







![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Rad AI reduces real-time inference latency by 50% using Amazon SageMaker
This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI. Rad AI has reshaped radiology reporting, developing solutions that streamline the most tedious and repetitive tasks, and saving radiologists’ time. Since 2018, using state-of-the-art proprietary and open source large language models (LLMs), our flagship product—Rad AI Impressions— has significantly reduced the […]

This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI.
Rad AI has reshaped radiology reporting, developing solutions that streamline the most tedious and repetitive tasks, and saving radiologists’ time. Since 2018, using state-of-the-art proprietary and open source large language models (LLMs), our flagship product—Rad AI Impressions— has significantly reduced the time radiologists spend dictating reports, by generating Impression sections.
The Impression section serves as the conclusion of a radiology report, including summarization, follow-up recommendations, and highlights of significant findings. It stands as the primary result for the clinician who ordered the study, influencing the subsequent course of the patient’s treatment. Given its pivotal role, accuracy and clarity in this section are paramount. Traditionally, radiologists dictated every word of the impressions section, creating it from scratch for each report. This time-consuming process led to fatigue and burnout, and involved redundant manual dictation in many studies.
The automation provided by Rad AI Impressions not only reduces burnout, but also safeguards against errors arising from manual repetition. It increases the capacity to generate reports, reducing health system turnaround times and making high-quality care available to more patients. Impressions are meticulously customized to each radiologist’s preferred language and style. Radiologists review and revise the output as they see fit, maintaining exact control over the final report, and Rad AI also helps radiologists catch and fix a wide variety of errors in their reports. This improves the overall quality of patient care.
Today, by executing abstractive summarization tasks at scale, Rad AI’s language models generate impressions for millions of radiology studies every month, assisting thousands of radiologists at more than 40% of all US health systems and 9 of the 10 largest US radiology practices. Based on years of working with customers, we estimate that our solutions save 1 hour for every 9-hour radiology shift.
Operating within the real-time radiology workflow, our product functions online around the clock, adhering to strict latency requirements. For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 seconds, with minimal latency. This efficiency empowers radiologists to achieve optimal results in their studies.
In this post, we share how Rad AI reduced real-time inference latency by 50% using Amazon SageMaker.
Challenges in deploying advanced ML models in healthcare
Rad AI, being an AI-first company, integrates machine learning (ML) models across various functions—from product development to customer success, from novel research to internal applications. AI models are ubiquitous within Rad AI, enhancing multiple facets of the organization. It might seem straightforward to integrate ML models into healthcare workflows, but the challenges are many and interconnected.
Healthcare applications make some of the usual AI complexities more challenging. Although any AI solution has to balance speed against accuracy, radiologists rely on the timeliness of our impressions to care for patients, and expect our clinical accuracy to always improve. This constant innovation requires new kinds of models and demands continually improving specialized software and hardware. As inference logic becomes more complex, composing results from multiple models (each seeing regular releases), and a streamlined and reproducible process for orchestration and management is of paramount importance. Even diagnosing basic issues, at this level of complexity, requires a deliberate and methodical approach.
Rad AI’s ML organization tackles this challenge on two fronts. First, it enhances researcher productivity by providing the necessary processes and automation, positioning them to deliver high-quality models with regularity. Second, it navigates operational requirements by making strategic infrastructure choices and partnering with vendors that offer both computational resources and managed services. By enhancing both researcher productivity and operational efficiency, Rad AI creates an environment that fosters ML innovation.
To succeed in this environment, Rad AI takes advantage of the availability and consistency offered by SageMaker real-time endpoints, a fully managed AI inference service that allows seamless deployment and scaling of models independently from the applications that use them. By integrating Amazon Elastic Container Service (Amazon ECS) and SageMaker, Rad AI’s ML system forms a complex server-side architecture with numerous online components. This infrastructure enables Rad AI to navigate the complexities of real-time model deployment, so radiologists receive timely and accurate impressions.
With focused effort and strategic planning, Rad AI continues to enhance its systems and processes, ultimately improving outcomes for patients and clinicians alike.
Let’s transition to exploring solutions and architectural strategies.
Approaches to researcher productivity
To translate our strategic planning into action, we developed approaches focused on refining our processes and system architectures. By improving our deployment pipelines and enhancing collaboration between researchers and MLOps engineers, we streamlined the integration of models into our healthcare workflows. In this section, we discuss the practices that have enabled us to optimize our operations and advance our ML capabilities.
To enable researchers to work at full capacity while minimizing synchronization with MLOps engineers, we recognized the need for normalization in our deployment processes. The pipeline begins when researchers manage tags and metadata on the corresponding model artifact. This approach abstracts away the complexity beneath the surface and eliminates the usual ceremony involved in deploying models. By centralizing model registration and aligning practices across team members, we clamp the entry point for model deployment. This allows us to build additional tooling as we identify bottlenecks or areas for improvement.
Instead of frequent synchronization between MLOps and research teams, we observe practices and identify needs as they arise. Under the hood, we employ an in-house tool combined with modular, reusable infrastructure as code to automate the creation of pull requests. No one writes any code manually. The protocol between researchers and engineers is reduced to pull request reviews, eliminating the need for circulating documents or holding alignment meetings. The declarative nature of the infrastructure code, coupled with intuitive design, answers most questions that MLOps engineers would typically ask researchers—all within the file added to the repository and pull requested.

These approaches, combined with the power and streamlining offered by SageMaker, have reduced the model deployment process to a matter of minutes after a model artifact is ready. Deploying a new model to a target environment now requires minimal effort. Only when dealing with peculiar characteristics of an architecture or specific configurations—such as adjustments for tensor parallelism—do additional considerations arise. By minimizing the complexity and time involved in deployment, we enable researchers to concentrate on innovation rather than operational hurdles.
Architectural strategies
In our architectural strategies, we aimed to achieve high performance and scalability while effectively deploying ML models. The need for low latency in inference tasks—especially critical in healthcare settings where delays can impact patient care—required architectures capable of efficiently handling both GPU-bound and CPU-bound workloads. Additionally, straightforward configuration options that allow us to quickly generate benchmarks became essential. This capability enables us to swiftly evaluate different backend engines, a necessity in latency-bound environments.
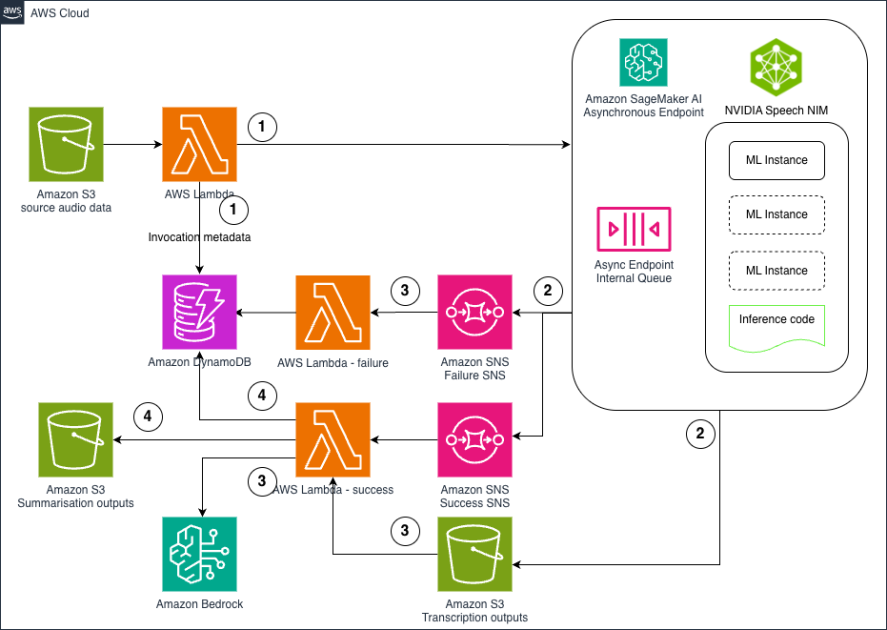
In addition to process improvements, we implemented architectural strategies to address the technical aspects. As previously mentioned, real-world inference systems often combine GPU-bound and CPU-bound inference tasks, along with the need to compose results from multiple services. This complexity is typically required for an ML organization to provide product-side functionality. We use AWS Fargate to run CPU inferences and other supporting components, usually alongside a comprehensive frontend API. This setup implements a classic architecture consisting of a frontend API and backend application services. GPU inferences are served through SageMaker real-time inference endpoints. An illustration of this architecture is provided in the following diagram.

We standardized on using SageMaker Large Model Inference (LMI) containers, maintained and offered from public Amazon repositories. These containers support several optimization frameworks and provide simple configuration delivery options. This setup is straightforward for researchers to interpret and spares them the unnecessary hassle of dealing with dependencies and compatibility issues among various ML libraries and managing the underlying container layers.
Diving deeper into our architecture, we consider one of the deployment strategies used in our online inference system. On a single instance, we employ a server that schedules inference tasks with DJL Serving as the model server. This approach allows us to select from and experiment with multiple backend engines, including popular frameworks such as TensorRT-LLM and vLLM. The abstractions and built-in integration with SageMaker real-time endpoints, along with support for multi-GPU inference and tensor parallelism, enable us to quickly evaluate different backends for a given task.

As Rad AI has matured, our architectural solutions have evolved. Initially, we relied on custom components, managing our own container images and running NVIDIA Triton Server directly on instances provided by Amazon ECS. However, by migrating to SageMaker managed hosting and using instance types ranging from 1–8 GPUs of various kinds, we implemented the architectural strategies discussed earlier. Removing the undifferentiated heavy lifting involved in building and optimizing model hosting infrastructure reduced our total cost of ownership by 50%. Optimizing the instance types and container parameters decreased latency by the same margin.
When deploying models with SageMaker Inference, consider the following key best practices:
- It’s important to build a robust model deployment pipeline that automates the process of registering, testing, and promoting models to production. This can involve integrating SageMaker with continuous integration and delivery (CI/CD) tools to streamline the model release process.
- In terms of infrastructure choices, it’s important to right-size your SageMaker endpoints to match the expected traffic and model complexity, using features like auto scaling to dynamically adjust capacity.
- Performance optimization techniques like model optimization and inference container parameter tuning can help improve latency and reduce costs.
- Comprehensive monitoring and logging of model performance in production is critical to quickly identify and address any issues that arise.
Conclusion
One of the enduring challenges in healthcare is enhancing patient care on a global scale. Rad AI is committed to meeting this challenge by transforming the field of radiology. By refining our processes and implementing strategic architectural solutions, we have enhanced both researcher productivity and operational efficiency.
Our deliberate approach to model deployment and infrastructure management has streamlined workflows and significantly reduced costs and latency. Every additional second saved not only increases bandwidth and reduces fatigue for the radiologists we serve, but also improves patient outcomes and benefits healthcare organizations in a variety of ways. Our inference systems are instrumental in realizing these objectives, using SageMaker’s scalability and flexibility to integrate ML models seamlessly into healthcare settings. As we continue to evolve, our commitment to innovation and excellence positions Rad AI at the forefront of AI-driven healthcare solutions.
Share your thoughts and questions in the comments.
References
- Rad AI Impressions
- Deep Java Library: Large Model Inference
- Weights & Biases. (2023, May 2). Continuous Deployment with Weights & Biases Automations YouTube video
About the authors
 Ken Kao is an executive leader with 12+ years leading engineering and product across early, mid-stage startups and public companies. He is currently the VP of Engineering at Rad AI pushing the frontier of applying Gen AI to healthcare to help make physicians more efficient and improve patient outcome. Prior to that, he was at Meta driving VR Device performance, emulation, and development tooling & Infrastructure. He has also previously held engineering leadership roles at Airbnb, Flatiron Health, and Palantir. Ken holds M.S. and B.S degrees in Electrical Engineering from Stanford University.
Ken Kao is an executive leader with 12+ years leading engineering and product across early, mid-stage startups and public companies. He is currently the VP of Engineering at Rad AI pushing the frontier of applying Gen AI to healthcare to help make physicians more efficient and improve patient outcome. Prior to that, he was at Meta driving VR Device performance, emulation, and development tooling & Infrastructure. He has also previously held engineering leadership roles at Airbnb, Flatiron Health, and Palantir. Ken holds M.S. and B.S degrees in Electrical Engineering from Stanford University.
 Hasan Ali Demirci is a Staff Engineer at Rad AI, specializing in software and infrastructure for machine learning. Since joining as an early engineer hire in 2019, he has steadily worked on the design and architecture of Rad AI’s online inference systems. He is certified as an AWS Certified Solutions Architect and holds a bachelor’s degree in mechanical engineering from Boğaziçi University in Istanbul and a graduate degree in finance from the University of California, Santa Cruz.
Hasan Ali Demirci is a Staff Engineer at Rad AI, specializing in software and infrastructure for machine learning. Since joining as an early engineer hire in 2019, he has steadily worked on the design and architecture of Rad AI’s online inference systems. He is certified as an AWS Certified Solutions Architect and holds a bachelor’s degree in mechanical engineering from Boğaziçi University in Istanbul and a graduate degree in finance from the University of California, Santa Cruz.
 Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.
Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.
 Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in financial services industry.
Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in financial services industry.