














![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









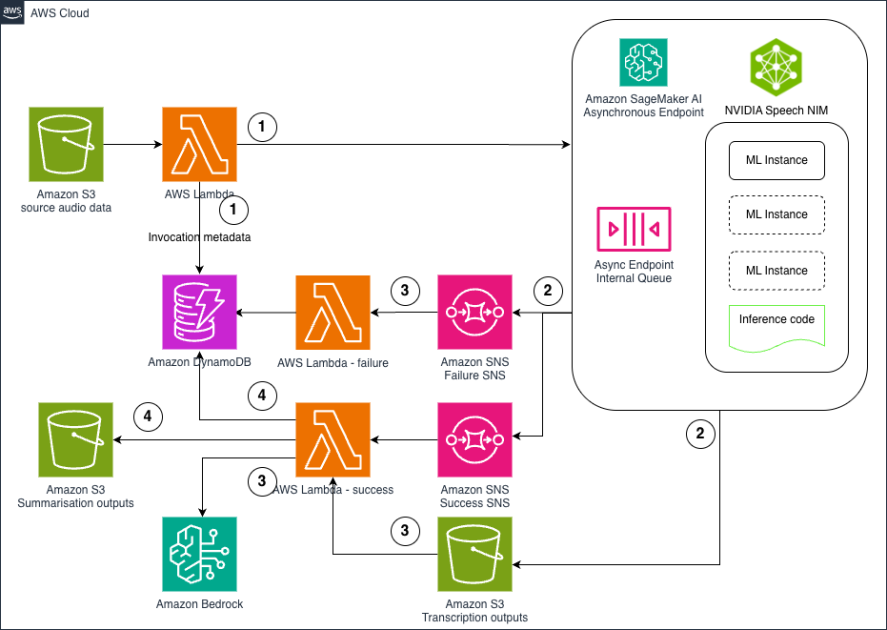
Cohere Embed multimodal embeddings model is now available on Amazon SageMaker JumpStart
The Cohere Embed multimodal embeddings model is now generally available on Amazon SageMaker JumpStart. This model is the newest Cohere Embed 3 model, which is now multimodal and capable of generating embeddings from both text and images, enabling enterprises to unlock real value from their vast amounts of data that exist in image form. In this post, we discuss the benefits and capabilities of this new model with some examples.

The Cohere Embed multimodal embeddings model is now generally available on Amazon SageMaker JumpStart. This model is the newest Cohere Embed 3 model, which is now multimodal and capable of generating embeddings from both text and images, enabling enterprises to unlock real value from their vast amounts of data that exist in image form.
In this post, we discuss the benefits and capabilities of this new model with some examples.
Overview of multimodal embeddings and multimodal RAG architectures
Multimodal embeddings are mathematical representations that integrate information not only from text but from multiple data modalities—such as product images, graphs, and charts—into a unified vector space. This integration allows for seamless interaction and comparison between different types of data. As foundational models (FMs) advance, they increasingly require the ability to interpret and generate content across various modalities to better mimic human understanding and communication. This trend toward multimodality enhances the capabilities of AI systems in tasks like cross-modal retrieval, where a query in one modality (such as text) retrieves data in another modality (such as images or design files).
Multimodal embeddings can enable personalized recommendations by understanding user preferences and matching them with the most relevant assets. For instance, in ecommerce, product images are a critical factor influencing purchase decisions. Multimodal embeddings models can enhance personalization through visual similarity search, where users can upload an image or select a product they like, and the system finds visually similar items. In the case of retail and fashion, multimodal embeddings can capture stylistic elements, enabling the search system to recommend products that fit a particular aesthetic, such as “vintage,” “bohemian,” or “minimalist.”
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. However, as data becomes increasingly multimodal in nature, extending these systems to handle various data types is crucial to provide more comprehensive and contextually rich responses. MM-RAG systems that use multimodal embeddings models to encode both text and images into a shared vector space can simplify retrieval across modalities. MM-RAG systems can also enable enhanced customer service AI agents that can handle queries that involve both text and images, such as product defects or technical issues.
Cohere Multimodal Embed 3: Powering enterprise search across text and images
Cohere’s embeddings model, Embed 3, is an industry-leading AI search model that is designed to transform semantic search and generative AI applications. Cohere Embed 3 is now multimodal and capable of generating embeddings from both text and images. This enables enterprises to unlock real value from their vast amounts of data that exist in image form. Businesses can now build systems that accurately search important multimodal assets such as complex reports, ecommerce product catalogs, and design files to boost workforce productivity.
Cohere Embed 3 translates input data into long strings of numbers that represent the meaning of the data. These numerical representations are then compared to each other to determine similarities and differences. Cohere Embed 3 places both text and image embeddings in the same space for an integrated experience.
The following figure illustrates an example of this workflow. This figure is simplified for illustrative purposes. In practice, the numerical representations of data (seen in the output column) are far longer and the vector space that stores them has a higher number of dimensions.

This similarity comparison enables applications to retrieve enterprise data that is relevant to an end-user query. In addition to being a fundamental component of semantic search systems, Cohere Embed 3 is useful in RAG systems because it makes generative models like the Command R series have the most relevant context to inform their responses.
All businesses, across industry and size, can benefit from multimodal AI search. Specifically, customers are interested in the following real-world use cases:
- Graphs and charts – Visual representations are key to understanding complex data. You can now effortlessly find the right diagrams to inform your business decisions. Simply describe a specific insight and Cohere Embed 3 will retrieve relevant graphs and charts, making data-driven decision-making more efficient for employees across teams.
- Ecommerce product catalogs – Traditional search methods often limit you to finding products through text-based product descriptions. Cohere Embed 3 transforms this search experience. Retailers can build applications that surface products that visually match a shopper’s preferences, creating a differentiated shopping experience and improving conversion rates.
- Design files and templates – Designers often work with vast libraries of assets, relying on memory or rigorous naming conventions to organize visuals. Cohere Embed 3 makes it simple to locate specific UI mockups, visual templates, and presentation slides based on a text description. This streamlines the creative process.
The following figure illustrates some examples of these use cases.

At a time when businesses are increasingly expected to use their data to drive outcomes, Cohere Embed 3 offers several advantages that accelerate productivity and improves customer experience.
The following chart compares Cohere Embed 3 with another embeddings model. All text-to-image benchmarks are evaluated using Recall@5; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo. Graphs and charts benchmark accuracy is based on business reports and presentations constructed internally. ecommerce benchmark accuracy is based on a mix of product catalog and fashion catalog datasets. Design files benchmark accuracy is based on a product design retrieval dataset constructed internally.

BEIR (Benchmarking IR) is a heterogeneous benchmark—it uses a diverse collection of datasets and tasks designed for evaluating information retrieval (IR) models across diverse tasks. It provides a common framework for assessing the performance of natural language processing (NLP)-based retrieval models, making it straightforward to compare different approaches. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. Recall@5 measures the proportion of relevant items retrieved within the top five results, compared to the total number of relevant items in the dataset
Cohere’s latest Embed 3 model’s text and image encoders share a unified latent space. This approach has a few important benefits. First, it enables you to include both image and text features in a single database and therefore reduces complexity. Second, it means current customers can begin embedding images without re-indexing their existing text corpus. In addition to leading accuracy and ease of use, Embed 3 continues to deliver the same useful enterprise search capabilities as before. It can output compressed embeddings to save on database costs, it’s compatible with over 100 languages for multilingual search, and it maintains strong performance on noisy real-world data.
Solution overview
SageMaker JumpStart offers access to a broad selection of publicly available FMs. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from data preparation to model deployment and monitoring. Data scientists and developers can use the SageMaker integrated development environment (IDE) to access a vast array of pre-built algorithms, customize their own models, and seamlessly scale their solutions. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead.
You can access the Cohere Embed family of models using SageMaker JumpStart in Amazon SageMaker Studio.
For those new to SageMaker JumpStart, we walk through using SageMaker Studio to access models in SageMaker JumpStart.
Prerequisites
Make sure you meet the following prerequisites:
- Make sure your SageMaker AWS Identity and Access Management (IAM) role has the
AmazonSageMakerFullAccesspermission policy attached. - To deploy Cohere multimodal embeddings successfully, confirm the following:
- Your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- Alternatively, confirm your AWS account has a subscription to the model. If so, skip to the next section in this post.
- Your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
Deployment starts when you choose the Deploy option. You may be prompted to subscribe to this model through AWS Marketplace. If you’re already subscribed, then you can proceed and choose Deploy. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.

Subscribe to the model package
To subscribe to the model package, complete the following steps:
- Depending on the model you want to deploy, open the model package listing page for it.
- On the AWS Marketplace listing, choose Continue to subscribe.
- On the Subscribe to this software page, choose Accept Offer if you and your organization agrees with EULA, pricing, and support terms.
- Choose Continue to configuration and then choose an AWS Region.
You will see a product ARN displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
- Subscribe to the Cohere embeddings model package on AWS Marketplace.
- Choose the appropriate model package ARN for your Region. For example, the ARN for Cohere Embed Model v3 – English is:
arn:aws:sagemaker:[REGION]:[ACCOUNT_ID]:model-package/cohere-embed-english-v3-7-6d097a095fdd314d90a8400a620cac54
Deploy the model using the SDK
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
Use the SageMaker SDK to create a client and deploy the models:
If the endpoint is already created using SageMaker Studio, you can simply connect to it:
Consider the following best practices:
- Choose an appropriate instance type based on your performance and cost requirements. This example uses ml.g5.xlarge, but you might need to adjust this based on your specific needs.
- Make sure your IAM role has the necessary permissions, including AmazonSageMakerFullAccess2.
- Monitor your endpoint’s performance and costs using Amazon CloudWatch.
Inference example with Cohere Embed 3 using the SageMaker SDK
The following code example illustrates how to perform real-time inference using Cohere Embed 3. We walk through a sample notebook to get started. You can also find the source code on the accompanying GitHub repo.
Pre-setup
Import all required packages using the following code:
Create helper functions
Use the following code to create helper functions that determine whether the input document is text or image, and download images given a list of URLs:
Generate embeddings for text and image inputs
The following code shows a compute_embeddings() function we defined that will accept multimodal inputs to generate embeddings with Cohere Embed 3:
Find the most relevant embedding based on query
The Search() function generates query embeddings and computes a similarity matrix between the query and embeddings:
Test the solution
Let’s assemble all the input documents; notice that there are both text and image inputs:
Generate embeddings for the documents:
The output is a matrix of 11 items of 1,024 embedding dimensions.
Search for the most relevant documents given the query “Fun animal toy”
The following screenshots show the output.








Try another query “Learning toy for a 6 year old”.
As you can see from the results, the images and documents are returns based on the queries from the user and demonstrates functionality of the new version of Cohere embed 3 for multimodal embeddings.
Clean up
To avoid incurring unnecessary costs, when you’re done, delete the SageMaker endpoints using the following code snippets:
Alternatively, to use the SageMaker console, complete the following steps:
- On the SageMaker console, under Inference in the navigation pane, choose Endpoints.
- Search for the embedding and text generation endpoints.
- On the endpoint details page, choose Delete.
- Choose Delete again to confirm.
Conclusion
Cohere Embed 3 for multimodal embeddings is now available with SageMaker and SageMaker JumpStart. To get started, refer to SageMaker JumpStart pretrained models.
Interested in diving deeper? Check out the Cohere on AWS GitHub repo.
About the Authors
 Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
 Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundation model (FM) providers to develop and execute joint Go-To-Market strategies, enabling customers to effectively train, deploy, and scale FMs to solve industry specific challenges. Karan holds a Bachelor of Science in Electrical and Instrumentation Engineering from Manipal University, a master’s in science in Electrical Engineering from Northwestern University and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundation model (FM) providers to develop and execute joint Go-To-Market strategies, enabling customers to effectively train, deploy, and scale FMs to solve industry specific challenges. Karan holds a Bachelor of Science in Electrical and Instrumentation Engineering from Manipal University, a master’s in science in Electrical Engineering from Northwestern University and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
 Yang Yang is an Independent Software Vendor (ISV) Solutions Architect at Amazon Web Services based in Seattle, where he supports customers in the financial services industry. Yang focuses on developing generative AI solutions to solve business and technical challenges and help drive faster time-to-market for ISV customers. Yang holds a Bachelor’s and Master’s degree in Computer Science from Texas A&M University.
Yang Yang is an Independent Software Vendor (ISV) Solutions Architect at Amazon Web Services based in Seattle, where he supports customers in the financial services industry. Yang focuses on developing generative AI solutions to solve business and technical challenges and help drive faster time-to-market for ISV customers. Yang holds a Bachelor’s and Master’s degree in Computer Science from Texas A&M University.
 Malhar Mane is an Enterprise Solutions Architect at AWS based in Seattle. He supports enterprise customers in the Digital Native Business (DNB) segment and specializes in generative AI and storage. Malhar is passionate about helping customers adopt generative AI to optimize their business. Malhar holds a Bachelor’s in Computer Science from University of California, Irvine.
Malhar Mane is an Enterprise Solutions Architect at AWS based in Seattle. He supports enterprise customers in the Digital Native Business (DNB) segment and specializes in generative AI and storage. Malhar is passionate about helping customers adopt generative AI to optimize their business. Malhar holds a Bachelor’s in Computer Science from University of California, Irvine.








