


![[July 23] Sea Palace Adventure, Heidel Ball Hot Time & Celebration Feast!](https://clan.fastly.steamstatic.com/images/28674304/f27c083df760b373c0d2c4bcdca3353ea861312d.png?#)




















Scale creative asset discovery with Amazon Nova Multimodal Embeddings unified vector search
In this post, we describe how you can use Amazon Nova Multimodal Embeddings to retrieve specific video segments. We also review a real-world use case in which Nova Multimodal Embeddings achieved a recall success rate of 96.7% and a high-precision recall of 73.3% (returning the target content in the top two results) when tested against a library of 170 gaming creative assets. The model also demonstrates strong cross-language capabilities with minimal performance degradation across multiple languages.

Gaming companies face an unprecedented challenge in managing their advertising creative assets. Modern gaming companies produce thousands of video advertisements for A/B testing campaigns, with some organizations maintaining libraries with more than 100,000 video assets that grow by thousands of assets monthly. These assets are critical for user acquisition campaigns, where finding the right creative asset can make the difference between a successful launch and a costly failure.
In this post, we describe how you can use Amazon Nova Multimodal Embeddings to retrieve specific video segments. We also review a real-world use case in which Nova Multimodal Embeddings achieved a recall success rate of 96.7% and a high-precision recall of 73.3% (returning the target content in the top two results) when tested against a library of 170 gaming creative assets. The model also demonstrates strong cross-language capabilities with minimal performance degradation across multiple languages.
Traditional methods for sorting, storing, and searching for creative assets can’t meet the dynamic needs of creative teams. Traditionally, creative assets have been manually tagged to enable keyword-based search and then organized in folder hierarchies, which are manually searched for the desired assets. Keyword-based search systems require manual tagging that is both labor-intensive and inconsistent. While large language model (LLM) solutions such as LLM-based automatic tagging offer powerful multimodal understanding capabilities, they can’t scale to meet the needs of creative teams to perform varied, real-time searches across massive asset libraries.
The core challenge lies in semantic search for creative asset discovery. The search needs to support unpredictable search requirements that can’t be pre-organized with fixed prompts or predefined tags. When creative professionals search for the character is pinched away by hand, or A finger taps a card in the game, the system must understand not just the keywords, but the semantic meaning across different media types.
This is where Nova Multimodal Embeddings transforms the landscape. Nova Multimodal Embeddings is a state-of-the-art multimodal embedding model for agentic Retrieval-Augmented Generation (RAG) and semantic search applications with a unified vector space architecture, available in Amazon Bedrock. More importantly, the model generates embeddings directly from video assets without requiring intermediate conversion steps or manual tagging.
Nova Multimodal Embeddings video embedding generation enables true semantic understanding of video content. Nova Multimodal Embeddings can analyze the visual scenes, actions, objects, and context within videos to create rich semantic representations. When you search for the character is pinched away by hand, the model understands the specific action, visual elements, and context described—not just keyword matches. This semantic capability avoids the fundamental limitations of keyword-based search systems, so that creative teams can find relevant video content using natural language descriptions that would be impossible to tag or organize in advance with traditional approaches.
Solution overview
In this section, you learn about Nova Multimodal Embeddings and its key capabilities, advantages, and integration with AWS services to create a comprehensive multimodal search architecture. The multimodal search architecture described in this post provides:
- Input flexibility: Accepts text queries, uploaded images, videos, and audio files as search inputs
- Cross-modal retrieval: Users can find video, image, and audio content using text descriptions or use uploaded images to discover similar visual content across multiple media types
- Output precision: Returns ranked results with similarity scores, precise timestamps for video segments, and detailed metadata
- Synchronous search and retrieval: Provides immediate search results through pre-computed embeddings and efficient vector similarity matching
- Unified asynchronous architecture: Search queries are processed asynchronously to handle varying processing times and provide a consistent user experience
Nova Multimodal Embeddings
Nova Multimodal Embeddings is the first unified embedding model that supports text, documents, images, video, and audio through a single model to enable cross-modal retrieval with industry-leading accuracy. It provides the following key capabilities and advantages:
- Unified vector space architecture: Unlike traditional tag-based systems or multimodal-to-text conversion pipelines that require complex mappings between different vector spaces, Nova Multimodal Embeddings generates embeddings that exist in the same semantic space regardless of input modality. This means a text description of
racing carwill be spatially close to images and videos containing racing cars, enabling intuitive cross-modal search. - Flexible embedding dimensions: Nova Multimodal Embeddings offers four embedding dimension options (256, 384, 1024, and 3072), trained using Matryoshka Representation Learning (MRL), enabling low-latency retrieval with minimal accuracy loss across different dimensions. The 1024-dimension option provides an optimal balance for most enterprise applications, while 3072 dimensions offer maximum precision for critical use cases.
- Synchronous and asynchronous APIs: The model supports both real-time embedding generation for smaller content and asynchronous processing for large files with automatic segmentation. This flexibility allows systems to handle everything from quick text query retrieval to indexing hours of video content.
- Advanced video understanding: For video content, Nova Multimodal Embeddings provides sophisticated segmentation capabilities, breaking long videos into meaningful segments (1–30 seconds) and generating embeddings for each segment. For advertising creative management, this segmented approach aligns perfectly with typical production workflows where creative teams need to manage and retrieve specific video segments rather than entire videos.
Integration with AWS services
Nova Multimodal Embeddings integrates seamlessly with other AWS services to create a production-ready multimodal search architecture:
- Amazon Bedrock: Provides foundation model access with enterprise-grade security and scalability
- Amazon OpenSearch Service: Serves as the vector database for storing and searching embeddings with millisecond-level query response times
- AWS Lambda: Handles serverless processing for embedding generation and search operations
- Amazon Simple Storage Service (Amazon S3): Stores original media files and processing results with unlimited scalability
- Amazon API Gateway: Provides RESTful APIs for frontend integration
Technical implementation
System architecture
The system operates through two primary workflows: content ingestion and search retrieval, shown in the following architecture diagram and described in the following sections.
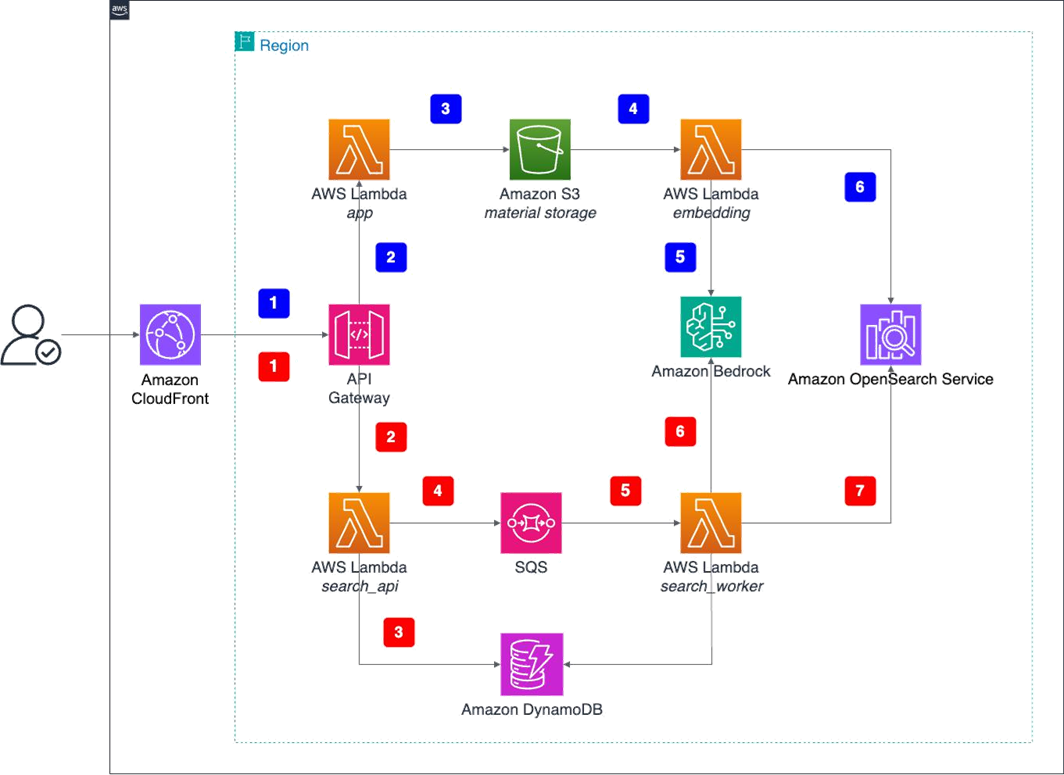
System execution flow
The content ingestion workflow transforms raw media files into searchable vector embeddings through a series of automated steps. This process begins when users upload content and culminates with the storage of embeddings in the vector database, making the content discoverable through semantic search.
- User interaction: Users access the web interface through Amazon CloudFront, uploading media files (images, videos, and audio) using drag-and-drop or file selection.
- API processing: Files are converted to base64 format and sent through API Gateway to the main Lambda function for file type and size limit validation (the maximum file size is 10 MB).
- Amazon S3 storage: Lambda decodes base64 data and uploads raw files to Amazon S3 for persistent storage.
- Amazon S3 event trigger: Amazon S3 automatically triggers a dedicated embedding Lambda function when new files are uploaded, initiating the embedding generation process.
- Amazon Bedrock invocation: The embedding Lambda function asynchronously invokes the Amazon Bedrock Nova Multimodal Embeddings model to generate unified embedding vectors for multiple media types.
- Vector storage: The embedding Lambda function stores generated embedding vectors along with metadata in OpenSearch Service, creating a searchable vector database.
Search and retrieval workflow
Through the search and retrieval workflow, users can find relevant content using multimodal queries. This process converts user queries into embeddings and performs similarity searches against the pre-built vector database, returning ranked results based on semantic similarity across different media types.
- Search request: Users initiate searches through the web interface using uploaded files or text queries, with options to select different search modes (visual, semantic, or audio).
- API processing: Search requests are sent through API Gateway to the search API Lambda function for initial processing.
- Task creation: The search API Lambda function creates search task records in Amazon DynamoDB and sends messages to an Amazon Simple Queue Service (Amazon SQS) queue for asynchronous processing.
- Queue processing: The search API Lambda function sends messages to an Amazon SQS queue for asynchronous processing. This unified asynchronous architecture handles the API requirements of Nova Multimodal Embeddings (async invocation for video segmentation), prevents API Gateway timeouts, and helps ensure scalable processing for multiple query types.
- Worker activation: The search worker Lambda function is triggered by Amazon SQS messages, extracting search parameters and preparing for embedding generation.
- Query embedding: The worker Lambda function invokes the Amazon Bedrock Nova Multimodal Embeddings model to generate embedding vectors for search queries (text or uploaded files).
- Vector search: The worker Lambda function performs similarity search using cosine similarity in OpenSearch Service, then updates the results in DynamoDB for frontend polling.
Workflow integration
The two workflows described in the previous section share common infrastructure components but serve different purposes:
- Upload workflow (1–6): Focuses on ingesting and processing media files to build a searchable vector database
- Search workflow (A–G): Processes user queries and retrieves relevant results from the pre-built vector database
- Shared components: Both workflows use the same Amazon Bedrock model, OpenSearch Service indexes, and core AWS services
Key technical features
- Unified vector space: All media types (images, videos, audio, and text) are embedded into the same dimensional space, enabling true cross-modal search.
- Asynchronous processing: The unified asynchronous architecture handles Amazon Nova Multimodal Embedding API requirements and helps ensure scalable processing through Amazon SQS queues and worker Lambda functions.
- Multi-modal search: Supports text-to-image, text-to-video, text-to-audio, and file-to-file similarity searches.
- Scalable architecture: The serverless design automatically scales based on demand.
- Status tracking: The polling mechanism provides updates on asynchronous processing status and search results.
Core embedding generation using Nova Multimodal Embeddings
Cross-modal search implementation
The heart of the system lies in its intelligent cross-modal search capabilities using OpenSearch k-nearest neighbor (KNN) search, as shown in the following code:
Vector storage and retrieval
The system uses OpenSearch Service as its vector database, optimizing indexing for different embedding types, as shown in the following code:
This schema supports multiple modalities (visual, text, and audio) with KNN indexing enabled, enabling flexible cross-modal search while preserving detailed metadata about video segments and model provenance.
Real-world application and performance
Using a gaming industry use case, let’s examine a scenario of a creative professional who needs to find video segments showing characters celebrating victory with bright visual effects for a new campaign.
Traditional approaches would require:
- Manual tagging of thousands of videos, which is labor-intensive and might be inconsistent
- Keyword-based search that misses semantic nuances
- LLM-based analysis that’s too slow and expensive for real-time queries
With Nova Multimodal Embeddings, the same query becomes a straightforward text search that:
- Generates a semantic embedding of the query
- Searches across all video segments in the unified vector space
- Returns ranked results based on semantic similarity
- Provides precise timestamps for relevant video segments
Performance metrics and validation
Based on comprehensive testing with gaming industry partners using a library of 170 assets (130 videos and 40 images), Nova Multimodal Embeddings demonstrated exceptional performance across 30 test cases:
- Recall success rate: 96.7% of test cases successfully retrieved the target content
- High-precision recall: 73.3% of test cases returned the target content in the top two results
- Cross-modal accuracy: Superior accuracy in text-to-video retrieval compared to traditional approaches
Key findings
Here’s what we learned from the results of our testing:
- Segmentation strategy: For advertising creative workflows, we recommend using
SEGMENTED_EMBEDDINGwith 5-second video segments because it aligns with typical production requirements. Creative teams commonly need to segment original advertising materials for management and retrieve specific clips during production workflows, making the segmentation functionality of Nova Multimodal Embeddings particularly valuable for these use cases. - Evaluation framework: To assess Nova Multimodal Embeddings effectiveness for your use case, focus on testing the following core capabilities:
- Object an entity detection: Test queries such as
red sports carorcharacter with swordto evaluate object recognition across modalities - Scene and context understanding: Assess contextual searches such as
outdoor celebration sceneorindoor meeting environment - Activities and actions: Validate action-based queries such as
running characterorclicking interface elements - Visual attributes: Test attribute-specific searches including colors, styles, and visual characteristics
- Abstract semantics: Evaluate conceptual understanding with queries such as
victory celebrationortense atmosphere - Testing methodology: Build a representative test dataset from your content library, create diverse query types matching real user needs, and measure both recall success (finding relevant content) and precision (ranking quality). Focus on queries that reflect your team’s actual search patterns rather than generic test cases.
- Multi-language performance: Nova Multimodal Embeddings demonstrates strong cross-language capabilities, particularly excelling in Chinese language queries with a score of 78.2 compared to English queries at 89.3 (3072-dimension). This represents a language gap of only 11.1, significantly better than another leading multimodal model that shows substantial performance degradation across different languages.
Scalability and cost benefits
The serverless architecture provides automatic scaling while optimizing costs. Keep the following dimension performance details and cost optimization strategies in mind when designing your multi-modal asset discovery system.
Dimension performance:
- 3072-dimension: Highest accuracy (89.3 for English and 78.2 for Chinese) and higher storage costs
- 1024-dimension: Balanced performance (85.7 for English and 68.3 for Chinese);recommended for most use cases
- 384/256-dimension: Cost-optimized options for large-scale deployments
Cost optimization strategies:
- Select the dimension based on accuracy requirements compared to storage costs
- Use asynchronous processing for large files to avoid timeout costs
- Use pre-computed embeddings reduce recurring LLM inference costs
- Use serverless architecture with pay-as-you-go on-demand pricing to reduce costs during low-usage periods
Getting started
This section provides the essential requirements and steps to deploy and run the Nova Multimodal Embeddings multimodal search system.
- An AWS account with Amazon Bedrock access and Nova Multimodal Embeddings model availability
- AWS Command Line Interface (AWS CLI) v2 configured with appropriate permissions for resource creation
- Node.js 18+ and AWS CDK v2 installed
- Python 3.11 for infrastructure deployment
- Git for cloning the demonstration repository
Quick deployment
The complete system can be deployed using the following automation scripts:
The deployment script automatically:
- Installs required dependencies
- Provisions AWS resources (Lambda, OpenSearch, Amazon S3, and API Gateway)
- Builds and deploys the frontend interface
- Configures API endpoints and CloudFront distribution
Accessing the system
After successful deployment, the system provides web interfaces for testing:
- Upload interface: For adding media files to the system
- Search interface: For performing multimodal queries
- Management interface: For monitoring processing status
Multi-modal input support (optional)
This optional subsection enables the system to accept image and video inputs in addition to text queries for comprehensive multimodal search capabilities.
Clean up
To avoid ongoing charges, use the following command to remove the AWS resources created during deployment:
Conclusion
Amazon Nova Multimodal Embeddings represents a fundamental shift in how organizations can manage and discover multimodal content at scale. By providing a unified vector space that seamlessly integrates text, images, and video content, Nova Multimodal Embeddings removes the traditional barriers that have limited cross-modal search capabilities. The complete source code and deployment scripts are available in the demonstration repository.
About the authors
 Jia Li is an Industry Solutions Architect at Amazon Web Services, focused on driving technical innovation and business growth in the gaming industry. With 20 years of full-stack game development experience, previously worked at companies such as Lianzhong, Renren, and Hungry Studio, serving as a game producer and director of a large-scale R&D center. Possesses deep insight into industry dynamics and business models.
Jia Li is an Industry Solutions Architect at Amazon Web Services, focused on driving technical innovation and business growth in the gaming industry. With 20 years of full-stack game development experience, previously worked at companies such as Lianzhong, Renren, and Hungry Studio, serving as a game producer and director of a large-scale R&D center. Possesses deep insight into industry dynamics and business models.
 Xiaowei Zhu is an Industry Solutions Builder at Amazon Web Services (AWS). With over 10 years of experience in mobile application development, he also has in-depth expertise in embedding search, automated testing and Vibe Coding. Currently, he is responsible for building AWS Game industry Assets and leading the development of the open-source application SwiftChat.
Xiaowei Zhu is an Industry Solutions Builder at Amazon Web Services (AWS). With over 10 years of experience in mobile application development, he also has in-depth expertise in embedding search, automated testing and Vibe Coding. Currently, he is responsible for building AWS Game industry Assets and leading the development of the open-source application SwiftChat.
 Hanyi Zhang is a Solutions Architect at AWS, focused on cloud architecture design for the gaming industry. With extensive experience in big data analytics, generative AI, and cloud observability, Hanyi has successfully delivered multiple large-scale projects with cutting edge AWS services.
Hanyi Zhang is a Solutions Architect at AWS, focused on cloud architecture design for the gaming industry. With extensive experience in big data analytics, generative AI, and cloud observability, Hanyi has successfully delivered multiple large-scale projects with cutting edge AWS services.
 Zepei Yu is a Solutions Architect at AWS, responsible for consulting and design of cloud computing solutions, and has extensive experience in AI/ML, DevOps, Gaming Industry, etc.
Zepei Yu is a Solutions Architect at AWS, responsible for consulting and design of cloud computing solutions, and has extensive experience in AI/ML, DevOps, Gaming Industry, etc.
 Bao Cao is a AWS Solutions Architect, responsible for architectural design based on AWS cloud computing solutions, helping customers build more innovative applications using leading cloud service technologies. Prior to joining AWS, worked at companies such as ByteDance, with over 10 years of extensive experience in game development and architectural design.
Bao Cao is a AWS Solutions Architect, responsible for architectural design based on AWS cloud computing solutions, helping customers build more innovative applications using leading cloud service technologies. Prior to joining AWS, worked at companies such as ByteDance, with over 10 years of extensive experience in game development and architectural design.
 Xi Wan is a Solutions Architect at Amazon Web Services, responsible for consulting on and designing cloud computing solutions based on AWS. A strong advocate of the AWS Builder culture. With over 12 years of game development experience, has participated in the management and development of multiple game projects and possesses deep understanding and insight into the gaming industry.
Xi Wan is a Solutions Architect at Amazon Web Services, responsible for consulting on and designing cloud computing solutions based on AWS. A strong advocate of the AWS Builder culture. With over 12 years of game development experience, has participated in the management and development of multiple game projects and possesses deep understanding and insight into the gaming industry.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




