












![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Build a conversational chatbot using different LLMs within single interface – Part 1
With the advent of generative artificial intelligence (AI), foundation models (FMs) can generate content such as answering questions, summarizing text, and providing highlights from the sourced document. However, for model selection, there is a wide choice from model providers, like Amazon, Anthropic, AI21 Labs, Cohere, and Meta, coupled with discrete real-world data formats in PDF, […]

With the advent of generative artificial intelligence (AI), foundation models (FMs) can generate content such as answering questions, summarizing text, and providing highlights from the sourced document. However, for model selection, there is a wide choice from model providers, like Amazon, Anthropic, AI21 Labs, Cohere, and Meta, coupled with discrete real-world data formats in PDF, Word, text, CSV, image, audio, or video.
Amazon Bedrock is a fully managed service that makes it straightforward to build and scale generative AI applications. Amazon Bedrock offers a choice of high-performing FMs from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, through a single API. It enables you to privately customize FMs with your data using techniques such as fine-tuning, prompt engineering, and Retrieval Augmented Generation (RAG), and build agents that run tasks using your enterprise systems and data sources while complying with security and privacy requirements.
In this post, we show you a solution for building a single interface conversational chatbot that allows end-users to choose between different large language models (LLMs) and inference parameters for varied input data formats. The solution uses Amazon Bedrock to create choice and flexibility to improve the user experience and compare the model outputs from different options.
The entire code base is available in GitHub, along with an AWS CloudFormation template.
What is RAG
Retrieval Augmented Generation (RAG) can enhance the generation process by using the benefits of retrieval, enabling a natural language generation model to produce more informed and contextually appropriate responses. By incorporating relevant information from retrieval into the generation process, RAG aims to improve the accuracy, coherence, and informativeness of the generated content.
Implementing an effective RAG system requires several key components working in harmony:
- Foundation models – The foundation of a RAG architecture is a pre-trained language model that handles text generation. Amazon Bedrock encompasses models from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, and Amazon that possess strong language comprehension and synthesis abilities to engage in conversational dialogue.
- Vector store – At the heart of the retrieval functionality is a vector store database persisting document embeddings for similarity search. This allows rapid identification of relevant contextual information. AWS offers many services for your vector database requirements:
- Retriever – The retriever module uses the vector store to efficiently find pertinent documents and passages to augment prompts.
- Embedder – To populate the vector store, an embedding model encodes source documents into vector representations consumable by the retriever. Models like Amazon Titan Embeddings G1 – Text v1.2 are ideal for this text-to-vector abstraction.
- Document ingestion – Robust pipelines ingest, preprocess, and tokenize source documents, chunking them into manageable passages for embedding and efficient lookup. For this solution, we use the LangChain framework for document preprocessing. By orchestrating these core components using LangChain, RAG systems empower language models to access vast knowledge for grounded generation.
We have fully managed support for our end-to-end RAG workflow using Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you can give FMs and agents contextual information from your company’s private data sources for RAG to deliver more relevant, accurate, and customized responses.
To equip FMs with up-to-date and proprietary information, organizations use RAG to fetch data from company data sources and enrich the prompt to provide more relevant and accurate responses. Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows. Session context management is built in, so your app can readily support multi-turn conversations.
Solution overview
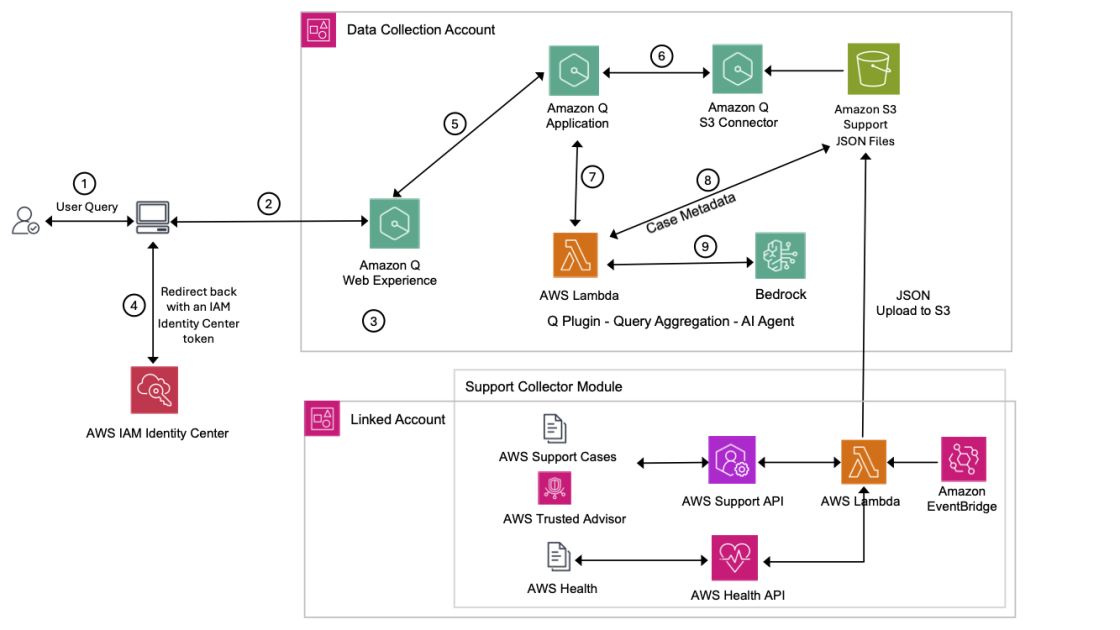
This chatbot is built using RAG, enabling it to provide versatile conversational abilities. The following figure illustrates a sample UI of the Q&A interface using Streamlit and the workflow.

This post provides a single UI with multiple choices for the following capabilities:
- Leading FMs available through Amazon Bedrock
- Inference parameters for each of these models
- Source data input formats for RAG:
- Text (PDF, CSV, Word)
- Website link
- YouTube video
- Audio
- Scanned image
- PowerPoint
- RAG operation using the LLM, inference parameter, and sources:
- Q&A
- Summary: summarize, get highlights, extract text
We have used one of LangChain’s many document loaders, YouTubeLoader. The from_you_tube_url function helps extract transcripts and metadata from the YouTube video.
The documents contain two attributes:
page_contentwith the transcriptsmetadatawith basic information about the video
Text is extracted from the transcript and using Langchain TextLoader, the document is split and chunked, and embeddings are created, which are then stored in the vector store.
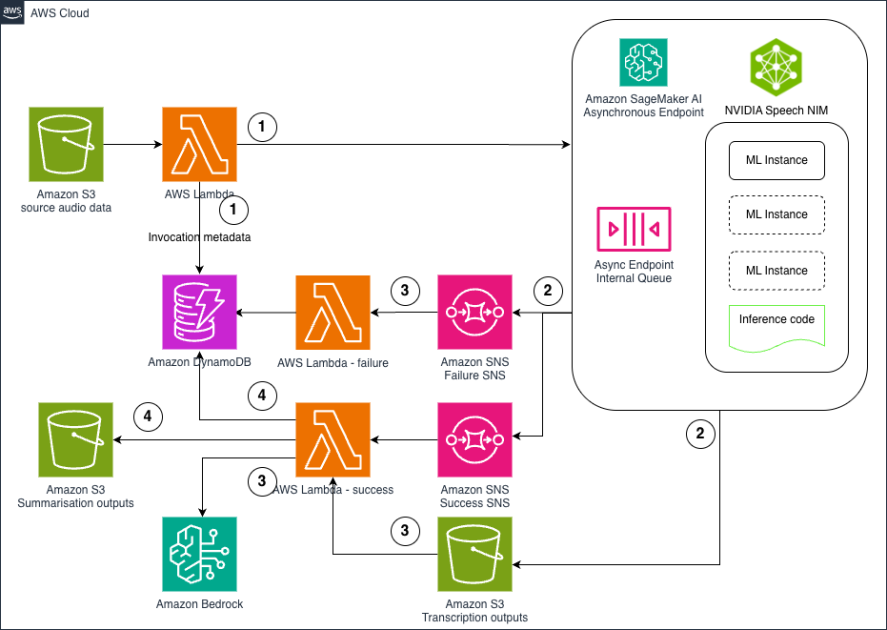
The following diagram illustrates the solution architecture.

Prerequisites
To implement this solution, you should have the following prerequisites:
- An AWS account with the required permissions to launch the stack using AWS CloudFormation.
- Amazon Elastic Compute Cloud (Amazon EC2) hosting the application should have internet access so as to download all the necessary OS patches and application related (python) libraries
- A basic understanding of Amazon Bedrock and FMs.
- This solution uses the Amazon Titan Text Embedding model. Make sure this model is enabled for use in Amazon Bedrock. On the Amazon Bedrock console, choose Model access in the navigation pane.
- If Amazon Titan Text Embeddings is enabled, the access status will state Access granted.
- If the model is not available, enable access to the model by choosing Manage model access, selecting Titan Multimodal Embeddings G1, and choosing Request model access. The model is enabled for use immediately.

Deploy the solution
The CloudFormation template deploys an Amazon Elastic Compute Cloud (Amazon EC2) instance to host the Streamlit application, along with other associated resources like an AWS Identity and Access Management (IAM) role and Amazon Simple Storage Service (Amazon S3) bucket. For more information about Amazon Bedrock and IAM, refer to How Amazon Bedrock Works with IAM.
In this post, we deploy the Streamlit application over an EC2 instance inside a VPC, but you can deploy it as a containerized application using a serverless solution with AWS Fargate. We discuss this in more detail in Part 2.
Complete the following steps to deploy the solution resources using AWS CloudFormation:
- Download the CloudFormation template StreamlitAppServer_Cfn.yml from the GitHub repo.
- On the AWS CloudFormation, create a new stack.
- For Prepare template, select Template is ready.
- In the Specify template section, provide the following information:
- For Template source, select Upload a template file.
- Choose file and upload the template you downloaded.
- Choose Next.

- For Stack name, enter a name (for this post,
StreamlitAppServer). - In the Parameters section, provide the following information:
- For Specify the VPC ID where you want your app server deployed, enter the VPC ID where you want to deploy this application server.
- For VPCCidr, enter the CIDR of the VPC you’re using.
- For SubnetID, enter the subnet ID from the same VPC.
- For MYIPCidr, enter the IP address of your computer or workstation so you can open the Streamlit application in your local browser.
You can run the command curl https://api.ipify.org on your local terminal to get your IP address.


- Leave the rest of the parameters as defaulted.
- Choose Next.
- In the Capabilities section, select the acknowledgement check box.
- Choose Submit.

Wait until you see the stack status show as CREATE_COMPLETE.

- Choose the stack’s Resources tab to see the resources you launched as part of the stack deployment.

- Choose the link for S3Bucket to be redirected to the Amazon S3 console.
- Note the S3 bucket name to update the deployment script later.
- Choose Create folder to create a new folder.
- For Folder name, enter a name (for this post,
gen-ai-qa).


Make sure to follow AWS security best practices for securing data in Amazon S3. For more details, see Top 10 security best practices for securing data in Amazon S3.
- Return to the stack Resources tab and choose the link to StreamlitAppServer to be redirected to the Amazon EC2 console.
- Select
StreamlitApp_Severand choose Connect.
- Select

This will open a new page with various ways to connect to the EC2 instance launched.
- For this solution, select Connect using EC2 Instance Connect, then choose Connect.

This will open an Amazon EC2 session in your browser.

- Run the following command to monitor the progress of all the Python-related libraries being installed as part of the user data:
- When you see the message
Finished running user data..., you can exit the session by pressing Ctrl + C.
This takes about 15 minutes to complete.

- Run the following commands to start the application:

- Make a note of the External URL value.
- If by any chance you exit of the session (or application is stopped), you can restart the application by running the same command as highlighted in Step # 18
Use the chatbot
Use the external URL you copied in the previous step to access the application.

You can upload your file to start using the chatbot for Q&A.

Clean up
To avoid incurring future charges, delete the resources that you created:
- Empty the contents of the S3 bucket you created as a part of this post.
- Delete the CloudFormation stack you created as part of this post.
Conclusion
In this post, we showed you how to create a Q&A chatbot that can answer questions across an enterprise’s corpus of documents with choices of FM available within Amazon Bedrock—within a single interface.
In Part 2, we show you how to use Knowledge Bases for Amazon Bedrock with enterprise-grade vector databases like OpenSearch Service, Amazon Aurora PostgreSQL, MongoDB Atlas, Weaviate, and Pinecone with your Q&A chatbot.
About the Authors
 Anand Mandilwar is an Enterprise Solutions Architect at AWS. He works with enterprise customers helping customers innovate and transform their business in AWS. He is passionate about automation around Cloud operation , Infrastructure provisioning and Cloud Optimization. He also likes python programming. In his spare time, he enjoys honing his photography skill especially in Portrait and landscape area.
Anand Mandilwar is an Enterprise Solutions Architect at AWS. He works with enterprise customers helping customers innovate and transform their business in AWS. He is passionate about automation around Cloud operation , Infrastructure provisioning and Cloud Optimization. He also likes python programming. In his spare time, he enjoys honing his photography skill especially in Portrait and landscape area.
 NagaBharathi Challa is a solutions architect in the US federal civilian team at Amazon Web Services (AWS). She works closely with customers to effectively use AWS services for their mission use cases, providing architectural best practices and guidance on a wide range of services. Outside of work, she enjoys spending time with family & spreading the power of meditation.
NagaBharathi Challa is a solutions architect in the US federal civilian team at Amazon Web Services (AWS). She works closely with customers to effectively use AWS services for their mission use cases, providing architectural best practices and guidance on a wide range of services. Outside of work, she enjoys spending time with family & spreading the power of meditation.