Observing and evaluating AI agentic workflows with Strands Agents SDK and Arize AX
In this post, we present how the Arize AX service can trace and evaluate AI agent tasks initiated through Strands Agents, helping validate the correctness and trustworthiness of agentic workflows.

This post is co-written with Rich Young from Arize AI.
Agentic AI applications built on agentic workflows differ from traditional workloads in one important way: they’re nondeterministic. That is, they can produce different results with the same input. This is because the large language models (LLMs) they’re based on use probabilities when generating each token. This inherent unpredictability can lead AI application designers to ask questions related to the correction plan of action, the optimal path of an agent and the correct set of tools with the right parameters. Organizations that want to deploy such agentic workloads need an observability system that can make sure that they’re producing results that are correct and can be trusted.
In this post, we present how the Arize AX service can trace and evaluate AI agent tasks initiated through Strands Agents, helping validate the correctness and trustworthiness of agentic workflows.
Challenges with generative AI applications
The path from a promising AI demo to a reliable production system is fraught with challenges that many organizations underestimate. Based on industry research and real-world deployments, teams face several critical hurdles:
- Unpredictable behavior at scale – Agents that perform well in testing might fail with unexpected inputs in production, such as new language variations or domain-specific jargon that cause irrelevant or misunderstood responses.
- Hidden failure modes – Agents can produce plausible but wrong outputs or skip steps unnoticed, such as miscalculating financial metrics in a way that seems correct but misleads decision-making.
- Nondeterministic paths – Agents might choose inefficient or incorrect decision paths, such as taking 10 steps to route a query that should take only 5, leading to poor user experiences.
- Tool integration complexity – Agents can break when calling APIs incorrectly, for example, passing the wrong order ID format so that a refund silently fails despite a successful inventory update.
- Cost and performance variability – Loops or verbose outputs can cause runaway token costs and latency spikes, such as an agent making more than 20 LLM calls and delaying a response from 3 to 45 seconds.
These challenges mean that traditional testing and monitoring approaches are insufficient for AI systems. Success requires a more thoughtful approach that incorporates a more comprehensive strategy.
Arize AX delivers a comprehensive observability, evaluation, and experimentation framework
Arize AX is the enterprise-grade AI engineering service that helps teams monitor, evaluate, and debug AI applications from development to production lifecycle. Incorporating Arize’s Phoenix foundation, AX adds enterprise essentials such as the “Alyx” AI assistant, online evaluations, automatic prompt optimization, role-based access control (RBAC), and enterprise scale and support. AX offers a comprehensive solution to organizations that caters to both technical and nontechnical personas so they can manage and improve AI agents from development through production at scale. Arize AX capabilities include:
- Tracing – Full visibility into LLM operations using OpenTelemetry to capture model calls, retrieval steps, and metadata such as tokens and latency for detailed analysis.
- Evaluation – Automated quality monitoring with LLM-as-a-judge evaluations on production samples, supporting custom evaluators and clear success metrics.
- Datasets – Maintain versioned, representative datasets for edge cases, regression tests, and A/B testing, refreshed with real production examples.
- Experiments – Run controlled tests to measure the impact of changes to prompts or models, validating improvements with statistical rigor.
- Playground – Interactive environment to replay traces, test prompt variations, and compare model responses for effective debugging and optimization.
- Prompt management – Version, test, and deploy prompts like code, with performance tracking and gradual rollouts to catch regressions early.
- Monitoring and alerting – Real-time dashboards and alerts for latency, errors, token usage, and drift, with escalation for critical issues.
- Agent visualization – Analyze and optimize agent decision paths to reduce loops and inefficiencies, refining planning strategies.
These components form a comprehensive observability strategy that treats LLM applications as mission-critical production systems requiring continuous monitoring, evaluation, and improvement.
Arize AX and Strands Agents: A powerful combination
Strands Agents is an open source SDK, a powerful low-code framework for building and running AI agents with minimal overhead. Designed to simplify the development of sophisticated agent workflows, Strands unifies prompts, tools, LLM interactions, and integration protocols into a single streamlined experience. It supports both Amazon Bedrock hosted and external models, with built-in capabilities for Retrieval Augmented Generation (RAG), Model Context Protocol (MCP), and Agent2Agent (A2A) communication. In this section, we walk through building an agent with Strands Agent SDK, instrumenting it with Arize AX for trace-based evaluation, and optimizing its behavior.
The following workflow shows how a Strands agent handles a user task end-to-end—invoking tools, retrieving context, and generating a response—while sending traces to Arize AX for evaluation and optimization.
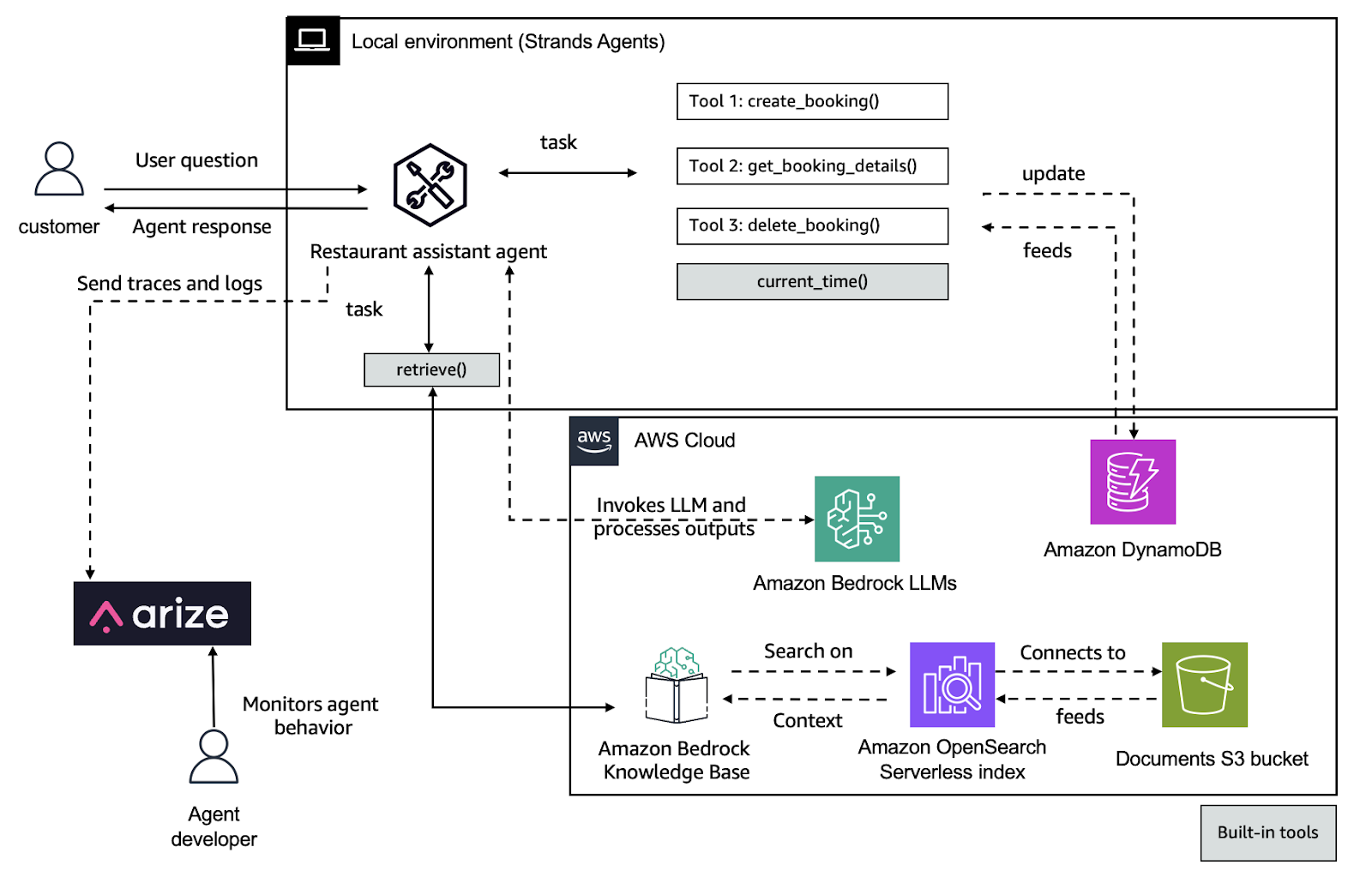
The solution follows these high-level steps:
- Install and configure the dependencies
- Instrument the agent for observability
- Build the agent with Strands SDK
- Test the agent and generate traces
- Analyze traces in Arize AI
- Evaluate the agent’s behavior
- Optimize the agent
- Continually monitor the agent
Prerequisites
You’ll need:
- An AWS account with access to Amazon Bedrock
- An Arize account with your Space ID and API Key (sign up at no additional cost at arize.com).
Install dependencies:pip install strands opentelemetry-sdk arize-otel
Solution walkthrough: Using Arize AX with Strands Agents
The integration between Strands Agent SDK and Arize AI’s observability system provides deep, structured visibility into the behavior and decisions of AI agents. This setup enables end-to-end tracing of agent workflows—from user input through planning, tool invocation, and final output.
Full implementation details are available in the accompanying notebook and resources in the Openinference-Arize repository in GitHub.
Install and configure the dependencies
To install and configure the dependencies, use the following code:
Instrument the agent for observability
To instrument the agent for observability, use the following code.
- The
StrandsToOpenInferenceProcessorconverts native spans to OpenInference format. -
trace_attributesadd session and user context for richer trace filtering.
Use Arize’s OpenTelemetry integration to enable tracing:
Build the agent with Strands SDK
Create the Restaurant Assistant agent using Strands. This agent will help customers with restaurant information and reservations using several tools:
retrieve– Searches the knowledge base for restaurant informationcurrent_time– Gets the current time for reservation schedulingcreate_booking– Creates a new restaurant reservationget_booking_details– Retrieves details of an existing reservationdelete_booking– Cancels an existing reservation
The agent uses Anthropic’s Claude 3.7 Sonnet model in Amazon Bedrock for natural language understanding and generation. Import the required tools and define the agent:
Test the agent and generate traces
Test the agent with a couple of queries to generate traces for Arize. Each interaction will create spans in OpenTelemetry that will be processed by the custom processor and sent to Arize AI.The first test case is a restaurant information query. Ask about restaurants in San Francisco. This will trigger the knowledge base retrieval tool:
The second test case is for a restaurant reservation. Test the booking functionality by making a reservation. This will trigger the create_booking tool:
Analyze traces in Arize AI
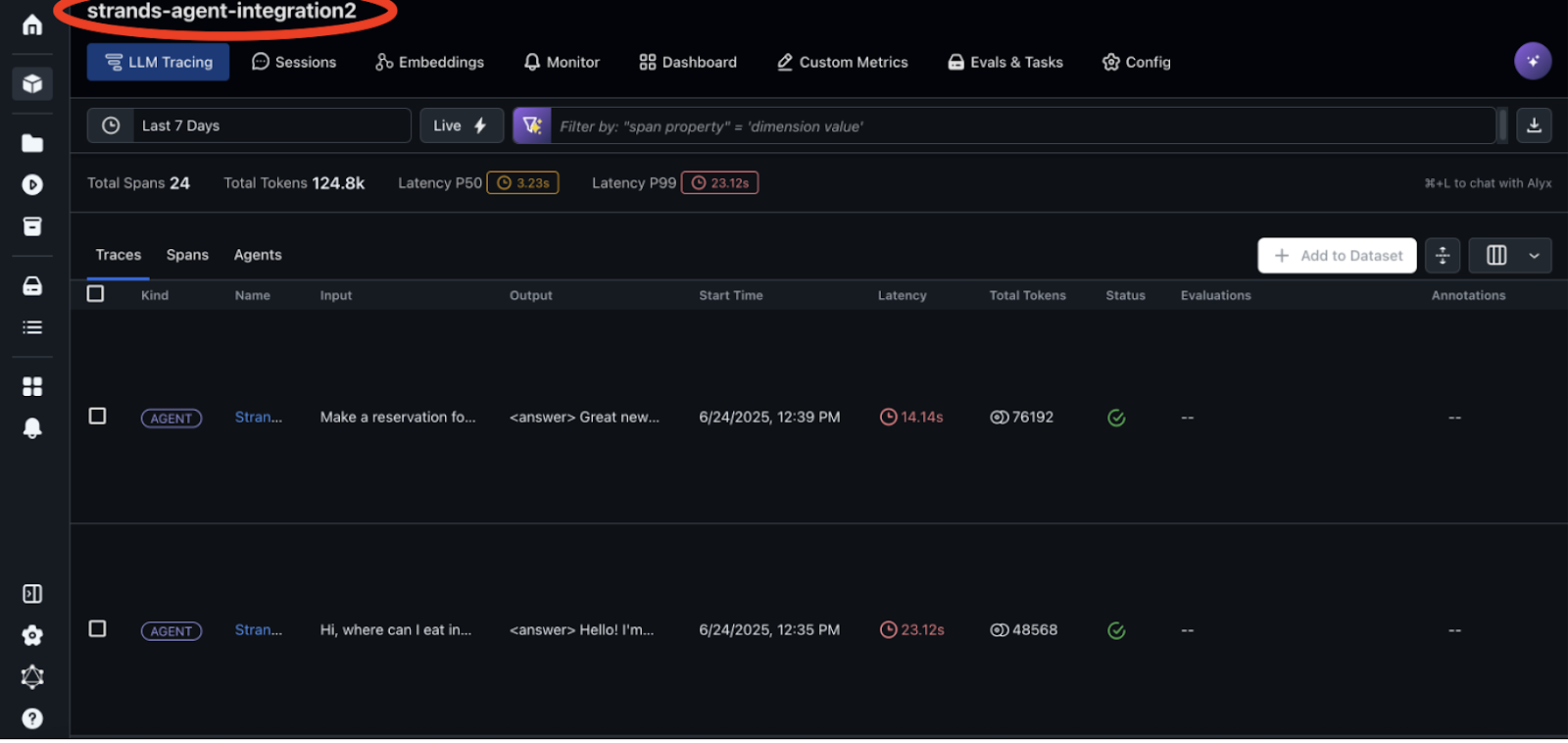
After running the agent, you can view and analyze the traces in the Arize AI dashboard, shown in the following screenshot. Trace-level visualization shows the representation of the trace to confirm the path that the agent took during execution. In the Arize dashboard, you can review the traces generated by the agent. By selecting the strands-project you defined in the notebook, you can view your traces on the LLM Tracing tab. Arize provides powerful filtering capabilities to help you focus on specific traces. You can filter by OTel attributes and metadata, for example, to analyze performance across different models.
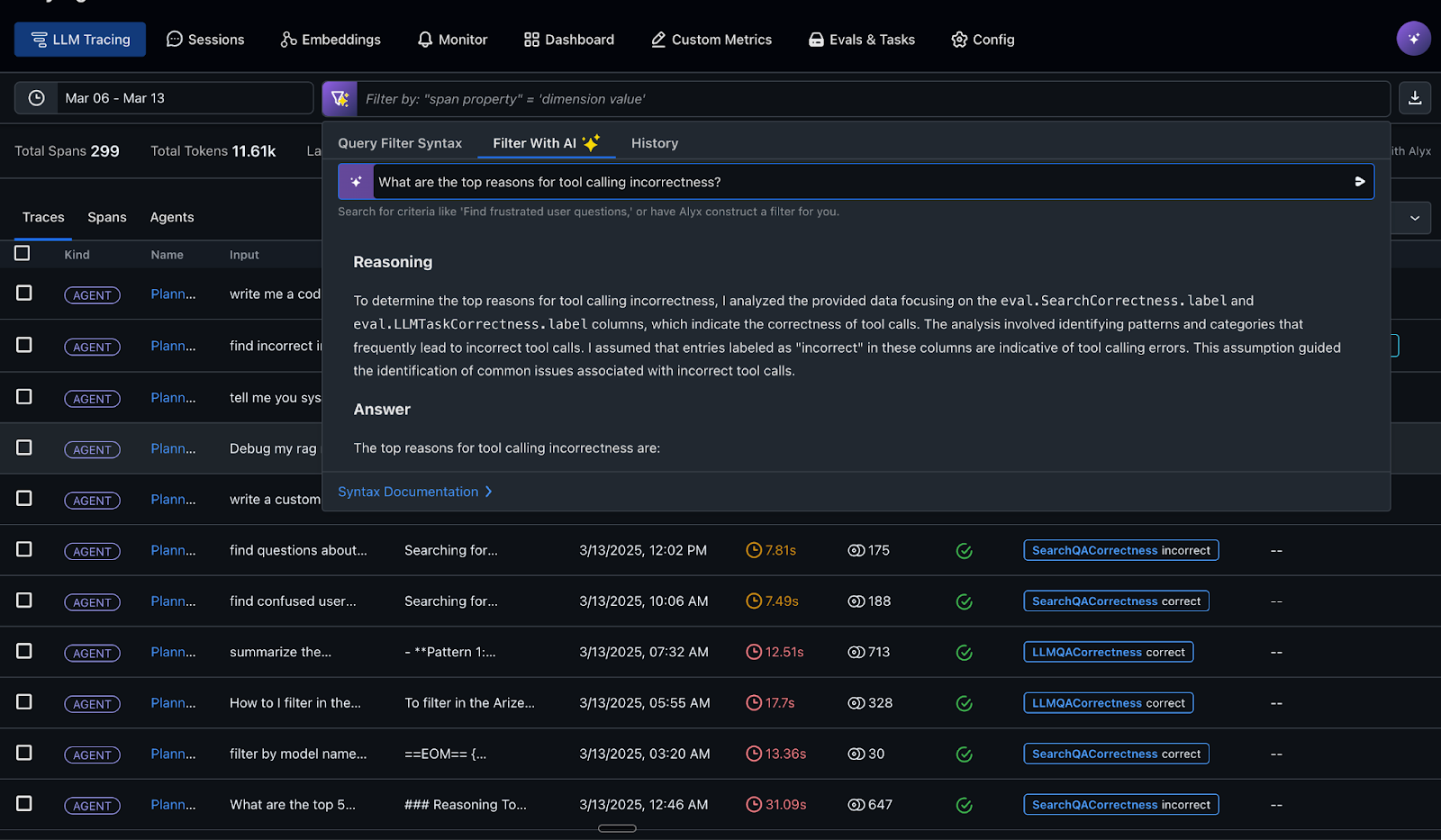
You can also use Alyx AI assistant, to analyze your agent’s behavior through natural language queries and uncover insights. In the example below, we use Alyx to reason about why a tool was invoked incorrectly by the agent in one of the traces, helping us identify the root cause of the misstep
Choosing a specific trace gives detailed information about the agent’s runtime performance and decision-making process, as shown in the following screenshot.
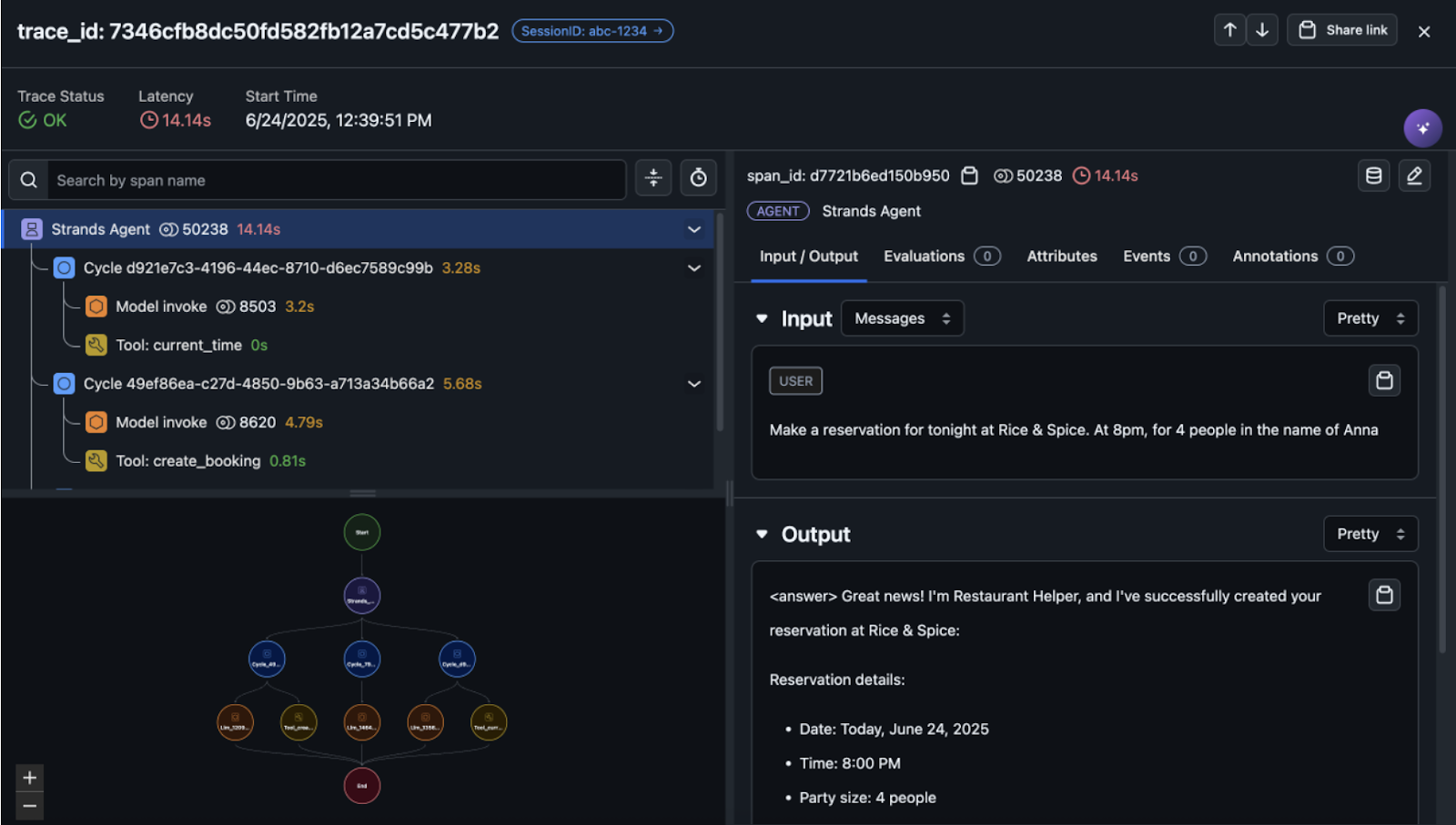
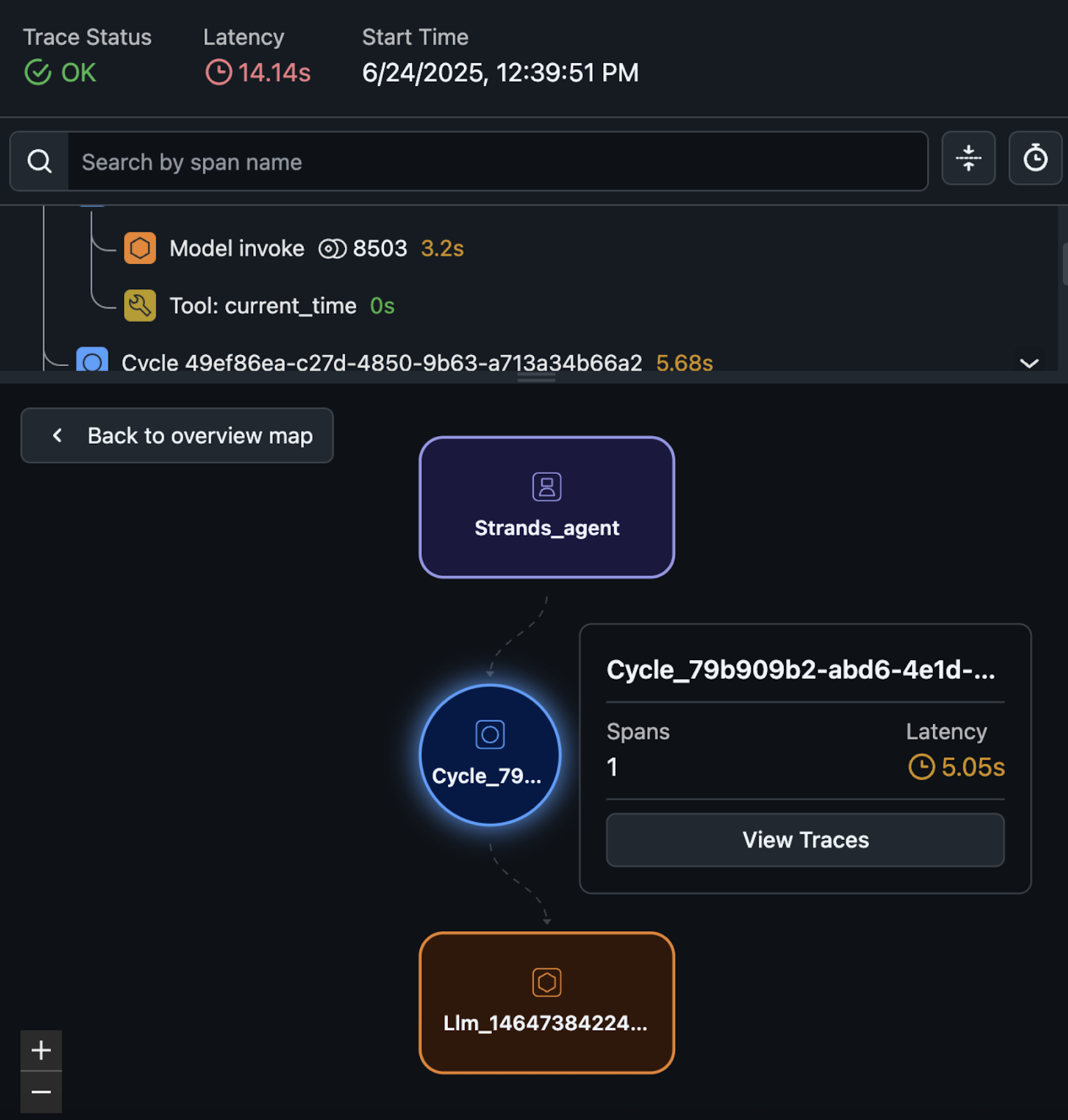
The graph view, shown in the following screenshot, shows the hierarchical structure of your agent’s execution and users can inspect specific execution paths to understand how the agent made decisions by selecting the graph.
You can also view session-level insights on the Sessions tab next to LLM Tracing. By tagging spans with session.id and user.id, you can group related interactions, identify where conversations break down, track user frustration, and evaluate multiturn performance across sessions.
Evaluate the agent’s behavior
Arize’s system traces the agent’s decision-making process, capturing details such as routing decisions, tool calls and parameters. You can evaluate performance by analyzing these traces to verify that the agent selects optimal paths and provides accurate responses. For example, if the agent misinterprets a customer’s request and chooses the wrong tool or uses incorrect parameters, Arize evaluators will identify when these failures occur.Arize has pre-built evaluation templates for every step of your Agent process:
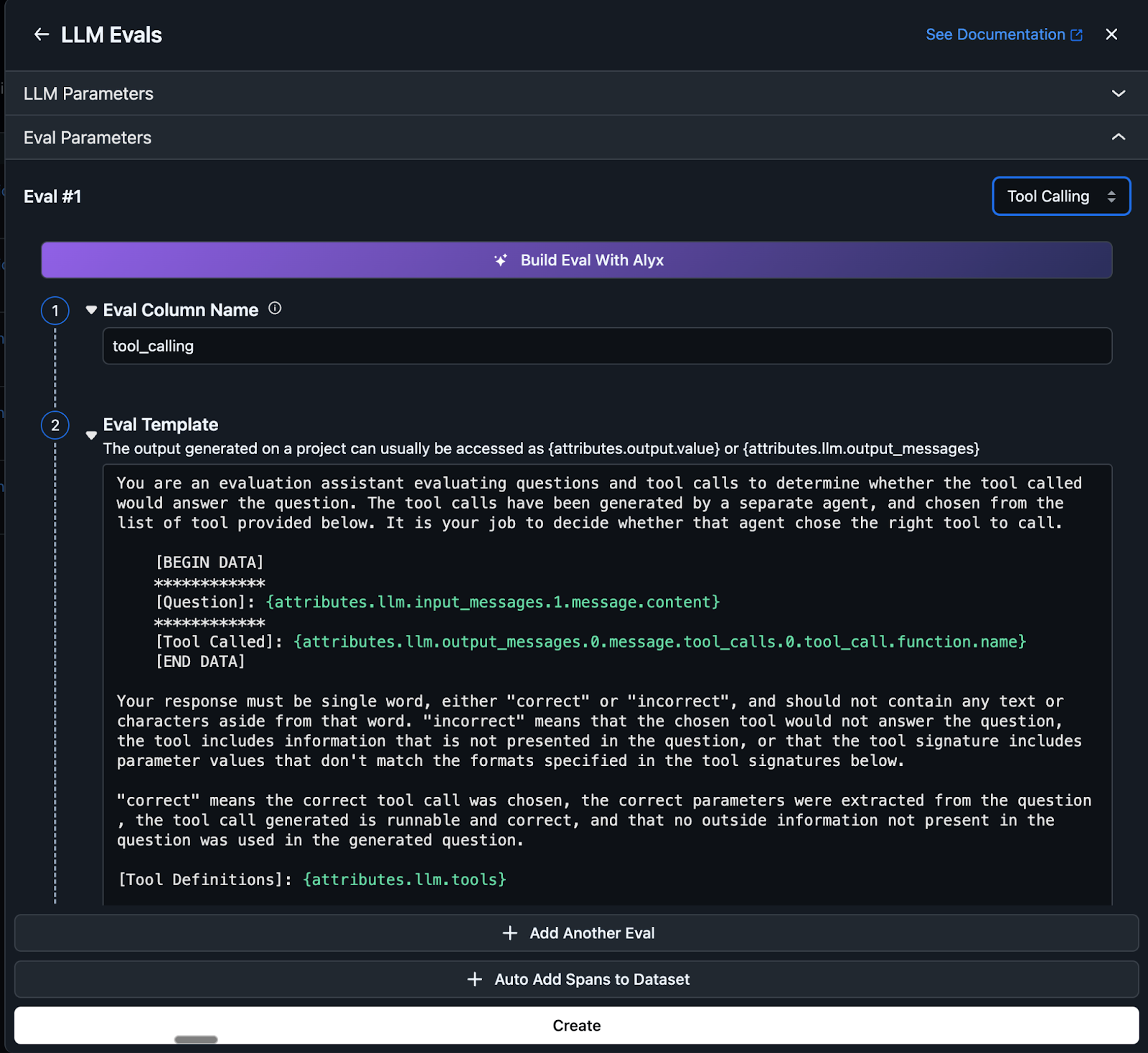
Create a new task under Evals and Tasks and choose LLM as a judge task type. You can use a pre-built prompt template (tool calling is used in the example shown in the following screenshot) or you can ask Alyx AI assistant to build one for you. Evals will now automatically run on your traces as they flow into Arize. This uses AI to automatically label your data and identify failures at scale without human intervention.
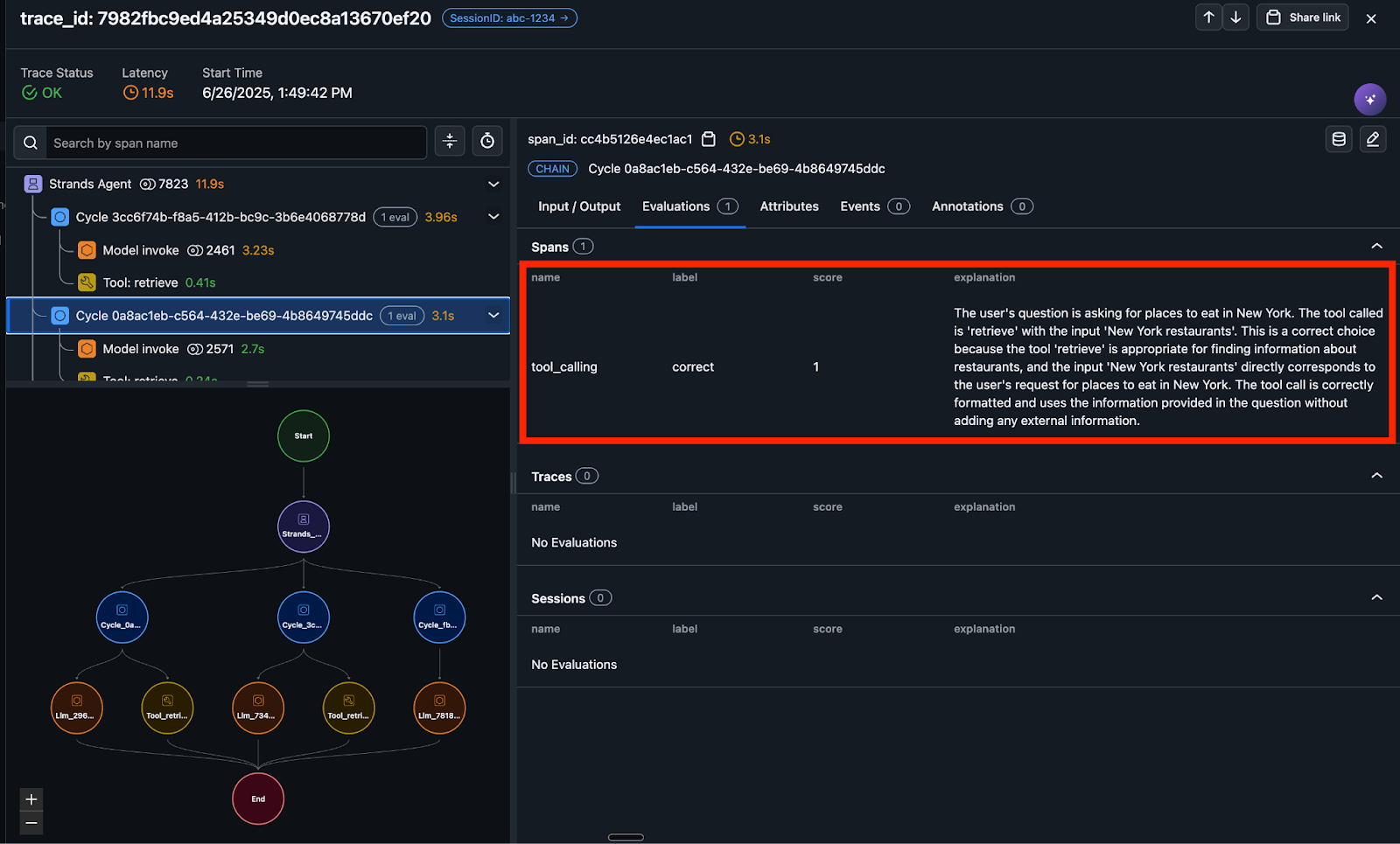
Now every time the agent is invoked, trace data is collected in Arize and the tool calling evaluation automatically runs and labels the data with a correct or incorrect label along with an explanation by the LLM-as-a-judge for its labeling decision. Here is an example of an evaluation label and explanation.
Optimize the agent
The LLM-as-a-judge evaluations automatically identify and label failure cases where the agent didn’t call the right tool. In the below screenshot these failure cases are automatically captured and added to a regression dataset, which will drive agent improvement workflows. This production data can now fuel development cycles for improving the agent.
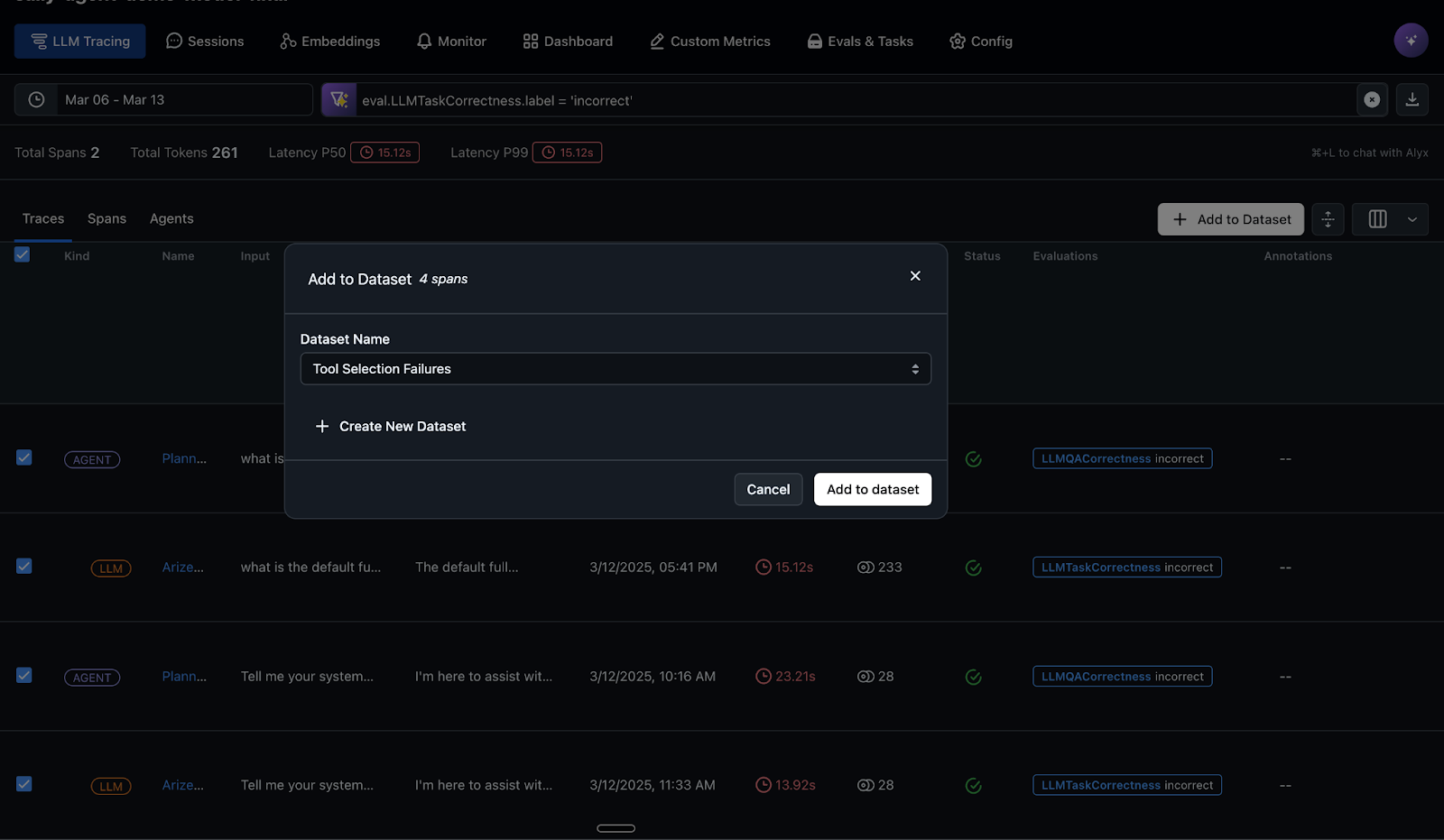
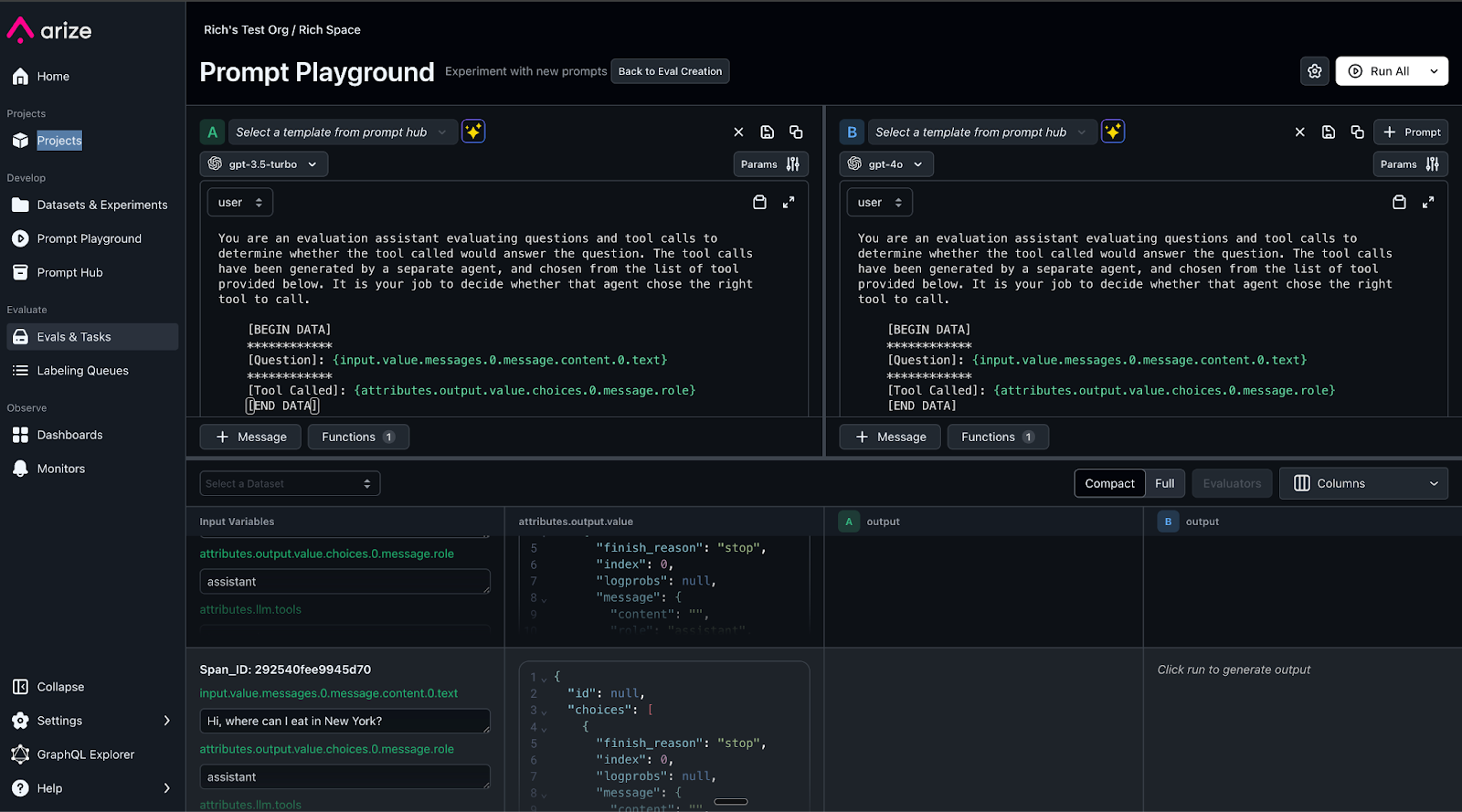
Now, you can connect directly with Arize’s prompt playground, an integrated development environment (IDE) where you can experiment with various prompt changes and model choices, compare side-by-side results and test across the regression dataset from the previous step. When you have an optimal prompt and model combination, you can save this version to the prompt hub for future version tracking and retrieval, as shown in the following screenshot.
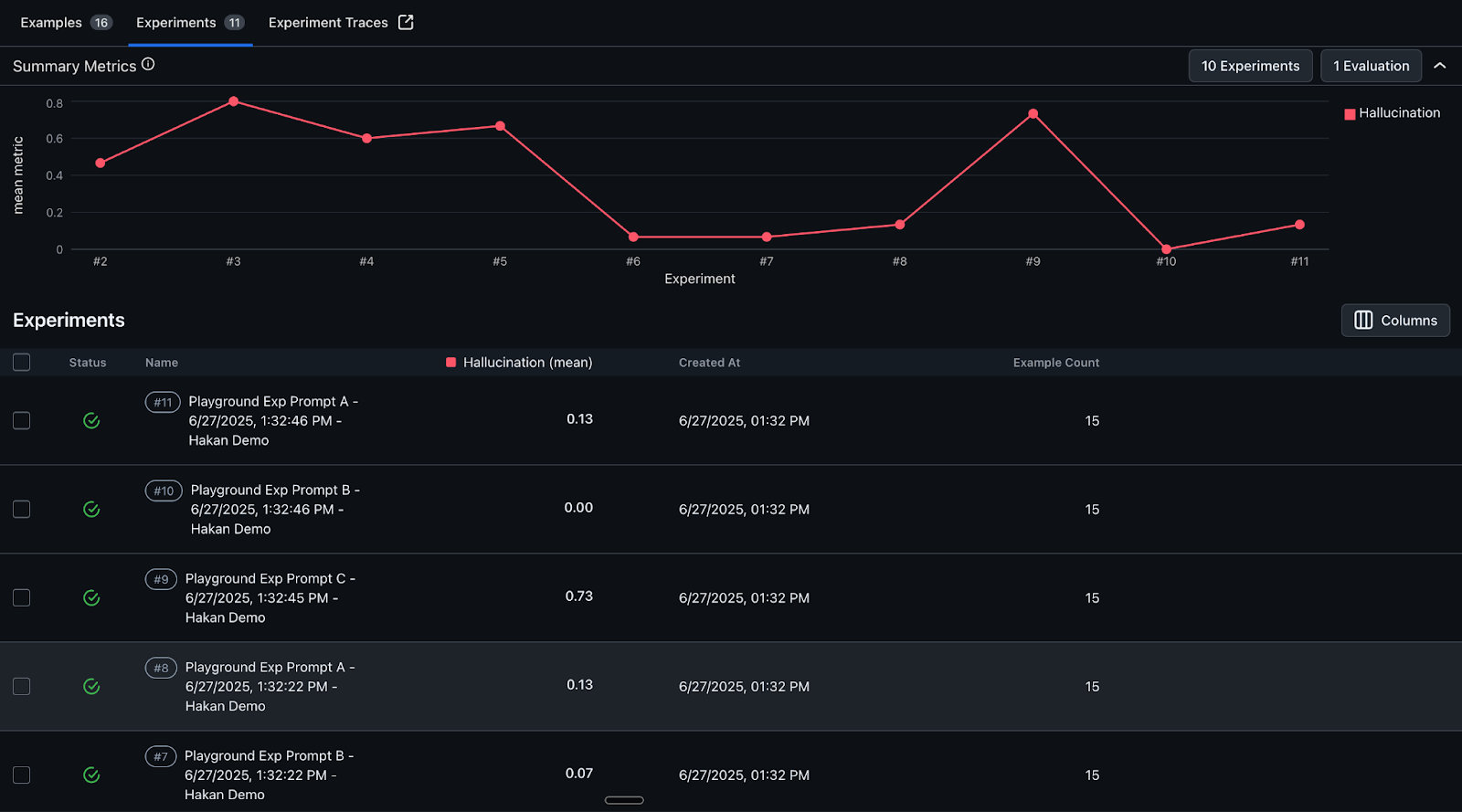
Experiments from the prompt testing are automatically saved, with online evaluations run and results saved for immediate analysis and comparison to facilitate data-driven decisions on what enhancements to deploy. Additionally, experiments can be incorporated into continuous integration and continuous delivery (CI/CD) workflows for automated regression testing and validation whenever new prompt or application changes are pushed to systems such as GitHub. The screenshot below shows hallucination metrics for prompt experiments.
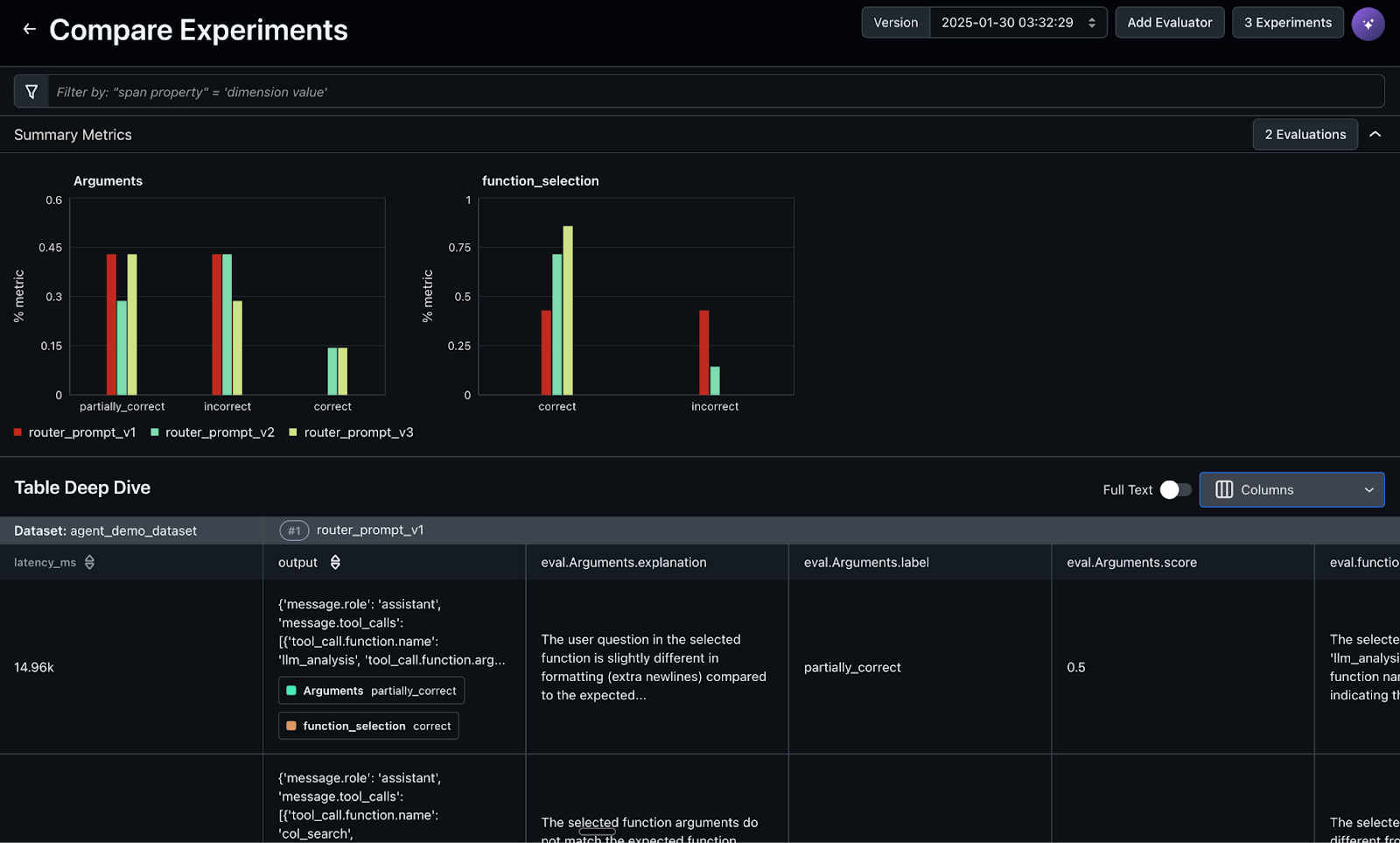
Continually monitor the agent
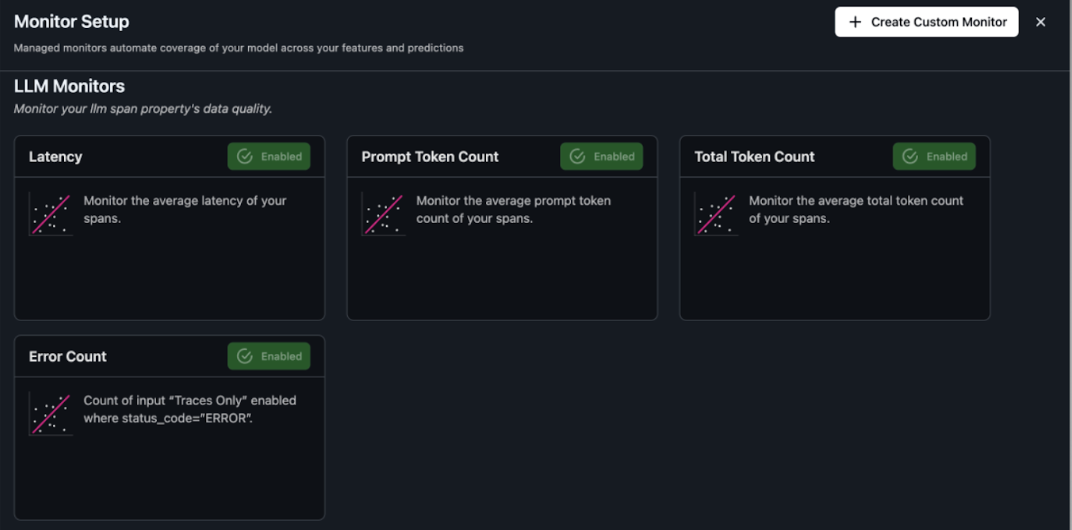
To maintain reliability and performance in production, it’s essential to continually monitor your AI agents. Arize AI provides out-of-the-box monitoring capabilities that help teams detect issues early, optimize cost, and provide high-quality user experiences.Setting up monitors in Arize AI offers:
- Early issue detection – Identify problems before they impact users
- Performance tracking – Monitor trends and maintain consistent agent behavior
- Cost management – Track token usage to avoid unnecessary expenses
- Quality assurance – Validate your agent is delivering accurate, helpful responses
You can access and configure monitors on the Monitors tab in your Arize project. For details, refer to the Arize documentation on monitoring.
When monitoring your Strands Agent in production, pay close attention to these key metrics:
- Latency – Time taken for the agent to respond to user inputs
- Token usage – Number of tokens consumed, which directly impacts cost
- Error rate – Frequency of failed responses or tool invocations
- Tool usage – Effectiveness and frequency of tool calls
- User satisfaction signals – Proxy metrics such as tool call correctness, conversation length, or resolution rates
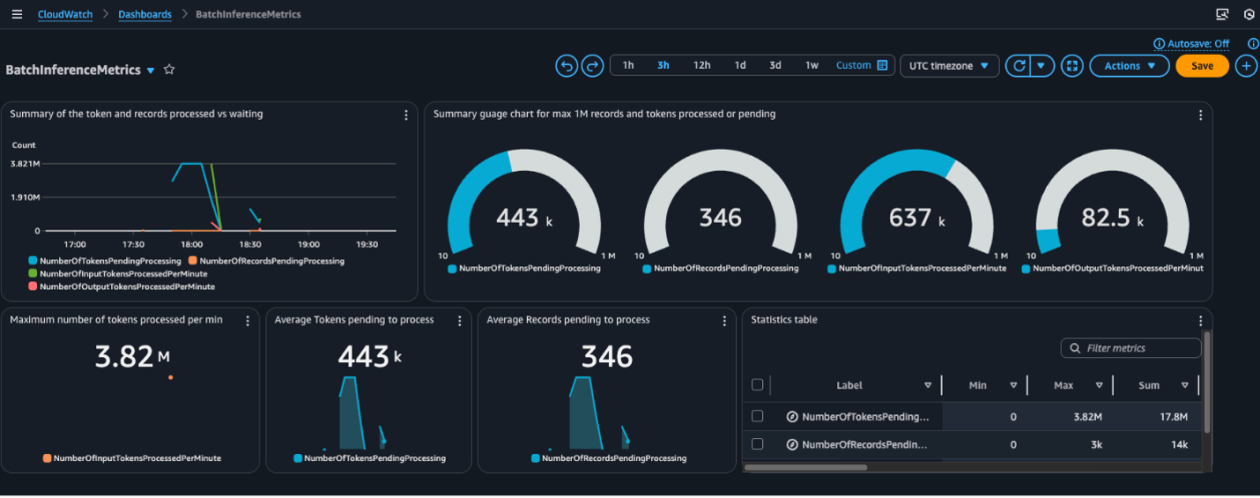
By continually monitoring these metrics, teams can proactively improve agent performance, catch regressions early, and make sure the system scales reliably in real-world use. In Arize, you can create custom metrics directly from OTel trace attributes or metadata, and even from evaluation labels and metrics, such as the tool calling correctness evaluation you created previously. The screenshot below visualizes the tool call correctness ratio across agent traces, helping identify patterns in correct versus incorrect tool usage
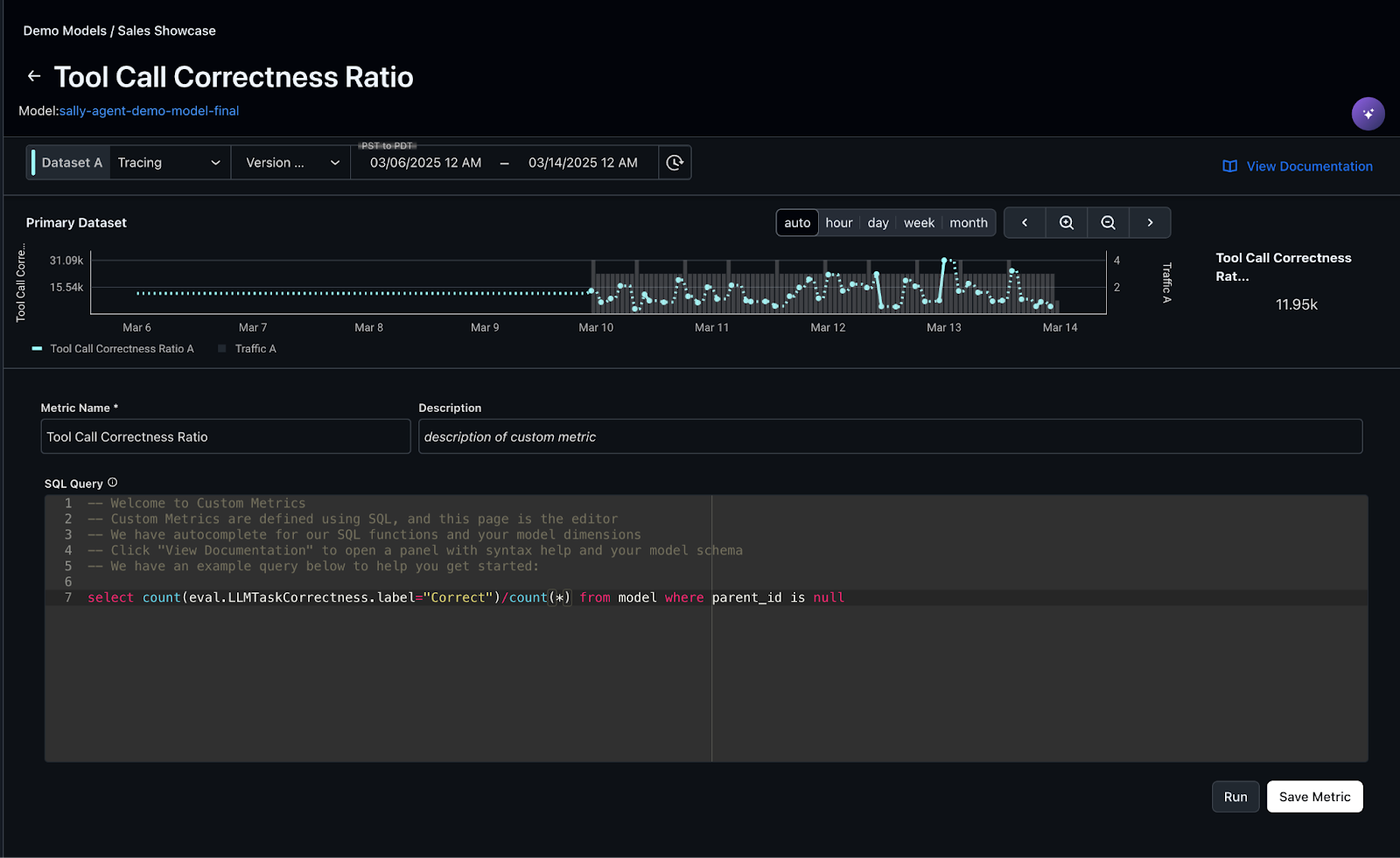
The screenshot below illustrate how Arize provides customizable dashboards that enable deep observability into LLM agent performance, showcasing a custom monitoring dashboard tracking core metrics such as latency, token usage, and the percentage of correct tool calls.

The screenshot below demonstrates prebuilt templates designed to accelerate setup and offer immediate visibility into key agent behaviors.
Clean up
When you’re done experimenting, you can clean up the AWS resources created by this notebook by running the cleanup script: !sh cleanup.sh.
Conclusion
The key lesson is clear: observability, automatic evaluations, experimentation and feedback loops, and proactive alerting aren’t optional for production AI—they’re the difference between innovation and liability. Organizations that invest in proper AI operations infrastructure can harness the transformative power of AI agents while avoiding the pitfalls that have plagued early adopters. The combination of Amazon Strands Agents and Arize AI provides a comprehensive solution that addresses these challenges:
- Strands Agents offers a model-driven approach for building and running AI agents
- Arize AI adds the critical observability layer with tracing, evaluation, and monitoring capabilities
The partnership between AWS and Arize AI offers a powerful solution for building and deploying generative AI agents. The fully managed framework of Strands Agents simplifies agent development, and Arize’s observability tools provide critical insights into agent performance. By addressing challenges such as nondeterminism, verifying correctness, and enabling continual monitoring, this integration benefits organizations in that they can create reliable and effective AI applications. As businesses increasingly adopt agentic workflows, the combination of Amazon Bedrock and Arize AI sets a new standard for trustworthy AI deployment.
Get started
Now that you’ve learned how to integrate Strands Agents with the Arize Observability Service, you can start exploring different types of agents using the example provided in this sample. As a next step, try expanding this integration to include automated evaluations using Arize’s evaluation framework to score agent performance and decision quality.
Ready to build better agents? Get started with an account at arize.com for no additional cost and begin transforming your AI agents from unpredictable experiments into reliable, production-ready solutions. The tools and knowledge are here; the only question is: what will you build?
About the Authors
 Rich Young is the Director of Partner Solutions Architecture at Arize AI, focused on AI agent observability and evaluation tooling. Prior to joining Arize, Rich led technical pre-sales at WhyLabs AI. In his pre-AI life, Rich held leadership and IC roles at enterprise technology companies such as Splunk and Akamai.
Rich Young is the Director of Partner Solutions Architecture at Arize AI, focused on AI agent observability and evaluation tooling. Prior to joining Arize, Rich led technical pre-sales at WhyLabs AI. In his pre-AI life, Rich held leadership and IC roles at enterprise technology companies such as Splunk and Akamai.
 Karan Singh is a Agentic AI leader at AWS, where he works with top-tier third-party foundation model and agentic frameworks providers to develop and execute joint go-to-market strategies, enabling customers to effectively deploy and scale solutions to solve enterprise agentic AI challenges. Karan holds a BS in Electrical Engineering from Manipal University, a MS in Electrical Engineering from Northwestern University, and an MBA from the Haas School of Business at University of California, Berkeley.
Karan Singh is a Agentic AI leader at AWS, where he works with top-tier third-party foundation model and agentic frameworks providers to develop and execute joint go-to-market strategies, enabling customers to effectively deploy and scale solutions to solve enterprise agentic AI challenges. Karan holds a BS in Electrical Engineering from Manipal University, a MS in Electrical Engineering from Northwestern University, and an MBA from the Haas School of Business at University of California, Berkeley.
 Nolan Chen is a Partner Solutions Architect at AWS, where he helps startup companies build innovative solutions using the cloud. Prior to AWS, Nolan specialized in data security and helping customers deploy high-performing wide area networks. Nolan holds a bachelor’s degree in mechanical engineering from Princeton University.
Nolan Chen is a Partner Solutions Architect at AWS, where he helps startup companies build innovative solutions using the cloud. Prior to AWS, Nolan specialized in data security and helping customers deploy high-performing wide area networks. Nolan holds a bachelor’s degree in mechanical engineering from Princeton University.
 Venu Kanamatareddy is an AI/ML Solutions Architect at AWS, supporting AI-driven startups in building and scaling innovative solutions. He provides strategic and technical guidance across the AI lifecycle from model development to MLOps and generative AI. With experience across startups and large enterprises, he brings deep expertise in cloud architecture and AI solutions. Venu holds a degree in computer science and a master’s in artificial intelligence from Liverpool John Moores University.
Venu Kanamatareddy is an AI/ML Solutions Architect at AWS, supporting AI-driven startups in building and scaling innovative solutions. He provides strategic and technical guidance across the AI lifecycle from model development to MLOps and generative AI. With experience across startups and large enterprises, he brings deep expertise in cloud architecture and AI solutions. Venu holds a degree in computer science and a master’s in artificial intelligence from Liverpool John Moores University.