














![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Revolutionize Customer Satisfaction with tailored reward models for your business on Amazon SageMaker
As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number of applications and services that are being built with generative artificial intelligence (AI) is also growing. With great power comes responsibility, and organizations want to make sure that these LLMs produce responses that align with […]

As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number of applications and services that are being built with generative artificial intelligence (AI) is also growing. With great power comes responsibility, and organizations want to make sure that these LLMs produce responses that align with their organizational values and provide the same unique experience they always intended for their end-customers.
Evaluating AI-generated responses presents challenges. This post discusses techniques to align them with company values and build a custom reward model using Amazon SageMaker. By doing so, you can provide customized customer experiences that uniquely reflect your organization’s brand identity and ethos.
Challenges with out-of-the-box LLMs
Out-of-the-box LLMs provide high accuracy, but often lack customization for an organization’s specific needs and end-users. Human feedback varies in subjectivity across organizations and customer segments. Collecting diverse, subjective human feedback to refine LLMs is time-consuming and unscalable.
This post showcases a reward modeling technique to efficiently customize LLMs for an organization by programmatically defining rewards functions that capture preferences for model behavior. We demonstrate an approach to deliver LLM results tailored to an organization without intensive, continual human judgement. The techniques aim to overcome customization and scalability challenges by encoding an organization’s subjective quality standards into a reward model that guides the LLM to generate preferable outputs.
Objective vs. subjective human feedback
Not all human feedback is the same. We can categorize human feedback into two types: objective and subjective.
Any human being who is asked to judge the color of the following boxes would confirm that the left one is a white box and right one is a black box. This is objective, and there are no changes to it whatsoever.

Determining whether an AI model’s output is “great” is inherently subjective. Consider the following color spectrum. If asked to describe the colors on the ends, people would provide varied, subjective responses based on their perceptions. One person’s white may be another’s gray.

This subjectivity poses a challenge for improving AI through human feedback. Unlike objective right/wrong feedback, subjective preferences are nuanced and personalized. The same output could elicit praise from one person and criticism from another. The key is acknowledging and accounting for the fundamental subjectivity of human preferences in AI training. Rather than seeking elusive objective truths, we must provide models exposure to the colorful diversity of human subjective judgment.
Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. One human’s riveting prose is another’s aimless drivel. So how should we refine these expansive language models when humans intrinsically disagree on the hallmarks of a “good” response?
The key is gathering feedback from a diverse crowd. With enough subjective viewpoints, patterns emerge on engaging discourse, logical coherence, and harmless content. Models can then be tuned based on broader human preferences. There is a general perception that reward models are often associated only with Reinforcement Learning from Human Feedback (RLHF). Reward modeling, in fact, goes beyond RLHF, and can be a powerful tool for aligning AI-generated responses with an organization’s specific values and brand identity.
Reward modeling
You can choose an LLM and have it generate numerous responses to diverse prompts, and then your human labelers will rank those responses. It’s important to have diversity in human labelers. Clear labeling guidelines are critical. Without explicit criteria, judgments can become arbitrary. Useful dimensions include coherence, relevance, creativity, factual correctness, logical consistency, and more. Human labelers put these responses into categories and label them favorite to least favorite, as shown in the following example. This example showcases how different humans perceive these possible responses from the LLM in terms of their most favorite (labeled as 1 in this case) and least favorite (labeled as 3 in this case). Each column is labeled 1, 2, or 3 from each human to signify their most preferred and least preferred response from the LLM.

By compiling these subjective ratings, patterns emerge on what resonates across readers. The aggregated human feedback essentially trains a separate reward model on writing qualities that appeal to people. This technique of distilling crowd perspectives into an AI reward function is called reward modeling. It provides a method to improve LLM output quality based on diverse subjective viewpoints.
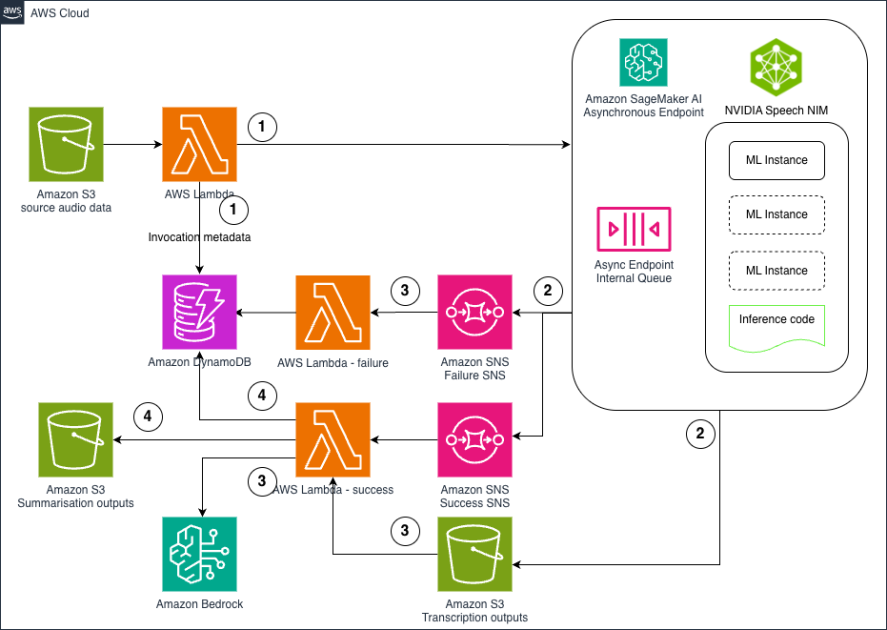
Solution overview
In this post, we detail how to train a reward model based on organization-specific human labeling feedback collected for various prompts tested on the base FM. The following diagram illustrates the solution architecture.

For more details, see the accompanying notebook.
Prerequisites
To successfully train a reward model, you need the following:
- A large dataset with prompts and ranked responses from human labelers that reflects your organizational and end-user needs. For this post, we store the dataset in an Amazon Simple Storage Service (Amazon S3) bucket.
- A small language model with a numerical head like OPT-2.7b, Falcon 7b (a decoder-only model of approximately 6 GB is good enough).
- A mechanism to run distributed training. For this post, we use SageMaker.
- An AWS Identity and Access Management (IAM) role associated with the Amazon SageMaker Studio user profile that has access to the S3 bucket holding the curated dataset. The standard SageMaker IAM role will suffice for this post. Refer to Amazon SageMaker Identity-Based Policy Examples for guidance on best practices and examples of identity-based policies for SageMaker.
- A SageMaker domain. You can quickly spin up a SageMaker domain and set up a single user for launching the SageMaker Studio notebook environment you’ll need to complete the model training. For instructions on setting up your environment, see Quick onboard to Amazon SageMaker domain.
Launch SageMaker Studio
Complete the following steps to launch SageMaker Studio:
- On the SageMaker console, choose Studio in the navigation pane.
- On the Studio landing page, select the domain and user profile for launching Studio.
- Choose Open Studio.
- To launch SageMaker Studio, choose Launch personal Studio.
Let’s see how to create a reward model locally in a SageMaker Studio notebook environment by using a pre-existing model from the Hugging Face model hub.
Prepare a human-labeled dataset and train a reward model
When doing reward modeling, getting feedback data from humans can be expensive. This is because reward modeling needs feedback from other human workers instead of only using data collected during regular system use. How well your reward model behaves depends on the quality and amount of feedback from humans.
We recommend using AWS-managed offerings such as Amazon SageMaker Ground Truth. It offers the most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the machine learning (ML) lifecycle to improve the accuracy and relevancy of models. You can complete a variety of human-in-the-loop tasks with SageMaker Ground Truth, from data generation and annotation to model review, customization, and evaluation, either through a self-service or AWS-managed offering.
For this post, we use the IMDB dataset to train a reward model that provides a higher score for text that humans have labeled as positive, and a lower score for negative text.
We prepare the dataset with the following code:
The following example shows a sample record from the prepared dataset, which includes references to rejected and chosen responses. We have also embedded the input ID and attention mask for the chosen and rejected responses.
Load the pre-trained model
In this case, we use the OPT-1.3b (Open Pre-trained Transformer Language Model) model in Amazon SageMaker JumpStart from Hugging Face. If you want to do all of the training locally on your notebook instead of distributed training, you need to use an instance with enough accelerator memory. We run the following training on a notebook running on ml.g4dn.xlarge instance type:
Define the custom trainer function
In the following code snippet, we create a custom trainer that calculates how well a model is performing on a task:
It compares the model’s results for two sets of input data: one set that was chosen and another set that was rejected. The trainer then uses these results to figure out how good the model is at distinguishing between the chosen and rejected data. This helps the trainer adjust the model to improve its performance on the task. The CustomTrainer class is used to create a specialized trainer that calculates the loss function for a specific task involving chosen and rejected input sequences. This custom trainer extends the functionality of the standard Trainer class provided by the transformers library, allowing for a tailored approach to handling model outputs and loss computation based on the specific requirements of the task. See the following code:
The TrainingArguments in the provided code snippet are used to configure various aspects of the training process for an ML model. Let’s break down the purpose of each parameter, and how they can influence the training outcome:
- output_dir – Specifies the directory where the trained model and associated files will be saved. This parameter helps organize and store the trained model for future use.
- overwrite_output_dir – Determines whether to overwrite the output directory if it already exists. Setting this to True allows for reusing the same directory without manual deletion.
- do_train – Indicates whether to perform training. If set to True, the model will be trained using the provided training dataset.
- do_eval and do_predict – Control whether to perform evaluation and prediction tasks, respectively. In this case, both are set to False, meaning only training will be conducted.
- evaluation_strategy – Defines when evaluation should be performed during training. Setting it to “no” means evaluation will not be done during training.
- learning_rate – Specifies the learning rate for the optimizer, influencing how quickly or slowly the model learns from the data.
- num_train_epochs – Sets the number of times the model will go through the entire training dataset during training. One epoch means one complete pass through all training samples.
- per_device_train_batch_size – Determines how many samples are processed in each batch during training on each device (for example, GPU). A smaller batch size can lead to slower but more stable training.
- gradient_accumulation_steps – Controls how often gradients are accumulated before updating the model’s parameters. This can help stabilize training with large batch sizes.
- remove_unused_columns – Specifies whether unused columns in the dataset should be removed before processing, optimizing memory usage.
By configuring these parameters in the TrainingArguments, you can influence various aspects of the training process, such as model performance, convergence speed, memory usage, and overall training outcome based on your specific requirements and constraints.
When you run this code, it trains the reward model based on the numerical representation of subjective feedback you gathered from the human labelers. A trained reward model will give a higher score to LLM responses that humans are more likely to prefer.
Use the reward model to evaluate the base LLM
You can now feed the response from your LLM to this reward model, and the numerical score produced as output informs you of how well the response from the LLM is aligning to the subjective organization preferences that were embedded on the reward model. The following diagram illustrates this process. You can use this number as the threshold for deciding whether or not the response from the LLM can be shared with the end-user.

For example, let’s say we created an reward model to avoiding toxic, harmful, or inappropriate content. If a chatbot powered by an LLM produces a response, the reward model can then score the chatbot’s responses. Responses with scores above a pre-determined threshold are deemed acceptable to share with users. Scores below the threshold mean the content should be blocked. This lets us automatically filter chatbot content that doesn’t meet standards we want to enforce. To explore more, see the accompanying notebook.
Clean up
To avoid incurring future charges, delete all the resources that you created. Delete the deployed SageMaker models, if any, and stop the SageMaker Studio notebook you launched for this exercise.
Conclusion
In this post, we showed how to train a reward model that predicts a human preference score from the LLM’s response. This is done by generating several outputs for each prompt with the LLM, then asking human annotators to rank or score the responses to each prompt. The reward model is then trained to predict the human preference score from the LLM’s response. After the reward model is trained, you can use the reward model to evaluate the LLM’s responses against your subjective organizational standards.
As an organization evolves, the reward functions must evolve alongside changing organizational values and user expectations. What defines a “great” AI output is subjective and transforming. Organizations need flexible ML pipelines that continually retrain reward models with updated rewards reflecting latest priorities and needs. This space is continuously evolving: direct preference-based policy optimization, tool-augmented reward modeling, and example-based control are other popular alternative techniques to align AI systems with human values and goals.
We invite you to take the next step in customizing your AI solutions by engaging with the diverse and subjective perspectives of human feedback. Embrace the power of reward modeling to ensure your AI systems resonate with your brand identity and deliver the exceptional experiences your customers deserve. Start refining your AI models today with Amazon SageMaker and join the vanguard of businesses setting new standards in personalized customer interactions. If you have any questions or feedback, please leave them in the comments section.
About the Author
 Dinesh Kumar Subramani is a Senior Solutions Architect based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning, and is member of technical field community with in Amazon. Dinesh works closely with UK Central Government customers to solve their problems using AWS services. Outside of work, Dinesh enjoys spending quality time with his family, playing chess, and exploring a diverse range of music.
Dinesh Kumar Subramani is a Senior Solutions Architect based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning, and is member of technical field community with in Amazon. Dinesh works closely with UK Central Government customers to solve their problems using AWS services. Outside of work, Dinesh enjoys spending quality time with his family, playing chess, and exploring a diverse range of music.








