conduct your own evaluation of the model, and how to migrate to using the new model.
Let’s dig in!
Benefits of Amazon Titan Text Embeddings V2
Amazon Titan Text Embeddings V2 is the second-generation embedding model for Amazon Bedrock, optimized for some of the most common customer use cases we have seen with our customers. Some of the key features include:
- Optimized for RAG solutions
- Flexible embedding sizes
- Improved multilingual support and code
Embeddings have become an integral part of various NLP applications, and their quality is crucial for achieving optimal performance.
The large language model (LLM) landscape is rapidly evolving, with leading providers offering increasingly powerful and versatile embedding models. Although incremental improvements in embedding quality may seem modest at the high level, the actual benefits can be significant for specific use cases. For example, in a recommendation system for a large ecommerce platform, a modest increase in recommendation accuracy could translate into significant additional revenue.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets. MTEB encompasses 8 different embedding tasks, covering a total of 58 datasets and 112 languages. In this benchmark, 33 different text embedding models were evaluated on the MTEB tasks. A key finding from the benchmark was that no single text embedding method emerged as the clear leader across all tasks and datasets. Each model exhibited strengths and weaknesses depending on the specific embedding task and data characteristics. This highlights the need for continued research into developing more versatile and robust text embedding techniques that can perform well across diverse use cases and language domains.
Although this is a useful benchmark, we caution our enterprise customers with the following considerations:
- Although the MTEB leaderboard is widely recognized, it provides only a partial assessment by focusing solely on accuracy metrics and overlooking crucial practical factors like inference latency and model capabilities. The leaderboard rankings combine and compare embedding models across different vector dimensions, making direct and fair model comparisons challenging.
- Additionally, the leaders on this accuracy-centric leaderboard change frequently as new models are continually introduced, providing a shifting and incomplete perspective on practical model performance trade-offs that real-world applications must consider beyond just accuracy numbers.
- Lastly, costs need to be weighed against the expected benefits and performance improvements in the specific use case. A small gain in accuracy may not justify the significant overhead and opportunity costs of transitioning embeddings models, especially in large-scale, business-critical applications. Enterprises should perform a rigorous cost-benefit analysis to make sure the projected performance uplift from an updated embeddings model provides sufficient return on investment (ROI) to offset the migration costs and operational disruption.
In summary, start with evaluating the benchmark scores, but don’t decide until you have done your own due diligence.
Benchmark results
The Amazon Titan Text Embeddings V2 model has the ability to output embeddings of various size. This implies that if you use a lower size, you’ll reduce your memory footprint, which will translate directly into cost savings. The default size is 1024, compared to V1, which is an 1536 output size, implying a direct cost reduction of approximately 33%, which translates into savings given the cost of a RAG solution has a major component in the form of a vector databases. In our internal testing, we found that using the 256-output token resulted in only about 3.24% accuracy loss while translating to a four times saving due to size reduction. Running our evaluation on MTEB datasets, we found Amazon Titan Text Embeddings V2 to perform competitively with scores like 57.5 on reranking tasks, for example. With the model trained on over 100 languages, it’s no surprise the model achieves scores like 55 on the MIRACL multilingual dataset and has an overall weighted average MTEB score of 60.37. Full MTEB scores are available on the MTEB leaderboard.
However, we strongly encourage you to run your own benchmarks with your own dataset to understand the operational metrics. A sample notebook showing how to run the benchmarks against the MTEB datasets is hosted here. The key steps involved are:
- Choose a representative set of data to embed and keywords to search.
- Use the Amazon Titan Text Embeddings V2 model to embed your data and keywords, adjusting the chunk size and overlap as needed.
- Carry out a similarity search using your preferred vector comparison method (such as Euclidean distance or cosine similarity).
Use Amazon Titan Text Embeddings V2 on Amazon Bedrock
The new Amazon Titan Text Embeddings V2 model is available through the fully managed, serverless experience on Amazon Bedrock. You can use the model through either the Amazon Bedrock REST API or the AWS SDK. The required parameters are the text that you want to generate the embeddings of and the modelID parameter, which represents the name of the Amazon Titan Text Embeddings model. Furthermore, now you can specify the output size of the vector, which is a significant feature of the V2 model.
Throughput has been a key requirement for running large ingestion workloads, and the Amazon Titan Text Embeddings model supports batching via Bedrock Batch to increase the throughput for your workloads. The following code is an example using the AWS SDK for Python (Boto3):
The full notebook is available at on the Github Repo.
With Amazon Titan Text Embeddings, you can input up to 8,192 tokens, allowing you to work with phrases or entire documents based on your use case. The model returns output vectors of a range of dimensions from 256–1024 without sacrificing accuracy, while also optimizing for cost storage and low latency. Typically, you will find larger content window models tuned for accuracy while sacrificing latency because they’re typically used in asynchronous workloads. However, with its larger content window, Amazon Titan Text Embeddings is able to achieve low latency, and with batching, it gives higher throughput for your workloads.
Run your own benchmarking
We always encourage our customers to perform their own benchmarking using their documents or the standard MTEB datasets and evaluation. For a sample of how to use the MTEB, see the GitHub repo. This notebook shows you how to load the dataset and set up evaluation for your specific use case (task) and run the benchmarking. If you run the benchmarking with your dataset, the typical steps involved are:
- Use the Amazon Titan Text Embeddings V2 model to embed your data and keywords, adjusting the chunk size and overlap as needed.
- Run similarity searches using your preferred distance metrics based on your choice of vector database.
A sample notebook showing how to use an in-memory database is available in the GitHub repo. This is a sample setup and should not be used for your production workloads where you would be connecting to robust vector database offerings like Amazon OpenSearch Serverless.
Migrate to Amazon Titan Text Embeddings V2
The cost and performance advantages provided by the V2 model are compelling reasons to consider reindexing your existing vector embeddings using V2. Let’s explore a few examples to illustrate the potential benefits, focusing solely on embedding costs.
Use case 1: High volume of searches
This first use case pertains to customers with a high volume of searches. The details are as follows:
- Scenario:
- 1 million documents, 100 million chunks, 1,000 average tokens per chunk
- 100,000 searches per day, 1,000 token size for search
- One-time cost:
- Number of tokens: 100,000 million
- Price per million tokens: $0.02
- Reindexing cost: 100,000 * $0.02 = $2,000
- Ongoing monthly savings (compared to V1):
- Tokens embedded per month: 30 * 100,000 * 1,000 = 3,000 million
- Savings per month (when migrating from V1 to V2): 3,000 * ($0.1 – $0.02) = $240
For this use case, the one-time reindexing cost of $2,000 will likely break even within 8–9 months through the ongoing monthly savings.
Use case 2: Ongoing indexing
This use case is for customers with ongoing indexing. The details are as follows:
- Scenario:
- 500,000 documents, 50 million chunks, average 1,000 tokens per chunk
- 10,000 (2%) new documents added per month
- 1,000 searches per day, 1,000 token size for search
- One-time cost:
- Number of tokens: 50,000 million
- Price per million tokens: $0.02
- Reindexing cost: 50,000 * $0.02 = $1,000
- Ongoing monthly savings (compared to V1):
- Tokens embedded per month for storage: 1,000 * 1,000 * 1,000 = 1,000 million
- Tokens embedded per month for search: 30 * 1,000 * 1,000 = 30 million
- Savings per month (vs. V1): 1,030 * ($0.1 – $0.02) = $82.4
For this use case, the one-time reindexing cost of $1,000 nets an estimated monthly savings of $82.4.
These calculations do not account for the additional savings due to the reduced storage size (up to four times) with V2. This could translate into further cost savings in terms of your vector database storage requirements. The extent of these savings will vary depending on your specific data storage needs.
Conclusion
In this post, we introduced the new Amazon Titan Text Embeddings V2 model, with superior performance across various use cases like retrieval, reranking, and multilingual tasks. You can potentially realize substantial cost savings and performance improvements by reindexing your vector embeddings using the V2 model. The specific benefits will vary based on factors such as the volume of data, search traffic, and storage requirements, but the examples discussed in this post illustrate the potential value proposition. Amazon Titan Text Embeddings V2 is available today in the us-east-1 and us-west-2 AWS Regions.
About the authors
 Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
 Pradeep Sridharan is a Senior Solutions Architect at AWS. He has years of experience in digital business transformation—designing and implementing solutions to drive market competitiveness and revenue growth across multiple sectors. He specializes in AI/ML, Data Analytics and Application Modernization and Migration. Pradeep is based in Arizona (US).
Pradeep Sridharan is a Senior Solutions Architect at AWS. He has years of experience in digital business transformation—designing and implementing solutions to drive market competitiveness and revenue growth across multiple sectors. He specializes in AI/ML, Data Analytics and Application Modernization and Migration. Pradeep is based in Arizona (US).
 Anuradha Durfee is a Senior Product Manager at AWS working on generative AI. She has spent the last five years working on natural language understanding and is motivated by enabling life-like conversations between humans and technology. Anuradha is based in Boston, MA.
Anuradha Durfee is a Senior Product Manager at AWS working on generative AI. She has spent the last five years working on natural language understanding and is motivated by enabling life-like conversations between humans and technology. Anuradha is based in Boston, MA.