














![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Create a generative AI-based application builder assistant using Amazon Bedrock Agents
Agentic workflows are a fresh new perspective in building dynamic and complex business use- case based workflows with the help of large language models (LLM) as their reasoning engine or brain. In this post, we set up an agent using Amazon Bedrock Agents to act as a software application builder assistant.

In this post, we set up an agent using Amazon Bedrock Agents to act as a software application builder assistant.
Agentic workflows are a fresh new perspective in building dynamic and complex business use- case based workflows with the help of large language models (LLM) as their reasoning engine or brain. These agentic workflows decompose the natural language query-based tasks into multiple actionable steps with iterative feedback loops and self-reflection to produce the final result using tools and APIs.
Amazon Bedrock Agents helps you accelerate generative AI application development by orchestrating multistep tasks. Amazon Bedrock Agents uses the reasoning capability of foundation models (FMs) to break down user-requested tasks into multiple steps. They use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide a final response to the end user. This offers tremendous use case flexibility, enables dynamic workflows, and reduces development cost. Amazon Bedrock Agents is instrumental in customization and tailoring apps to help meet specific project requirements while protecting private data and securing their applications. These agents work with AWS managed infrastructure capabilities and Amazon Bedrock, reducing infrastructure management overhead. Additionally, agents streamline workflows and automate repetitive tasks. With the power of AI automation, you can boost productivity and reduce cost.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Solution overview
Typically, a three-tier software application has a UI interface tier, a middle tier (the backend) for business APIs, and a database tier. The generative AI–based application builder assistant from this post will help you accomplish tasks through all three tiers. It can generate and explain code snippets for UI and backend tiers in the language of your choice to improve developer productivity and facilitate rapid development of use cases. The agent can recommend software and architecture design best practices using the AWS Well-Architected Framework for the overall system design.
The agent can generate SQL queries using natural language questions using a database schema DDL (data definition language for SQL) and execute them against a database instance for the database tier.
We use Amazon Bedrock Agents with two knowledge bases for this assistant. Amazon Bedrock Knowledge Bases inherently uses the Retrieval Augmented Generation (RAG) technique. A typical RAG implementation consists of two parts:
- A data pipeline that ingests data from documents typically stored in Amazon Simple Storage Service (Amazon S3) into a knowledge base, namely a vector database such as Amazon OpenSearch Serverless, so that it’s available for lookup when a question is received
- An application that receives a question from the user, looks up the knowledge base for relevant pieces of information (context), creates a prompt that includes the question and the context, and provides it to an LLM for generating a response
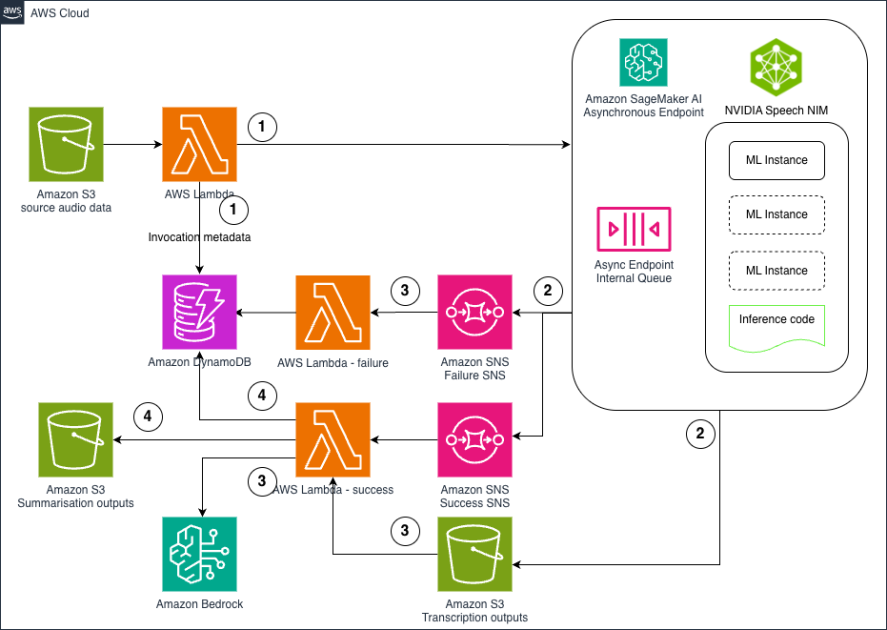
The following diagram illustrates how our application builder assistant acts as a coding assistant, recommends AWS design best practices, and aids in SQL code generation.

Based on the three workflows in the preceding figure, let’s explore the type of task you need for different use cases:
- Use case 1 – If you want to write and validate a SQL query against a database, use the existing DDL schemas set up as knowledge base 1 to come up with the SQL query. The following are sample user queries:
- What are the total sales amounts by year?
- What are the top five most expensive products?
- What is the total revenue for each employee?
- Use case 2 – If you want recommendations on design best practices, look up the AWS Well-Architected Framework knowledge base (knowledge base 2). The following are sample user queries:
- How can I design secure VPCs?
- What are some S3 best practices?
- Use case 3 – You might want to author some code, such as helper functions like validate email, or use existing code. In this case, use prompt engineering techniques to call the default agent LLM and generate the email validation code. The following are sample user queries:
- Write a Python function to validate email address syntax.
- Explain the following code in lucid, natural language to me.
$code_to_explain(this variable is populated using code contents from any code file of your choice. More details can be found in the notebook).
Prerequisites
To run this solution in your AWS account, complete the following prerequisites:
- Clone the GitHub repository and follow the steps explained in the README.
- Set up an Amazon SageMaker notebook on an ml.t3.medium Amazon Elastic Compute Cloud (Amazon EC2) instance. For this post, we have provided an AWS CloudFormation template, available in the GitHub repository. The CloudFormation template also provides the required AWS Identity and Access Management (IAM) access to set up the vector database, SageMaker resources, and AWS Lambda
- Acquire access to models hosted on Amazon Bedrock. Choose Manage model access in the navigation pane on the Amazon Bedrock console and choose from the list of available options. We use Anthropic’s Claude v3 (Sonnet) on Amazon Bedrock and Amazon Titan Embeddings Text v2 on Amazon Bedrock for this post.
Implement the solution
In the GitHub repository notebook, we cover the following learning objectives:
- Choose the underlying FM for your agent.
- Write a clear and concise agent instruction to use one of the two knowledge bases and base agent LLM. (Examples given later in the post.)
- Create and associate an action group with an API schema and a Lambda function.
- Create, associate, and ingest data into the two knowledge bases.
- Create, invoke, test, and deploy the agent.
- Generate UI and backend code with LLMs.
- Recommend AWS best practices for system design with the AWS Well-Architected Framework guidelines.
- Generate, run, and validate the SQL from natural language understanding using LLMs, few-shot examples, and a database schema as a knowledge base.
- Clean up agent resources and their dependencies using a script.
Agent instructions and user prompts
The application builder assistant agent instruction looks like the following.
Each user question to the agent by default includes the following system prompt.
Note: The following system prompt remains the same for each agent invocation, only the {user_question_to_agent} gets replaced with user query.
 Shayan Ray is an Applied Scientist at Amazon Web Services. His area of research is all things natural language (like NLP, NLU, NLG). His work has been focused on conversational AI, task-oriented dialogue systems and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.
Shayan Ray is an Applied Scientist at Amazon Web Services. His area of research is all things natural language (like NLP, NLU, NLG). His work has been focused on conversational AI, task-oriented dialogue systems and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.








