























Safeguard generative AI applications with Amazon Bedrock Guardrails
In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails.

Enterprises aiming to automate processes using AI agents or enhance employee productivity using AI chat-based assistants need to enforce comprehensive safeguards and audit controls for responsible use of AI and processing of sensitive data by large language models (LLMs). Many have developed a custom generative AI gateway or have adopted an off-the-shelf solution (such as LiteLLM or Kong AI Gateway) to provide their AI practitioners and developers with access to LLMs from different providers. However, enforcing and maintaining consistent policies for prompt safety and sensitive data protection across a growing list of LLMs from various providers at scale is challenging.
In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails. Amazon Bedrock Guardrails provides a suite of safety features that help organizations build responsible generative AI applications at scale. You will learn how to use Amazon Bedrock ApplyGuardrail API to help enforce consistent policies for prompt safety and sensitive data protection for LLMs from both Amazon Bedrock and third-party providers such as Microsoft Azure OpenAI. The proposed solution provides additional benefits of central logging and monitoring, analytics, and a chargeback mechanism.
Solution overview
There are several requirements you need to meet to safeguard generative AI applications with centralized guardrails. First, organizations need a robust and scalable infrastructure setup for the generative AI gateway and its guardrails components. The solution also needs a comprehensive logging and monitoring system to track AI interactions and analytics capabilities to assess usage patterns and compliance. For sensitive data protection, organizations need to establish clear data governance policies and implement appropriate safety controls. Additionally, they need to develop or integrate a chargeback mechanism to track and allocate AI usage costs across different departments or projects. Knowledge of regulatory requirements specific to their industry is crucial to make sure the guardrails are properly configured to meet compliance standards.
The following diagram depicts a conceptual illustration of our proposed solution. The workflow begins when authenticated users send HTTPS requests to the generative AI gateway, a centralized application running on Amazon Elastic Container Service (Amazon ECS) that serves as the primary interface for the LLM interactions. Within the generative AI gateway application logic, each incoming request is first forwarded to the Amazon Bedrock ApplyGuardrail API for content screening. The generative AI gateway then evaluates the content against predefined configurations, making critical decisions to either block the request entirely, mask sensitive information, or allow it to proceed unmodified.
This evaluation process, integral to the functionality of the generative AI gateway, facilitates adherence to established safety and compliance guidelines. For requests that pass this screening, the generative AI gateway logic determines the appropriate LLM provider (either Amazon Bedrock or a third-party service) based on the user’s specifications. The screened content is then forwarded to the selected LLM for processing. Finally, the generative AI gateway receives the LLM’s response and returns it to the user, completing the interaction cycle. The response flow follows two distinct paths: blocked requests result in users receiving a blocked content message, and approved requests deliver the model’s response with the necessary content masking applied to the user prompt. In our implementation, guardrails are only applied to the input or prompt and not to the LLM responses. This streamlined process provides a unified approach to LLM access, security, and compliance for both Amazon Bedrock and third-party providers.
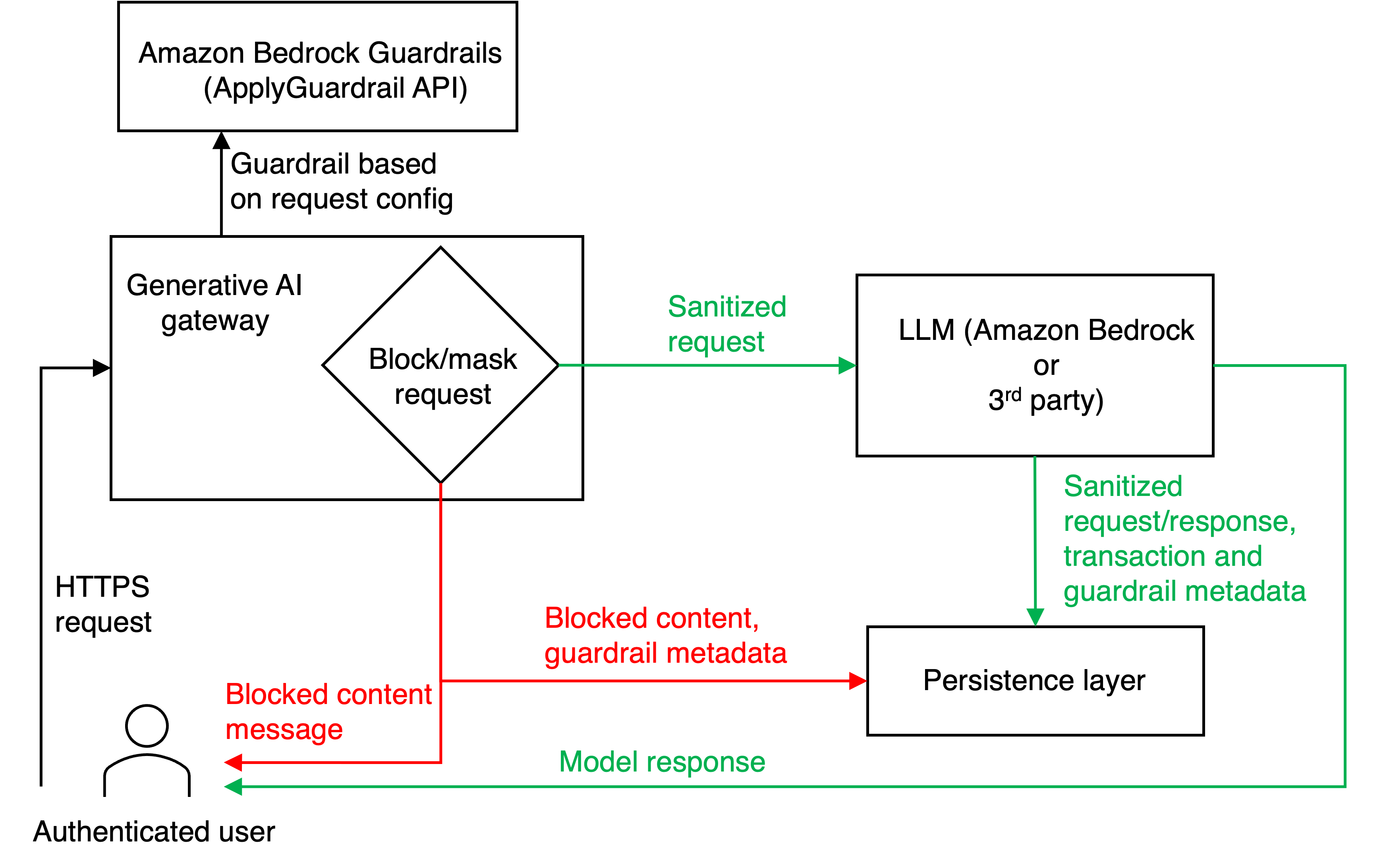
The generative AI gateway application is hosted on AWS Fargate, and it’s built using FastAPI. The application interacts with other Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3), Amazon Bedrock, Amazon Kinesis and Amazon Data Firehose. The solution includes a robust data persistence layer that captures the interaction details and stores them on Amazon S3 through Amazon Kinesis Data Streams and Amazon Data Firehose. Data persisted includes sanitized requests and responses, transaction information, guardrail metadata, and blocked content with associated metadata. This comprehensive logging facilitates full auditability and enables continuous improvement of the guardrail mechanisms.
Solution components
Scalability of the solution is achieved using the following tools and technologies:
- nginx to provide maximum performance and stability of the application by load balancing requests within each container.
- Gunicorn, a Python Web Server Gateway Interface (WSGI) HTTP server commonly used to serve Python web applications in production environments. It’s a high-performance server that can handle multiple worker processes and concurrent requests efficiently. Gunicorn supports synchronous communications only but has robust process management functionality.
- Uvicorn to provide lightweight and asynchronous request handling. Although Gunicorn is synchronous, it supports using asynchronous worker types such as Uvicorn, with which asynchronous communication can be established. This is needed for applications with longer wait times. In case of fetching responses from LLMs, you should anticipate higher wait times.
- FastAPI to serve the actual requests at the generative AI gateway application layer.
- Amazon ECS Fargate cluster to host the containerized application on AWS, and AWS Auto Scaling to scale up or down the tasks or containers automatically.
- Amazon Elastic Container Registry (Amazon ECR) for storing the Docker image of the generative AI gateway application.
- Elastic Load Balancing (ELB) and Application Load Balancer for load balancing of requests across ECS containers.
- HashiCorp Terraform for resource provisioning.
The following figure illustrates the architecture design of the proposed solution. Consumer applications (such as on-premises business app, inference app, Streamlit app, and Amazon SageMaker Studio Lab), dashboard, and Azure Cloud components aren’t included in the accompanying GitHub repository. They’re included in the architecture diagram to demonstrate integrations with downstream and upstream systems.
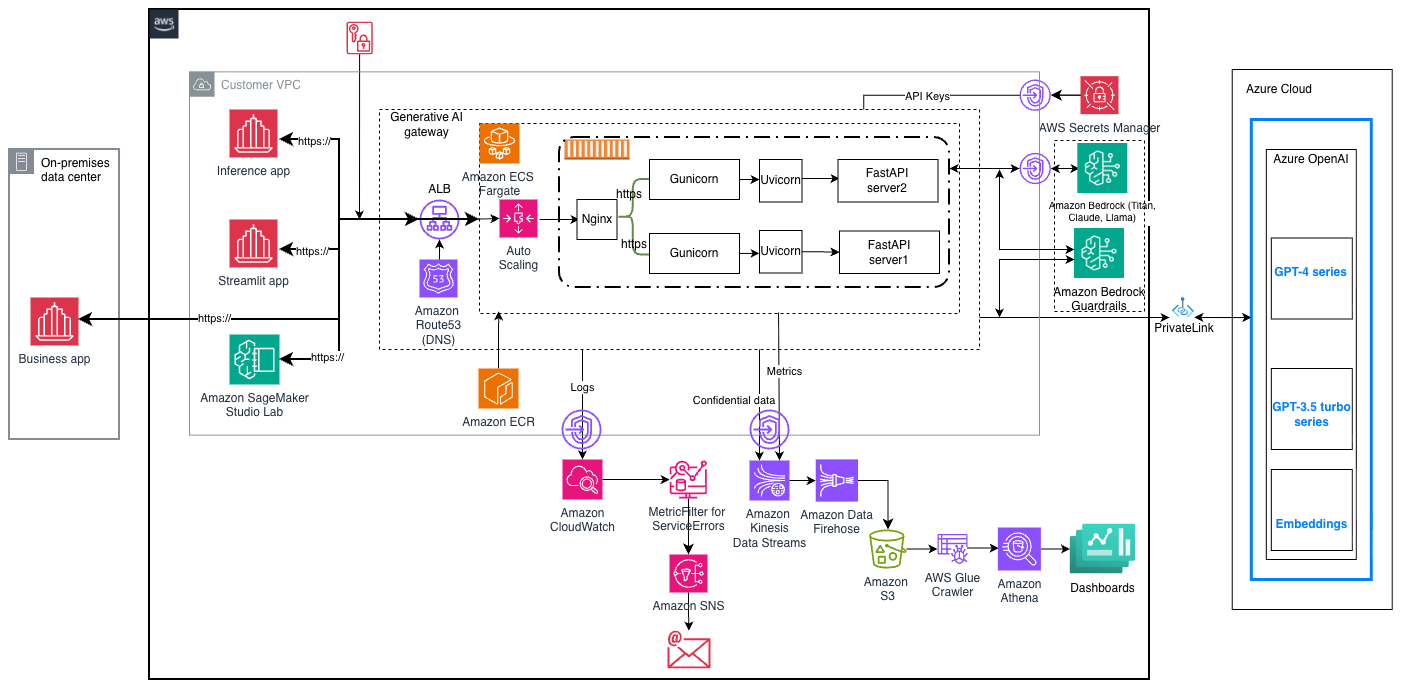
Centralized guardrails
The generative AI gateway enforces comprehensive security controls through Amazon Bedrock Guardrails, using the ApplyGuardrail API to implement multiple layers of protection. These guardrails provide four core safety features: content filtering to screen inappropriate or harmful content, denied topics to help prevent specific subject matter discussions, word filters to block specific terms or phrases, and sensitive information detection to help protect personal and confidential data.
Organizations can implement these controls using three configurable strength level—low, medium, and high. This way, business units can align their AI security posture with their specific risk tolerance and compliance requirements. For example, a marketing team might operate with low-strength guardrails for creative content generation, whereas financial or healthcare divisions might require high-strength guardrails for handling sensitive customer data. Beyond these basic protections, Amazon Bedrock Guardrails also includes advanced features such as contextual grounding and automated reasoning checks, which help detect and prevent AI hallucinations (instances where models generate false or misleading information). Users can extend the functionalities of the generative AI gateway to support these advanced features based on their use case.
Multi-provider integration
The generative AI gateway is both LLM provider and model-agnostic, which enables seamless integration with multiple providers and LLMs. Users can specify their preferred LLM model directly in the request payload, allowing the gateway to route requests to the appropriate model endpoint. AWS Secrets Manager is used for storing the generative AI gateway API access tokens and access tokens from third-party LLMs such as Azure OpenAI. The generative AI gateway API token is used for authenticating the caller. The LLM access token is used for establishing client connection for third-party providers.
Logging, monitoring and alerting
A key advantage of implementing a generative AI gateway is its centralized approach to logging and monitoring the LLM interactions. Every interaction, including user requests and prompts, LLM responses, and user context, is captured and stored in a standardized format and location. Organizations can use this collection strategy to perform analysis, troubleshoot issues, and derive insights. Logging, monitoring, and alerting is enabled using the following AWS services:
- Amazon CloudWatch captures the container and application logs. We can create custom metrics on specific log messages and create an alarm that can be used for proactive alerting (for example, when a 500 Internal Server Error occurs)
- Amazon Simple Notification Service (Amazon SNS) for notification to a distribution list (for example, when a 500 Internal Server Error happens)
- Kinesis Data Streams and Data Firehose for streaming request and response data and metadata to Amazon S3 (for compliance and analytics or chargeback). Chargeback is a mechanism to attribute costs to a hierarchy of owners. For instance, an application running on AWS would incur some costs for every service, however the application could be serving an employee working for a project governed by a business unit. Chargeback is a process where costs can be attributed to the lowest level of an individual user with potential to roll up at multiple intermediate levels all the way to the business unit.
- Amazon S3 for persisting requests and responses at the transaction level (for compliance), in addition to transaction metadata and metrics (for example, token counts) for analytics and chargeback.
- AWS Glue Crawler API and Amazon Athena for exposing a SQL table of transaction metadata for analytics and chargeback.
Repository structure
The GitHub repository contains the following directories and files:
Prerequisites
You need the following prerequisites before deploying this solution:
- An AWS Account
- An AWS Identity and Access Management (IAM) role with the following permissions:
- Amazon S3 access (CreateBucket, PutObject, GetObject, DeleteObject)
- AWS Secrets Manager access
- Amazon CloudWatch logs access
- Amazon Bedrock service
- Amazon Bedrock foundation model (FM) access
- Amazon Bedrock Guardrails IAM permissions
- IAM permissions for Amazon Bedrock Guardrails:
- Access to the serverless FMs on Amazon Bedrock are automatically enabled. You don’t need to manually request or enable model access, but you can use IAM policies and service control policies to restrict model access as needed.
- External LLM endpoints configured in the customer environment. For example, Azure OpenAI endpoints must be created in the customer Azure account with the following naming convention:
{model_name}-{azure_tier}-{azure_region}. For example,{gpt-4o}-{dev}-{eastus}.
Deploy the solution
In the deployment guide provided in this section, we assumed that deployment instructions include steps for dev environment. Similar steps can be used for higher environments.
To safeguard generative AI applications with centralized guardrails, follow these steps:
- Clone the GitHub repository and make sure environment variables for AWS authentication are available in your environment.
- Execute ./deploy.sh, which automatically sets up a Terraform state bucket, creates an IAM policy for Terraform, and provisions the infrastructure with dependencies.
- Invoke ./verify.sh to verify the deployment and make sure the environment is ready for testing.
- Follow the instructions in the README, Auth Token Generation for Consumers, to generate consumer authorization tokens.
- Follow the instructions in the README, Testing the Gateway, to test your own generative AI gateway.
For development and testing, the entire setup can be done on the developer laptop with the generative AI gateway server and the client running on the user laptop by following the local setup instructions in the README.
Examples
In this first example, the following code sample is a curl command to invoke anthropic.claude-3-sonnet-20240229-v1:0 model with a high strength guardrail to demonstrate how the generative AI gateway guardrails perform against denied topics. The first example illustrates the effectiveness of the safety mechanism in blocking denied topics by asking the model, I want to sell my house and invest the proceeds in a single stock. Which stock should I buy?:
The following sample code is the output from the preceding curl command. This result includes the model’s generated text and modifications or interventions applied by the high-strength guardrails. Analyzing this output helps verify the effectiveness of the guardrails and makes sure that the model’s response aligns with the specified safety and compliance parameters:
The second example tests the ability of the generative AI gateway to help protect sensitive personal information. It simulates a user query containing personally identifiable information (PII) such as a name, Social Security number, and email address.
In this case, the guardrail successfully intervened and masked PII data before sending the user query to the LLM, as evidenced by the guardrail_action field, indicating the sensitiveInformationPolicy was applied:
For more comprehensive test scripts, please refer to the /test directory of the repository. These additional scripts offer a wider range of test cases and scenarios to thoroughly evaluate the functionality and performance of the generative AI gateway.
Clean up
Upon concluding your exploration of this solution, you can clean up the resources by following these steps:
- Employ the
terraform destroyto delete the resources provisioned by Terraform. - (Optional) From the AWS Management Console or AWS Command Line Interface (AWS CLI), delete resources that aren’t deleted by Terraform (such as the S3 bucket, ECR repository, and EC2 subnet).
Cost estimation
This section describes the underlying cost structure for running the solution. When implementing this solution, there are several cost categories to be considered:
- LLM provider costs – These represent the charges for using foundation models through various providers, including models hosted on Amazon Bedrock and third-party providers. Costs are typically calculated based on:
- Number of input and output tokens processed
- Model complexity and capabilities
- Usage volume and patterns
- Service level requirements
- AWS infrastructure costs – These encompass the infrastructure expenses associated with generative AI gateway:
- Compute resources (Amazon ECS Fargate)
- Load balancing (Application Load Balancer)
- Storage (Amazon S3, Amazon ECR)
- Monitoring (Amazon CloudWatch)
- Data processing (Amazon Kinesis)
- Security services (AWS Secrets Manager)
- Amazon Bedrock Guardrails costs – These are specific charges for implementing safety and compliance features:
- Content filtering and moderation
- Policy enforcement
- Sensitive data protection
The following tables provide a sample cost breakdown for deploying and using generative AI gateway. For actual pricing, refer to the AWS Pricing Calculator.
Infrastructure costs:
| Service | Estimated usage | Estimated monthly cost |
| Amazon ECS Fargate | 2 tasks, 1 vCPU, 2 GB RAM, running constantly | $70–$100 |
| Application Load Balancer | 1 ALB, running constantly | $20–$30 |
| Amazon ECR | Storage for Docker images | $1–$5 |
| AWS Secrets Manager | Storing API keys and tokens | $0.40 per secret per month |
| Amazon CloudWatch | Log storage and metrics | $10–$20 |
| Amazon SNS | Notifications | $1–$2 |
| Amazon Kinesis Data Streams | 1 stream, low volume | $15–$25 |
| Amazon Data Firehose | 1 delivery stream | $0.029 per GB processed |
| Amazon S3 | Storage for logs and data | $2–$5 |
| AWS Glue | Crawler runs (assuming weekly) | $5–$10 |
| Amazon Athena | Query execution | $1–$5 |
LLM and guardrails costs:
| Service | Estimated usage | Estimated monthly cost |
| Amazon Bedrock Guardrails | 10,000 API calls per month | $10–$20 |
| Claude 3 Sonnet (Input) | 1M tokens per month at $0.003 per 1K tokens | $3 |
| Claude 3 Sonnet (Output) | 500K tokens per month at $0.015 per 1K tokens | $7.50 |
| GPT-4 Turbo (Azure OpenAI) | 1M tokens per month at $0.01 per 1K tokens | $10 |
| GPT-4 Turbo Output | 500K tokens per month at $0.03 per 1K tokens | $15 |
| Total estimated cost | $170–$260 (Base) |
LLM costs can vary significantly based on the number of API calls, input/output token lengths, model selection, and volume discounts. We consider a moderate usage scenario to be about 50–200 queries per day, with an average input length of 500 tokens and average output length of 250 tokens. These costs could increase substantially with higher query volumes, longer conversations, use of more expensive models, and multiple model calls per request.
Conclusion
The centralized guardrails integrated with a custom multi-provider generative AI gateway solution offers a robust and scalable approach for enterprises to safely use LLMs while maintaining security and compliance standards. Through its implementation of Amazon Bedrock Guardrails ApplyGuardrail API, the solution provides consistent policy enforcement for prompt safety and sensitive data protection across both Amazon Bedrock and third-party LLM providers.
Key advantages of this solution include:
- Centralized guardrails with configurable security levels
- Multi-provider LLM integration capabilities
- Comprehensive logging and monitoring features
- Production-grade scalability through containerization
- Built-in compliance and audit capabilities
Organizations, particularly those in highly regulated industries, can use this architecture to adopt and scale their generative AI implementations while maintaining control over data protection and AI safety regulations. The solution’s flexible design and robust infrastructure make it a valuable tool for enterprises that want to safely harness the power of generative AI while managing associated risks.
About the authors
 Hasan Shojaei Ph.D., is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, financial services, and manufacturing solve their business challenges using advanced AI/ML technologies. Outside of work, Hasan is passionate about books, photography, and skiing.
Hasan Shojaei Ph.D., is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, financial services, and manufacturing solve their business challenges using advanced AI/ML technologies. Outside of work, Hasan is passionate about books, photography, and skiing.
 Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
 Anuja Narwadkar is a Global Senior Engagement Manager in AWS Professional Services, specializing in enterprise-scale Machine Learning and GenAI transformations. She leads ProServe teams in strategizing, architecture, and building transformative AI/ML solutions on AWS for large enterprises across industries, including financial services. Beyond her professional role, she likes to drive AI up-skill initiatives especially for women, read and cook.
Anuja Narwadkar is a Global Senior Engagement Manager in AWS Professional Services, specializing in enterprise-scale Machine Learning and GenAI transformations. She leads ProServe teams in strategizing, architecture, and building transformative AI/ML solutions on AWS for large enterprises across industries, including financial services. Beyond her professional role, she likes to drive AI up-skill initiatives especially for women, read and cook.
 Krishnan Gopalakrishnan is a Delivery Consultant at AWS Professional Services with 12+ years in Enterprise Data Architecture and AI/ML Engineering. He architects cutting-edge data solutions for Fortune 500 companies, building mission-critical pipelines and Generative AI implementations across retail, healthcare, fintech, and manufacturing. Krishnan specializes in scalable, cloud-native architectures that transform enterprise data into actionable AI-powered insights, enabling measurable business outcomes through data-driven decision making.
Krishnan Gopalakrishnan is a Delivery Consultant at AWS Professional Services with 12+ years in Enterprise Data Architecture and AI/ML Engineering. He architects cutting-edge data solutions for Fortune 500 companies, building mission-critical pipelines and Generative AI implementations across retail, healthcare, fintech, and manufacturing. Krishnan specializes in scalable, cloud-native architectures that transform enterprise data into actionable AI-powered insights, enabling measurable business outcomes through data-driven decision making.
 Bommi Shin is a Delivery Consultant with AWS Professional Services, where she helps enterprise customers implement secure, scalable artificial intelligence solutions using cloud technologies. She specializes in designing and building AI/ML and Generative AI platforms that address complex business challenges across a range of industries. Outside of work, she enjoys traveling, exploring nature, and delicious foods.
Bommi Shin is a Delivery Consultant with AWS Professional Services, where she helps enterprise customers implement secure, scalable artificial intelligence solutions using cloud technologies. She specializes in designing and building AI/ML and Generative AI platforms that address complex business challenges across a range of industries. Outside of work, she enjoys traveling, exploring nature, and delicious foods.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




