














![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Reinvent personalization with generative AI on Amazon Bedrock using task decomposition for agentic workflows
In this post, we present an automated solution to provide a consistent and responsible personalization experience for your customers by using smaller LLMs for website personalization tailored to businesses and industries. This decomposes the complex task into subtasks handled by task / domain adopted LLMs, adhering to company guidelines and human expertise.

Personalization has become a cornerstone of delivering tangible benefits to businesses and their customers. Generative AI and large language models (LLMs) offer new possibilities, although some businesses might hesitate due to concerns about consistency and adherence to company guidelines. This post presents an automated personalization solution that balances the innovative capabilities of LLMs with adherence to human directives and human-curated assets for a consistent and responsible personalization experience for your customers.
Our solution uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. For this post, we use Anthropic’s Claude models on Amazon Bedrock.
We present our solution through a fictional consulting company, OneCompany Consulting, using automatically generated personalized website content for accelerating business client onboarding for their consultancy service. The personalized content is built using generative AI by following human guidance and provided sources of truth. We employ task decomposition, using domain / task adopted LLMs for content personalization (UX designer/personalizer), image generation (artist), and building (builder/front end developer) for the final delivery of HTML, CSS, and JavaScript files. The approach broadly mimics a human organization pursuing the same objective. This allows us to create cost-effective, more controlled, more accurate and responsible personalized customer experiences, utilizing existing guidelines and assets originally designed for human-driven processes.
We provide our code base on GitHub for you to follow along, suggest possible enhancements and modifications, and help you innovate with generative AI in personalization. Generative AI on AWS can transform user experiences for customers while maintaining brand consistency and your desired customization.
Use case overview
Our fictional company, OneCompany Consulting, plans to use generative AI to automatically create personalized landing pages as their business clients sign in. Their clients have provided some basic public information during sign-up, such as state of location, industry vertical, company size, and their mission statement. In parallel, OneCompany maintains a market research repository gathered by their researchers, offers industry-specific services outlined in documents, and has compiled approved customer testimonials. UX/UI designers have established best practices and design systems applicable to all of their websites. These resources should be used as single sources of truth. Because we don’t have such expertise, we synthetically generate these assets to demonstrate the process that would otherwise be created by expert humans or other methods in real life.
The following diagram illustrates the process of generating a personalized landing page for business visitors after they sign up.

Fig 1. The process of customers signing up and the solution creating personalized websites using human-curated assets and guidelines.
We employed other LLMs available on Amazon Bedrock to synthetically generate fictitious reference materials to avoid potential biases that could arise from Amazon Claude’s pre-training data. In practical scenarios, these resources would be created by humans and organizations, containing more comprehensive and exhaustive details. Nonetheless, our solution can still be utilized.
- Client profiles – We have three business clients in the construction, manufacturing, and mining industries, which are mid-to-enterprise companies. The process assumes the information in the company profiles is public and that the companies who signed up opted in to OneCompany Consulting to use for personalization. The following example is for the construction industry:
Profiles = {
'Construction-Example': {
'Name': 'Example Corp Construction',
'Industry': 'Construction',
'CompanySize': 1500,
'CompanyType': 'Enterprise',
'Location': 'New York City, NY',
'Mission': 'Building a sustainable future for New York' }
}- Offerings – Offerings are documents that consolidate all offerings provided by OneCompany Consulting. The following is an example of a synthetically generated offering for the construction industry:
- Industry insights – Your LLMs can use industry pain points, news, and other resources to enrich personalized content. Because the industry news and resources are wide, we use a Retrieval Augmented Generation (RAG) framework to retrieve related information. The following is an example for the manufacturing industry:
- Testimonials – Synthetically generated customer testimonials are displayed for the visitors. In this solution, the LLM is asked to use the sentence without changes because it’s a testimonial. The following is an example:
- Design guidelines and systems – This part is for the instructions and rules to be followed for building the website. Our examples were manually created only for high-level guidance for simplicity.
- Guidelines – The following are some examples from the design guidelines:
- Instructions – The following are some examples from the design instructions:
Solution overview
To create personalized websites efficiently, we employ task decomposition—breaking down the complex process into simpler, decoupled sub-tasks. This approach allows using smaller, cost-effective language models, creating targeted prompts and contexts for increased accuracy and faithfulness, isolating responses for straightforward troubleshooting, and achieving cost savings.
In our example, we decomposed the overall personalized website creation process into three steps, each handled by specialized agents: the personalizer for tailoring content, the artist for generating images, and the frontend engineer/builder for coding. For the personalizer, we used Claude Sonnet due to the relative complexity of the task compared to code generation handled by Haiku. However, Claude Haiku can also be used for the personalization task, potentially leading to further cost savings. Yet, Haiku may require more prescriptive prompts and examples to achieve similar results. We recommend that customers test both Sonnet and Haiku to determine the optimal balance between performance and cost for their specific use case. In our demonstration, we chose to use Sonnet with a relatively simple prompt to showcase its efficiency, but the flexibility of this approach allows for various LLMs to be integrated into the agentic workflow.
The following diagram illustrates our agentic workflow.

Fig 2. Workflow diagram of agentic workflow made of specialized (task / domain adopted) LLMs.
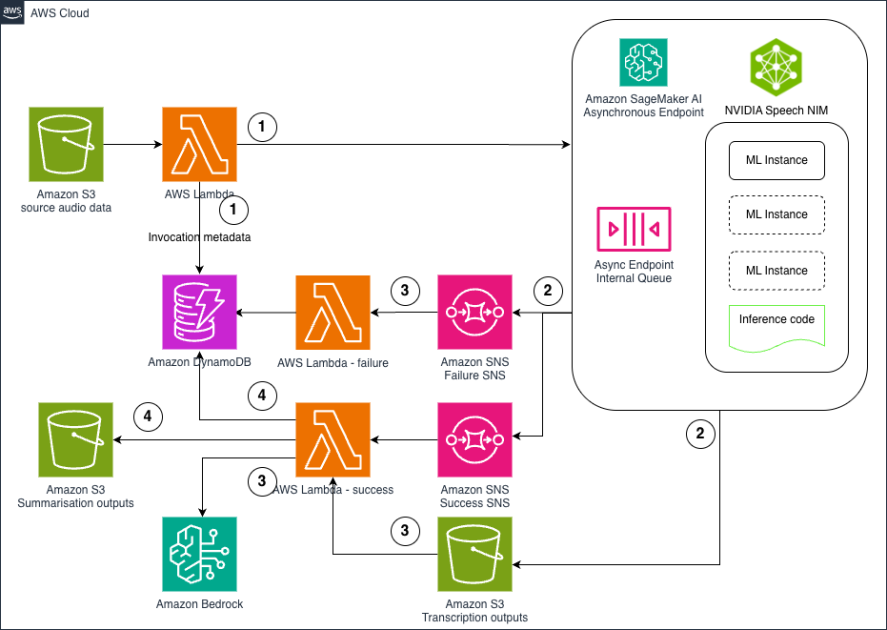
The following diagram illustrates our solution architecture.

Fig 3. Solutions architecture
The workflow includes the following steps:
- The client profile is stored as key-value pairs in JSON format. However, the JSON needs to be converted into natural language to simplify the task for the downstream LLMs, so they don’t have to figure out the JSON schema and associated meaning.
- After the profile is converted into text that explains the profile, a RAG framework is launched using Amazon Bedrock Knowledge Bases to retrieve related industry insights (articles, pain points, and so on). Amazon Bedrock Knowledge Bases is a fully managed capability that helps you implement the RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows. All the information retrieved from Amazon Bedrock Knowledge Bases is provided with citations to improve transparency and increase accuracy. In our example, if the client is a manufacturing customer building electronic vehicles (EVs), then the related context will be retrieved from the human-curated or human-created research documents.
- Now we’re ready to send our prompt to the personalizer LLM with all the relevant information. In addition to the customer profile and industry insights, we include offerings, design guidance, and testimonials, and ask the personalizer LLM to create a detailed website description and description of visuals.
- The response from the personalizer LLM is divided into two paths by a regex method. The first part moves to the frontend developer LLM.
- The second part is sent to the image generator or artist LLM.
- For the frontend developer LLM, we also use system design-related materials (in our case, design guidelines) so the frontend developer builds the website described by the personalizer LLM while applying the rules in the design guidelines. Here, we also prompted the LLM to use the company logo (which is the unicorn of AWS GameDay) to demonstrate incorporating existing design elements into the design. In addition, our prompt asks the frontend developer LLM to write the JavaScript to make the testimonials display and call to action dynamic.
- At the end of the process, we create a consolidated HTML file, which includes CSS and JavaScript, and store it in an Amazon Simple Storage Service (Amazon S3) bucket so that the assets are ready to be deployed.
Prerequisites
For this post, you need the following prerequisites:
- An AWS account.
- The AWS Command Line Interface (AWS CLI) installed.
- The AWS SDK for Python (Boto3) set up.
- Amazon SageMaker Studio is the integrated development environment (IDE) that allows us to build our example Jupyter notebook. For prerequisites to set up Amazon SageMaker, see Amazon SageMaker Prerequisites. For instructions to set up SageMaker Studio, see Launch Amazon SageMaker Studio Classic.
- Model access in Amazon Bedrock. In this example, we use Stability AI Stable Diffusion XL and Anthropic’s Claude 3 Sonnet and Haiku. You can execute the example by only using Haiku by replacing Sonnet in the personalizer.
- Building your knowledge base for the industry insights document is the final prerequisite. To do this, download the synthetically generated industry documents and upload them into an S3 bucket. You then need to create your knowledge base. Use the S3 bucket you created and note the knowledge base ID to use in later steps.
After you complete the prerequisites, you can use the following Jupyter notebook , which have all the necessary steps to follow this post.
Test the solution
Let’s start with our example manufacturing client, who is building the next-generation EVs ('Manufacturing-Example'). First, the profile of this client in JSON format is converted into natural language as follows:
customer = build_profile(UserProfile)
print(customer)
Output:
"Your customer is Example Corp Manufacturing. Their industry is manufacturing. They have 2,500 employees." \
"They are an enterprise company, located in San Jose, CA." \
"Their mission statement is “Building the next generation Electric Vehicles."Based on the customer profile giving the location and industry, the related background information is retrieved using RAG based on kbId = :
context_painpoints = Bedrock.doc_retrieve(query,kbId,numberOfResults = 10)
contexts_painpoints = get_contexts(context_painpoints)At this stage, we have the context and industry pain points. We now need to gather human-curated sources of truth such as testimonials, design guidelines, requirements, and offerings. These references aren’t numerous and require complete information in the system prompt. However, you can apply the RAG method used for industry insights to retrieve one or all of these references.
offerings = open("./references/offerings.txt", "r").read()
testimonials = open("./references/Testimonials.txt", "r").read()
design_steps= open("./references/RecommendedStepsToDesignNew.txt", "r").read()
design_guideline= open("./references/DesignGuidelineNew.txt", "r").read()We’re ready to input our prompt to the personalizer LLM, which is Anthropic’s Claude 3 Sonnet (or Haiku, if you used it) on Amazon Bedrock. We used the following which incorporates the parameters customer, testimonials, design_steps, and offerings. We prompted the LLM to generate a response in two parts:
- Detailed Website Description – Describing the website in text format
- Visual Elements – Describing the visual elements used
These two responses will be used in two different workflows in the following steps. The following is an example response (response_personalized_website) for the manufacturing client:
We use Stable Diffusion to generate visual assets based on the descriptions provided by the personalizer LLM. We extract the image descriptions enclosed within
pattern = r'(.+?) \s*(.+?) 'The images are created and put into the S3 bucket to store your website assets.
Now we’re ready to create the website HTML, CSS, and JavaScript assets. We used the following prompt template, which uses response_personalized_website from the personalizer, actual testimonials, and the UI design guidelines:
prompt =
f"""
You are an experienced frontend web developer specializing in creating accessible, responsive, and visually appealing websites. Your task is to generate the complete HTML, CSS, and JavaScript code that accurately implements the provided 'Website Description' while adhering to the specified guidelines.
After this step, you have all the necessary assets to preview your website. You can put the HTML and created files into a folder and use a web browser to see your created website.
The following screenshots show examples of generated personalized pages for EV manufacturing, mining, and construction clients, respectively. Each image is displayed for 3 seconds in GIF format. To experience the full quality and dynamic features of these pages, we recommend you visit the examples folder, download the folders, and open the corresponding main.html files with your internet browser.

Fig 4. Generated example personalized pages for three industry clients.
Highlights from the test
The solution automatically generated personalized web pages, including personalized images within the provided guardrails, prompts, and reference materials. The workflow considered appropriate color contrasts, such as dark backgrounds with white fonts for accessibility. The solution generated representative icons with consistent coloring and themes across the pages. The workflow also created industry-specific, engaging labels, descriptions, offerings, and pain points based on the source of truth references. The offering selection and pain point sections are especially noteworthy because they were tailored to the visitor. For example, the hero page showcased an EV on a production line, whereas a mining company with a “sustainability” motto received green icons and a focus on that topic. The construction company from New York had themes mentioning their specific points. The workflow is capable of creating dynamic assets as prompted, such as testimonials or call-to-action buttons. Additionally, the solution created consistent assets that can scale well and are compatible with multiple devices, as requested.
In this example, we did not fully exhaust the capabilities of personalization. However, we hope these examples can provide a simple starting point for your personalization use cases.
Clean up
To clean up, start by deleting the S3 bucket you created for your knowledge base. Then delete your knowledge base. Because we used Amazon Bedrock on demand, unless you invoke the endpoint, it will not incur any cost. However, we recommend deleting the artifacts in SageMaker Studio or the SageMaker Studio domain if you used SageMaker Studio to follow along with this demo.
Suggested enhancements
You can extend this solution with some further enhancements, such as the following:
- Use batch processing for cost-effective asset creation based on visitor profiles. You can use batch inference with Amazon Bedrock or batch transform with SageMaker.
- Cluster similar client profiles to reduce design element variations for frugality and consistency.
- Provide website templates and chain-of-thought descriptions to follow design patterns more prescriptively.
- Use Haiku instead of Sonnet for further cost reduction. You may need more prescriptive and multi-shot prompts as you switch to Haiku for the personalization stage.
- Retrieve existing company images and icons using semantic search instead of generating visuals. For example, you can build semantic image search using Amazon Titan.
Conclusions
In this post, we presented an automated solution to provide a consistent and responsible personalization experience for your customers. This approach uses smaller LLMs for website personalization tailored to businesses and industries. It decomposes the complex task into subtasks handled by task / domain adopted LLMs, adhering to company guidelines and human expertise. Using a fictional business consulting company scenario, we demonstrated the solution by generating personalized marketing content like text, images, HTML, CSS, and JavaScript code. The process employs techniques like RAG, prompt engineering with personas, and human-curated references to maintain output control.
By combining generative AI, curated data, and task decomposition, businesses can cost-effectively create accurate, personalized website experiences aligned with their branding and design systems.
Amazon Bedrock, which you can use to build generative AI applications, is at the center of this solution. To get started with Amazon Bedrock, we recommend following the quick start and familiarizing yourself with building generative AI applications.
About the Authors
 Burak Gozluklu is a Principal AI/ML Specialist Solutions Architect and lead GenAI Scientist Architect for Amazon on AWS, based in Boston, MA. He helps strategic customers adopt AWS technologies and specifically Generative AI solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. He maintains his connection to academia as a research affiliate at MIT. Outside of work, Burak is an enthusiast of yoga.
Burak Gozluklu is a Principal AI/ML Specialist Solutions Architect and lead GenAI Scientist Architect for Amazon on AWS, based in Boston, MA. He helps strategic customers adopt AWS technologies and specifically Generative AI solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. He maintains his connection to academia as a research affiliate at MIT. Outside of work, Burak is an enthusiast of yoga.
 Chidi Prince John is a Data Scientist at Amazon. He designs, builds and deploys models for large-scale personalization in Amazon Payments. Chidi has a Master’s degree in Quantitative Management from Duke University and a Bachelor’s degree in Economics from the University of Nigeria. Outside of work, he is passionate about soccer and TV shows.
Chidi Prince John is a Data Scientist at Amazon. He designs, builds and deploys models for large-scale personalization in Amazon Payments. Chidi has a Master’s degree in Quantitative Management from Duke University and a Bachelor’s degree in Economics from the University of Nigeria. Outside of work, he is passionate about soccer and TV shows.
 Dieter D’Haenens is a Senior Product Manager for Amazon, responsible for customer growth, delivering personalized experiences and driving the Amazon flywheel. Leveraging his expertise in retail and strategy, he is passionate about solving customer problems through scalable, innovative AI and ML solutions. Dieter holds a Bachelor of Science in Economics from Ghent University, a Master in General Management from Vlerick Business School, and a Master of Science in Business Analytics from Southern Methodist University. In his spare time, he enjoys traveling and sports.
Dieter D’Haenens is a Senior Product Manager for Amazon, responsible for customer growth, delivering personalized experiences and driving the Amazon flywheel. Leveraging his expertise in retail and strategy, he is passionate about solving customer problems through scalable, innovative AI and ML solutions. Dieter holds a Bachelor of Science in Economics from Ghent University, a Master in General Management from Vlerick Business School, and a Master of Science in Business Analytics from Southern Methodist University. In his spare time, he enjoys traveling and sports.








