![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









Supercharge generative AI workflows with NVIDIA DGX Cloud on AWS and Amazon Bedrock Custom Model Import
This post is co-written with Andrew Liu, Chelsea Isaac, Zoey Zhang, and Charlie Huang from NVIDIA. DGX Cloud on Amazon Web Services (AWS) represents a significant leap forward in democratizing access to high-performance AI infrastructure. By combining NVIDIA GPU expertise with AWS scalable cloud services, organizations can accelerate their time-to-train, reduce operational complexity, and unlock […]

This post is co-written with Andrew Liu, Chelsea Isaac, Zoey Zhang, and Charlie Huang from NVIDIA.
DGX Cloud on Amazon Web Services (AWS) represents a significant leap forward in democratizing access to high-performance AI infrastructure. By combining NVIDIA GPU expertise with AWS scalable cloud services, organizations can accelerate their time-to-train, reduce operational complexity, and unlock new business opportunities. The platform’s performance, security, and flexibility position it as a foundational element for those seeking to stay at the forefront of AI innovation.
In this post, we explore a powerful end-to-end development workflow using NVIDIA DGX Cloud on AWS, Run:ai, and Amazon Bedrock Custom Model Import. We demonstrate how to fine-tune the open source Llama 3.1-70b model using NVIDIA DGX Cloud’s high performance multi-GPU compute orchestrated with Run:ai, and we deploy the fine-tuned model using Custom Model Import in Amazon Bedrock for scalable serverless inference.
NVIDIA DGX Cloud on AWS
Organizations aim for rapid deployment of generative AI and agentic AI solutions to gain business value quickly. AWS and NVIDIA have been partnering together to provide AI infrastructure, software, and services. The two companies have co-engineered NVIDIA DGX Cloud on AWS: a fully managed, high-performance AI training platform with flexible, short-term access to large GPU clusters. DGX Cloud on AWS is optimized for faster time to train at every layer of the full stack platform to deliver productivity from day one. With DGX Cloud on AWS, organizations can use the latest NVIDIA architectures, including Amazon EC2 P6e-GB200 UltraServer accelerated by NVIDIA Grace Blackwell GB200 Superchip (coming soon to DGX Cloud on AWS). DGX Cloud on AWS also includes access to NVIDIA AI and cloud experts, as well as 24/7 support, to help enterprises deliver maximum return on investment (ROI) and available in AWS Marketplace.
Amazon Bedrock Custom Model Import
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. With Amazon Bedrock Custom Model Import, customers can access their imported custom models on demand in a serverless manner, freeing them from the complexities of deploying and scaling models themselves. They can accelerate generative AI application development by using built-in tools and features such as Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, Amazon Bedrock Agents, and more—all through a unified and consistent developer experience.
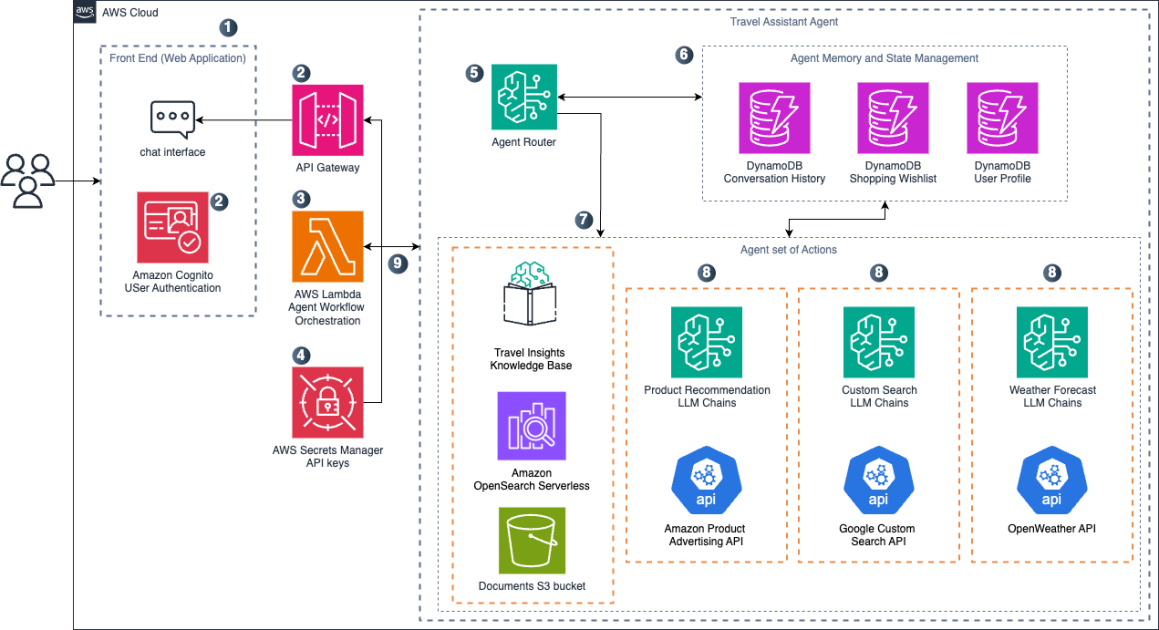
NVIDIA DGX Cloud on AWS architecture overview
DGX Cloud is a fully managed platform from NVIDIA co-engineered with AWS for customers that need to train or fine-tune a model. DGX Cloud on AWS uses p5.48xlarge instances, each with 8 H100 GPUs, 8 x 3.84 TB NVMe storage, and 32 network interfaces, providing a total network bandwidth of 3200 Gbps. DGX Cloud on AWS organizes node instances into optimal layouts for artificial intelligence and machine learning (AI/ML) cluster workloads and placed in contiguous clusters, resulting in lower latency and faster results. DGX Cloud uses Amazon Elastic Kubernetes Service (Amazon EKS) and NVIDIA software such as NVIDIA NeMo and NVIDIA Run:ai to deploy and optimize Kubernetes clusters. Each cluster uses an Amazon FSx for Lustre file system for high-performance shared storage. DGX Cloud on AWS also uses Run:ai for workload orchestration, software as a service (SaaS) that provides intelligent workload scheduling, prioritization, and preemption to maximize GPU utilization.
The application plane, which includes the p5 instances and FSx for Lustre file system, operates as a single tenant dedicated to each customer, providing complete isolation and dedicated performance for AI workloads. In addition, DGX Cloud also offers two private access connectivity options for customers who want a secure and direct connection from the cluster to their own AWS account: private access with AWS PrivateLink and private access with AWS Transit Gateway. With private access with AWS PrivateLink, private links are set up with endpoints into a customer’s AWS account to connect to the Kubernetes API, Run:ai control plane, and for cluster ingress. With private access with AWS Transit Gateway, traffic into and out of the DGX Cloud cluster will go through a customer’s transit gateway. The Run:ai control plane will still be connected through a PrivateLink endpoint.
The following diagram illustrates the solution architecture.

Setting up NVIDIA DGX Cloud on AWS
After you get access to your DGX Cloud cluster on AWS, you can start setting up your cluster to run workloads. A cluster admin first needs to create departments and projects for users to run their workloads in. A default department can be provided when you get initial access to your cluster. Projects allow for additional granular quota management beyond the quota set at the department level. After departments and projects are set up, users can then use their allocated quota to run workloads.
The following figure illustrates the Run:ai interface in DGX Cloud on AWS.

In this example, an interactive Jupyter notebook workspace running the nvcr.io/nvidia/nemo:25.02 image is needed to preprocess and manage the code. You’ll need 8 GPUs and at least 20 TBs of mounted storage provided by Amazon FSx for Lustre. This should look like the following image. An Amazon Simple Storage Service (Amazon S3) bucket can also be mounted to directly connect your data to your Amazon account. To learn more about how to create a notebook with NVIDIA NeMo, refer to Interactive NeMo Workload Job.

Fine-tuning the Llama3 model on NVIDIA DGX Cloud
After your Jupyter notebook is created, you can access it and upload our example notebook to download the dataset and Hugging Face model. Using the terminal function, copy the code into your PersistentVolumeClaim (PVC) from the NVIDIA NeMo Run repo. After this is downloaded, to run the notebook, you’ll need a Hugging Face account and create a Hugging Face token with access to the Llama 3.1 70b model on Hugging Face. To use the NVIDIA NeMo framework, convert the Hugging Face tensors to the .nemo format. We’re fine-tuning this model to follow user generated instructions using the open source daring-anteater dataset. This dataset is focused on instruction tuning and covers a wide range of tasks and scenarios. When your data and model finish downloading, you’re ready to train your model.
The following figure illustrates the sample notebook to fine-tune Llama model in DGX Cloud on AWS.

Use NeMo-Run to launch the training job in the cluster. Four H100 nodes (EC2 P5 instances) with 8 GPUs each were used to fine-tune our model in this example. To launch this training, you need to create an application token and secret. After your training is launched, you can click the launched workload to look at its event history, metrics, and logs. The metrics will show the GPU compute and memory utilization. The logs for the master node will show the progress of the fine-tuning job.
The following figure illustrates the sample metrics in DGX Cloud on AWS.

When the model is finished pre-training, return to your Jupyter notebook to convert the model back to Hugging Face safetensors and move the model to Amazon S3. This requires your AWS access key and an S3 bucket. With the tensors and tokens moved, you’re ready to import this model using Amazon Bedrock Custom Model Import.
The following figure illustrates the sample Amazon S3 bucket.

Import your custom model to Amazon Bedrock
To import your custom model, follow these steps:
- On the Amazon Bedrock console in the navigation pane, choose Foundation models and then choose Imported model.
- In Model details, enter a name such as
CustomModelName, as shown in the following screenshot.

- For each custom model you import, you can supply an Import job name or use the identifier that is already supplied, which you can use to track and monitor the import of your model.
- Scroll down to Model Import Settings, where you can create your custom model by importing the model weights from an S3 bucket or importing a model directly from Amazon SageMaker. For demonstration, you can import Meta’s Llama 3.1 70B model from Amazon S3 by choosing Browse S3 and navigating to your model files.

- Verify your model, configuration, and tokenizer, and select any other files associated with your model.
The following figure illustrates the model import setting in Amazon Bedrock.

- After you’ve selected your model files, you can choose to encrypt your model using a customer managed key by selecting Customize encryption settings and selecting your AWS Key Management Store (AWS KMS) key. By default, Amazon Bedrock encrypts custom models with AWS owned keys. You can’t view, manage, or use AWS owned keys or audit their use. However, you don’t have to take action or change programs to protect the keys that encrypt your data. Under Service access, you can choose to associate an AWS Identity and Access Management (IAM) role that you’ve created, but you can leave the default selected for Amazon Bedrock to create a default role for you.
- When your settings are complete, choose Import model.
To monitor the progress of your importing job, choose Jobs in the Imported models section, as shown in the following screenshot.

After your model has been imported, it should be listed on the Models tab, as shown in the following screenshot.

Model inference using Amazon Bedrock
The Amazon Bedrock playgrounds are a tool in the AWS Management Console that provide a visual interface to experiment with running inference on different models and using different configurations. You can use the playgrounds to test different models and values before you integrate them into your application. The following steps demonstrate how to use the custom model that you imported into Amazon Bedrock and submit a prompt in the playground:
- In the Amazon Bedrock navigation pane, choose Chat/text and then choose the Mode you wish to test.
- Choose Select model and under Custom & managed endpoints, choose your model to test and choose Apply, as shown in the following screenshot.

- With the model loaded into the playground, you can begin by sending your first prompt. Enter a description to create the request and choose Run.
The following screenshot shows a sample prompt to write an email to a wine expert, requesting a guest article contribution for your wine blog.

Clean up
Use the following steps to clean up the infrastructure created for this post and avoid incurring ongoing costs.
- Delete the imported model:
aws bedrock delete-imported-model --model-identifier Demo-Mode
- Delete the AWS KMS key created:
aws kms schedule-key-deletion --key-id
Conclusion
In this post, we discussed how NVIDIA DGX Cloud on AWS, combined with Amazon Bedrock Custom Model Import for scalable deployment, offers a powerful end-to-end solution for developing, fine-tuning, and operationalizing generative and agentic AI applications. This approach is particularly advantageous for organizations seeking to accelerate time to market, minimize operational overhead, and foster rapid innovation. Enterprise developers can start with NVIDIA DGX Cloud on AWS today. For more NVIDIA DGX Cloud recipes, check out the examples in dgxc-benchmarking GitHub repo.
Resources
- AWS AI infrastructure with NVIDIA Blackwell: Two powerful compute solutions for the next frontier of AI
- New Amazon EC2 P6e-GB200 UltraServers accelerated by NVIDIA Grace Blackwell GPUs for the highest AI performance
About the authors
 Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives.
Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives.
 Chad Elias is a Senior Solutions Architect for AWS. He’s passionate about helping organizations modernize their infrastructure and applications through AI/ML solutions. When not designing the next generation of cloud architectures, Chad enjoys contributing to open source projects, mentoring junior engineers, and exploring the latest technologies.
Chad Elias is a Senior Solutions Architect for AWS. He’s passionate about helping organizations modernize their infrastructure and applications through AI/ML solutions. When not designing the next generation of cloud architectures, Chad enjoys contributing to open source projects, mentoring junior engineers, and exploring the latest technologies.
 Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community.
 Timothy Ma is a Principal Specialist in generative AI at AWS, where he collaborates with customers to design and deploy cutting-edge machine learning solutions. He also leads go-to-market strategies for generative AI services, helping organizations harness the potential of advanced AI technologies.
Timothy Ma is a Principal Specialist in generative AI at AWS, where he collaborates with customers to design and deploy cutting-edge machine learning solutions. He also leads go-to-market strategies for generative AI services, helping organizations harness the potential of advanced AI technologies.
 Andrew Liu is the manager of the DGX Cloud Technical Marketing Engineering team, focusing on showcasing the use cases and capabilities of DGX Cloud by creating technical assets and collateral. His goal is to demonstrate how DGX Cloud empowers NVIDIA and the ecosystem to create world-class AI solutions. In his free time, Andrew enjoys being outdoors and going mountain biking and skiing.
Andrew Liu is the manager of the DGX Cloud Technical Marketing Engineering team, focusing on showcasing the use cases and capabilities of DGX Cloud by creating technical assets and collateral. His goal is to demonstrate how DGX Cloud empowers NVIDIA and the ecosystem to create world-class AI solutions. In his free time, Andrew enjoys being outdoors and going mountain biking and skiing.
 Chelsea Isaac is a Senior Solutions Architect for DGX Cloud at NVIDIA. She’s passionate about helping enterprise customers and partners deploy and scale AI solutions in the cloud. In her free time, she enjoys working out, traveling, and reading.
Chelsea Isaac is a Senior Solutions Architect for DGX Cloud at NVIDIA. She’s passionate about helping enterprise customers and partners deploy and scale AI solutions in the cloud. In her free time, she enjoys working out, traveling, and reading.
 Zoey Zhang is a Technical Marketing Engineer on DGX Cloud at NVIDIA. She works on integrating machine learning models into large-scale compute clusters on the cloud and uses her technical expertise to bring NVIDIA products to market.
Zoey Zhang is a Technical Marketing Engineer on DGX Cloud at NVIDIA. She works on integrating machine learning models into large-scale compute clusters on the cloud and uses her technical expertise to bring NVIDIA products to market.
 Charlie Huang is a senior product marketing manager for Cloud AI at NVIDIA. Charlie is responsible for taking NVIDIA DGX Cloud to market with cloud partners. He has vast experience in AI/ML, cloud and data center solutions, virtualization, and security.
Charlie Huang is a senior product marketing manager for Cloud AI at NVIDIA. Charlie is responsible for taking NVIDIA DGX Cloud to market with cloud partners. He has vast experience in AI/ML, cloud and data center solutions, virtualization, and security.