

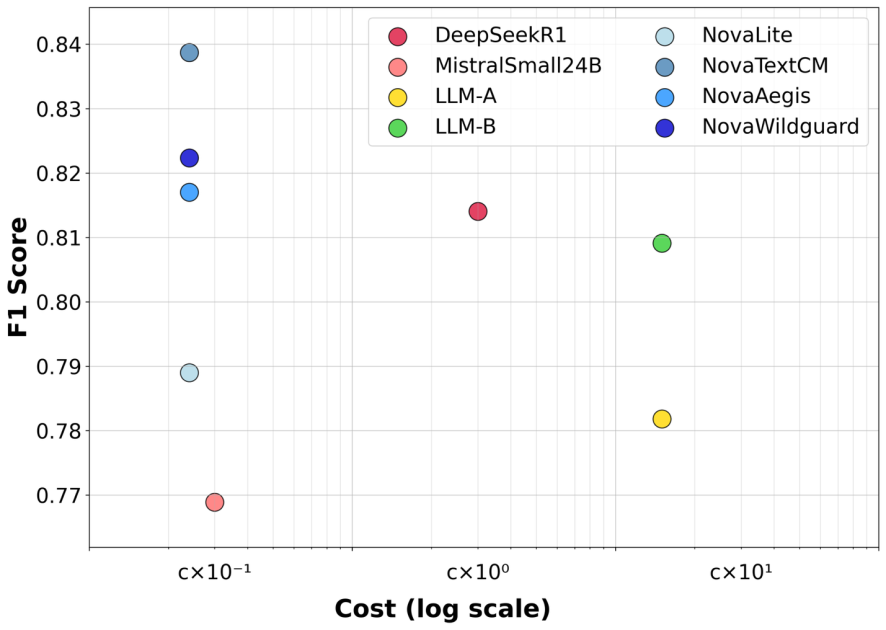













![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Automate video insights for contextual advertising using Amazon Bedrock Data Automation
Amazon Bedrock Data Automation (BDA) is a new managed feature powered by FMs in Amazon Bedrock. BDA extracts structured outputs from unstructured content—including documents, images, video, and audio—while alleviating the need for complex custom workflows. In this post, we demonstrate how BDA automatically extracts rich video insights such as chapter segments and audio segments, detects text in scenes, and classifies Interactive Advertising Bureau (IAB) taxonomies, and then uses these insights to build a nonlinear ads solution to enhance contextual advertising effectiveness.

Contextual advertising, a strategy that matches ads with relevant digital content, has transformed digital marketing by delivering personalized experiences to viewers. However, implementing this approach for streaming video-on-demand (VOD) content poses significant challenges, particularly in ad placement and relevance. Traditional methods rely heavily on manual content analysis. For example, a content analyst might spend hours watching a romantic drama, placing an ad break right after a climactic confession scene, but before the resolution. Then, they manually tag the content with metadata such as romance, emotional, or family-friendly to verify appropriate ad matching. Although this manual process helps create a seamless viewer experience and maintains ad relevance, it proves highly impractical at scale.
Recent advancements in generative AI, particularly multimodal foundation models (FMs), demonstrate advanced video understanding capabilities and offer a promising solution to these challenges. We previously explored this potential in the post Media2Cloud on AWS Guidance: Scene and ad-break detection and contextual understanding for advertising using generative AI, where we demonstrated custom workflows using Amazon Titan Multimodal embeddings G1 models and Anthropic’s Claude FMs from Amazon Bedrock. In this post, we’re introducing an even simpler way to build contextual advertising solutions.
Amazon Bedrock Data Automation (BDA) is a new managed feature powered by FMs in Amazon Bedrock. BDA extracts structured outputs from unstructured content—including documents, images, video, and audio—while alleviating the need for complex custom workflows. In this post, we demonstrate how BDA automatically extracts rich video insights such as chapter segments and audio segments, detects text in scenes, and classifies Interactive Advertising Bureau (IAB) taxonomies, and then uses these insights to build a nonlinear ads solution to enhance contextual advertising effectiveness. A sample Jupyter notebook is available in the following GitHub repository.
Solution overview
Nonlinear ads are digital video advertisements that appear simultaneously with the main video content without interrupting playback. These ads are displayed as overlays, graphics, or rich media elements on top of the video player, typically appearing at the bottom of the screen. The following screenshot is an illustration of the final linear ads solution we will implement in this post.
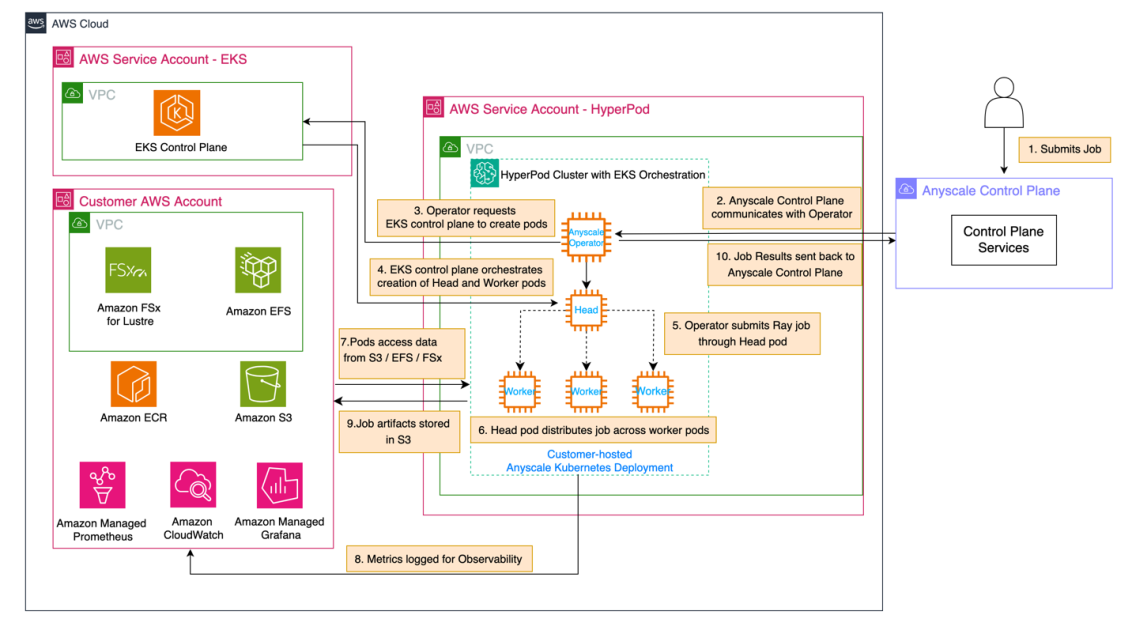
The following diagram presents an overview of the architecture and its key components.

The workflow is as follows:
- Users upload videos to Amazon Simple Storage Service (Amazon S3).
- Each new video invokes an AWS Lambda function that triggers BDA for video analysis. An asynchronous job runs to analyze the video.
- The analysis output is stored in an output S3 bucket.
- The downstream system (AWS Elemental MediaTailor) can consume the chapter segmentation, contextual insights, and metadata (such as IAB taxonomy) to drive better ad decisions in the video.
For simplicity in our notebook example, we provide a dictionary that maps the metadata to a set of local ad inventory files to be displayed with the video segments. This simulates how MediaTailor interacts with content manifest files and requests replacement ads from the Ad Decision Service.
Prerequisites
The following prerequisites are needed to run the notebooks and follow along with the examples in this post:
- An AWS account with requisite permissions, including access to Amazon Bedrock, Amazon S3, and a Jupyter notebook environment to run the sample notebooks.
- A Jupyter notebook environment with appropriate permissions to access Amazon Bedrock APIs. For more information about Amazon Bedrock policy configurations, see Get credentials to grant programmatic access.
- Install third-party libraries like FFmpeg, open-cv, and webvtt-py before executing the code sections.
- Use the Meridian short film from Netflix Open Content under the Creative Commons Attribution 4.0 International Public License as the example video.
Video analysis using BDA
Thanks to BDA, processing and analyzing videos has become significantly simpler. The workflow consists of three main steps: creating a project, invoking the analysis, and retrieving analysis results. The first step—creating a project—establishes a reusable configuration template for your analysis tasks. Within the project, you define the types of analyses you want to perform and how you want the results structured. To create a project, use the create_data_automation_project API from the BDA boto3 client. This function returns a dataAutomationProjectArn, which you will need to include with each runtime invocation.
Upon project completion (status: COMPLETED), you can use the invoke_data_automation_async API from the BDA runtime client to start video analysis. This API requires input/output S3 locations and a cross-Region profile ARN in your request. BDA requires cross-Region inference support for all file processing tasks, automatically selecting the optimal AWS Region within your geography to maximize compute resources and model availability. This mandatory feature helps provide optimal performance and customer experience at no additional cost. You can also optionally configure Amazon EventBridge notifications for job tracking (for more details, see Tutorial: Send an email when events happen using Amazon EventBridge). After it’s triggered, the process immediately returns a job ID while continuing processing in the background.
BDA standard outputs for video
Let’s explore the outputs from BDA for video analysis. Understanding these outputs is essential to understand what type of insights BDA provides and how to use them to build our contextual advertising solution. The following diagram is an illustration of key components of a video, and each defines a granularity level you need to analyze the video content.

The key components are as follows:
- Frame – A single still image that creates the illusion of motion when displayed in rapid succession with other frames in a video.
- Shot – A continuous series of frames recorded from the moment the camera starts rolling until it stops.
- Chapter – A sequence of shots that forms a coherent unit of action or narrative within the video, or a continuous conversation topic. BDA determines chapter boundaries by first classifying the video as either visually heavy (such as movies or episodic content) or audio heavy (such as news or presentations). Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics.
- Video – The complete content that enables analysis at the full video level.
Video-level analysis
Now that we defined the video granularity terms, let’s examine the insights BDA provides. At full video level, BDA generates a comprehensive summary that delivers a concise overview of the video’s key themes and main content. The system also includes speaker identification, a process that attempts to derive speakers’ names based on audible cues (For example, “I’m Jane Doe”) or visual cues on the screen whenever possible. To illustrate this capability, we can examine the following full video summary that BDA generated for the short film Meridian:
In a series of mysterious disappearances along a stretch of road above El Matador Beach, three seemingly unconnected men vanished without a trace. The victims – a school teacher, an insurance salesman, and a retiree – shared little in common except for being divorced, with no significant criminal records or ties to criminal organizations…Detective Sullivan investigates the cases, initially dismissing the possibility of suicide due to the absence of bodies. A key breakthrough comes from a credible witness who was walking his dog along the bluffs on the day of the last disappearance. The witness described seeing a man atop a massive rock formation at the shoreline, separated from the mainland. The man appeared to be searching for something or someone when suddenly, unprecedented severe weather struck the area with thunder and lightning….The investigation takes another turn when Captain Foster of the LAPD arrives at the El Matador location, discovering that Detective Sullivan has also gone missing. The case becomes increasingly complex as the connection between the disappearances, the mysterious woman, and the unusual weather phenomena remains unexplained.
Along with the summary, BDA generates a complete audio transcript that includes speaker identification. This transcript captures the spoken content while noting who is speaking throughout the video. The following is an example of a transcript generated by BDA from the Meridian short film:
[spk_0]: So these guys just disappeared.
[spk_1]: Yeah, on that stretch of road right above El Matador. You know it. With the big rock. That’s right, yeah.
[spk_2]: You know, Mickey Cohen used to take his associates out there, get him a bond voyage.
…
Chapter-level analysis
BDA performs detailed analysis at the chapter level by generating comprehensive chapter summaries. Each chapter summary includes specific start and end timestamps to precisely mark the chapter’s duration. Additionally, when relevant, BDA applies IAB categories to classify the chapter’s content. These IAB categories are part of a standardized classification system created for organizing and mapping publisher content, which serves multiple purposes, including advertising targeting, internet security, and content filtering. The following example demonstrates a typical chapter-level analysis:
[00:00:20;04 – 00:00:23;01] Automotive, Auto Type
The video showcases a vintage urban street scene from the mid-20th century. The focal point is the Florentine Gardens building, an ornate structure with a prominent sign displaying “Florentine GARDENS” and “GRUEN Time”. The building’s facade features decorative elements like columns and arched windows, giving it a grand appearance. Palm trees line the sidewalk in front of the building, adding to the tropical ambiance. Several vintage cars are parked along the street, including a yellow taxi cab and a black sedan. Pedestrians can be seen walking on the sidewalk, contributing to the lively atmosphere. The overall scene captures the essence of a bustling city environment during that era.
For a comprehensive list of supported IAB taxonomy categories, see Videos.
Also at the chapter level, BDA produces detailed audio transcriptions with precise timestamps for each spoken segment. These granular transcriptions are particularly useful for closed captioning and subtitling tasks. The following is an example of a chapter-level transcription:
[26.85 – 29.59] So these guys just disappeared.
[30.93 – 34.27] Yeah, on that stretch of road right above El Matador.
[35.099 – 35.959] You know it.
[36.49 – 39.029] With the big rock. That’s right, yeah.
[40.189 – 44.86] You know, Mickey Cohen used to take his associates out there, get him a bond voyage.
…
Shot- and frame-level insights
At a more granular level, BDA provides frame-accurate timestamps for shot boundaries. The system also performs text detection and logo detection on individual frames, generating bounding boxes around detected text and logo along with confidence scores for each detection. The following image is an example of text bounding boxes extracted from the Meridian video.

Contextual advertising solution
Let’s apply the insights extracted from BDA to power nonlinear ad solutions. Unlike traditional linear advertising that relies on predetermined time slots, nonlinear advertising enables dynamic ad placement based on content context. At the chapter level, BDA automatically segments videos and provides detailed insights including content summaries, IAB categories, and precise timestamps. These insights serve as intelligent markers for ad placement opportunities, allowing advertisers to target specific chapters that align with their promotional content.
In this example, we prepared a list of ad images and mapped them each to specific IAB categories. When BDA identifies IAB categories at the chapter level, the system automatically matches and selects the most relevant ad from the list to display as an overlay banner during that chapter. In the following example, when BDA identifies a scene with a car driving on a country road (IAB category: Automotive, Travel), the system selects and displays a suitcase at an airport from the pre-mapped ad database. This automated matching process promotes precise ad placement while maintaining optimal viewer experience.
Clean up
Follow the instructions in the cleanup section of the notebook to delete the projects and resources provisioned to avoid unnecessary charges. Refer to Amazon Bedrock pricing for details regarding BDA cost.
Conclusion
Amazon Bedrock Data Automation, powered by foundation models from Amazon Bedrock, marks a significant advancement in video analysis. BDA minimizes the complex orchestration layers previously required for extracting deep insights from video content, transforming what was once a sophisticated technical challenge into a streamlined, managed solution. This breakthrough empowers media companies to deliver more engaging, personalized advertising experiences while significantly reducing operational overhead. We encourage you to explore the sample Jupyter notebook provided in the GitHub repository to experience BDA firsthand and discover additional BDA use cases across other modalities in the following resources:
- Simplify multimodal generative AI with Amazon Bedrock Data Automation
- Get insights from multimodal content with Amazon Bedrock Data Automation, now generally available
About the authors
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries
 Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.
Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.








