






















Evaluating AI agents for production: A practical guide to Strands Evals
In this post, we show how to evaluate AI agents systematically using Strands Evals. We walk through the core concepts, built-in evaluators, multi-turn simulation capabilities and practical approaches and patterns for integration.

Moving AI agents from prototypes to production surfaces a challenge that traditional testing is unable to address. Agents are flexible, adaptive, and context-aware by design, but the same qualities that make them powerful also make them difficult to evaluate systematically.
Traditional software testing relies on deterministic outputs: same input, same expected output, every time. AI agents break this assumption. They generate natural language, make context-dependent decisions, and produce varied outputs even from identical inputs. How do you systematically evaluate something that is not deterministic?
In this post, we show how to evaluate AI agents systematically using Strands Evals. We walk through the core concepts, built-in evaluators, multi-turn simulation capabilities and practical approaches and patterns for integration. Strands Evals provides a structured framework for evaluating AI agents built with the Strands Agents SDK, offering evaluators, simulation tools, and reporting capabilities. Whether you need to verify that your agent uses the right tools, produces helpful responses, or guides users toward their goals, the framework provides infrastructure to measure and track these qualities systematically.
Why evaluating AI agents is different
When you ask an agent “What is the weather like in Tokyo?”, many valid responses exist, and no single answer is definitively correct. The agent might report temperature in Celsius or Fahrenheit, include humidity and wind, or only focus on temperature. These variations could be correct and helpful, which is exactly why traditional assertion-based testing falls short. Beyond text generation, agents also take action. A well-designed agent calls tools, retrieves information, and makes decisions throughout a conversation. Evaluating the final response alone misses whether the agent took appropriate steps to reach that response.
Even correct responses can fall short. A response might be factually accurate but unhelpful, or helpful but unfaithful to source materials. No single metric captures these different quality dimensions. Conversations add another layer of complexity because they unfold over time. In multi-turn interactions, earlier responses affect later ones. An agent might handle individual queries well but fail to maintain a coherent context across a conversation. Testing single turns in isolation misses these interaction patterns.
These characteristics demand evaluation that requires judgment rather than keyword comparison. Large language model (LLM)-based evaluation addresses this need. By using language models as evaluators, we can assess qualities like helpfulness, coherence, and faithfulness that resist mechanical checking. Strands Evals embraces this flexibility while still offering rigorous, repeatable quality assessments.
Core concepts of Strands Evals
Strands Evals follows a pattern that should feel familiar to anyone who has written unit tests but adapts it for the judgment-based evaluation that AI agents require. The framework introduces three foundational concepts that work together: Cases, Experiments, and Evaluators.
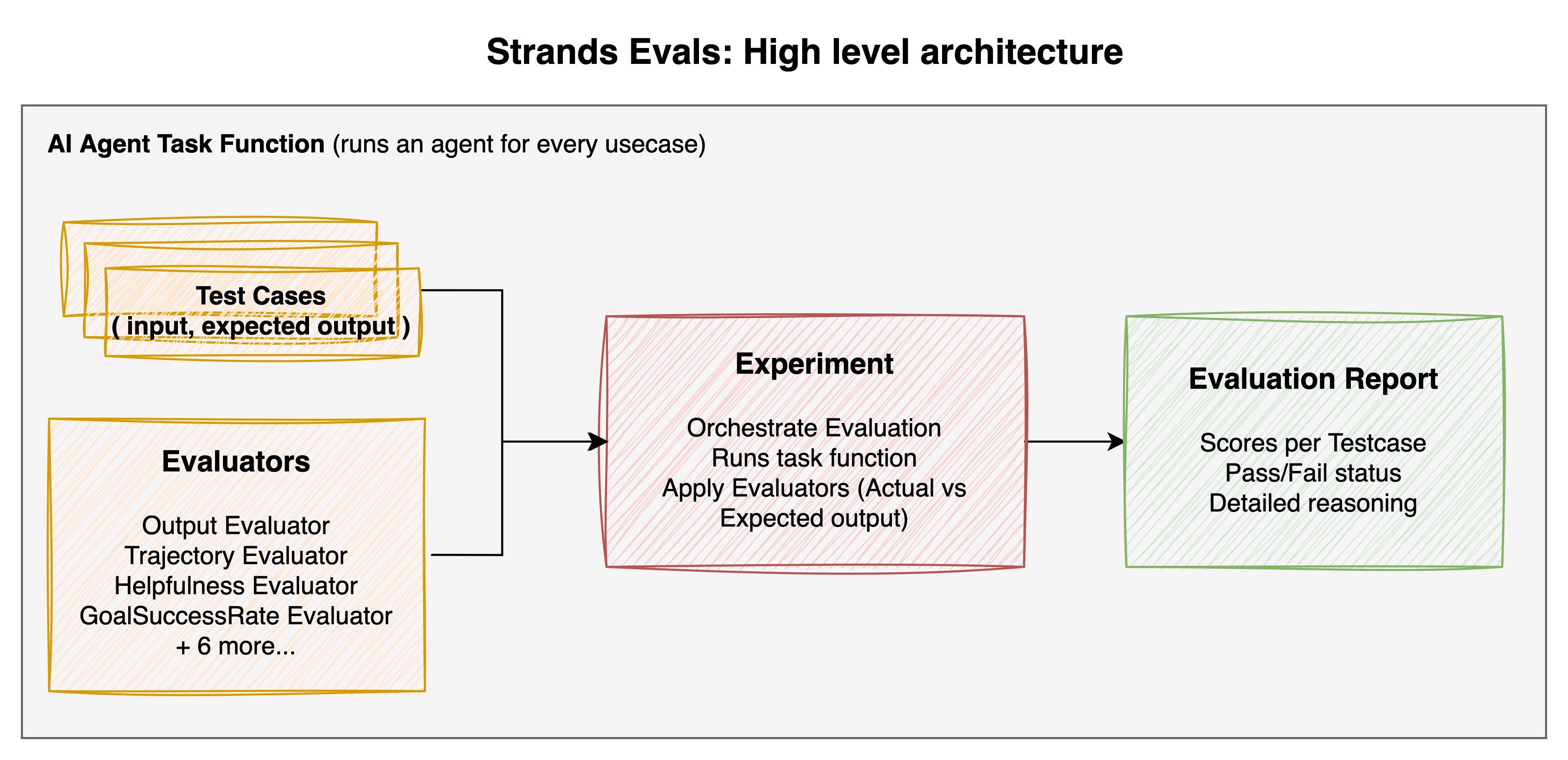
Figure: High-Level Architecture
A Case represents a single test scenario. It contains the input that you want to test, perhaps a user’s query like “What is the weather in Paris?”, along with optional expected outputs, expected tool sequences known as trajectories, and metadata. Cases are the atomic unit of evaluation. Each one defines one scenario that you want your agent to handle correctly.
from strands_evals import Case
case = Case(
name="Weather Query",
input="What is the weather like in Tokyo?",
expected_output="Should include temperature and conditions",
expected_trajectory=["weather_api"]
)
An Experiment bundles multiple Cases together with one or more evaluators. Think of it as a test suite in traditional testing. The Experiment orchestrates the evaluation process. It takes each Case, runs your agent on it, and applies the configured evaluators to score the results.
Evaluators are the judges. They examine what your agent produced (the actual output and trajectory) and compare it against what was expected. Unlike simple assertion checks, evaluators in Strands Evals are primarily LLM-based. They use language models to make nuanced judgments about quality, relevance, helpfulness, and other qualities that cannot be reduced to string comparison.
Separating these concerns helps keep the framework flexible. You can define what to test with Cases, how to test it with evaluators, and the framework handles orchestration and reporting through Experiments. Each piece can be configured independently so that you can build evaluation suites that are tailored to your specific needs.
The task function: connecting agents to evaluation
Cases define your scenarios, and evaluators provide judgment. But how does your agent actually connect to this evaluation system? That is where the Task Function comes in.
A Task Function is a callable that you provide to the Experiment. It receives a Case and returns the results of running that case through your system. This interface enables two fundamentally different evaluation patterns.
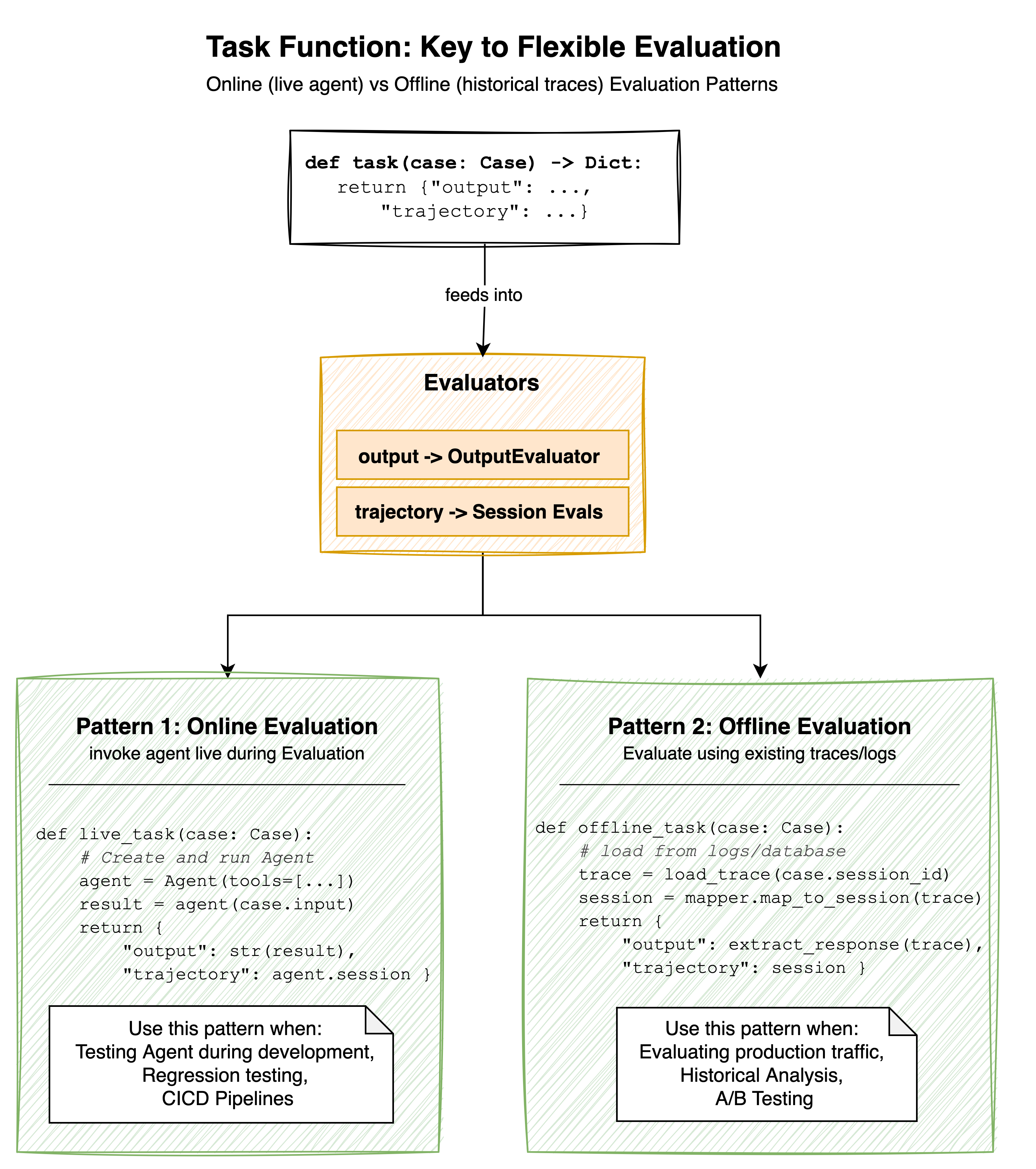
Figure: Task Function Patterns
Online evaluation involves invoking your agent live during the evaluation run. Your Task Function creates an agent, sends it the case input, captures the response and execution trace, and returns them for evaluation. This pattern is recommended during development when you want to test changes immediately, or in continuous integration and delivery (CI/CD) pipelines where you need to verify agent behavior before deployment.
from strands import Agent
def online_task(case):
agent = Agent(tools=[search_tool, calculator_tool])
result = agent(case.input)
return {
"output": str(result),
"trajectory": agent.session
}Offline evaluation works with historical data. Instead of invoking an agent, your Task Function retrieves previously recorded traces from logs, databases, or observability systems. It parses these traces into the format that evaluators expect and returns them for judgment. This pattern works well when you need to evaluate production traffic, perform historical analysis, or compare agent versions against the same set of real user interactions.
def offline_task(case):
trace = load_trace_from_database(case.session_id)
session = session_mapper.map_to_session(trace)
return {
"output": extract_final_response(trace),
"trajectory": session
}Whether you are testing a new agent implementation or analyzing months of production data, the same evaluators and reporting infrastructure apply. The Task Function adapts your data source to the evaluation system.
Built-in evaluators for comprehensive assessment
With your Task Function connecting agent output to the evaluation system, you can now decide which aspects of quality to measure. Strands Evals ships with ten built-in evaluators, each designed to assess a different dimension of agent quality.
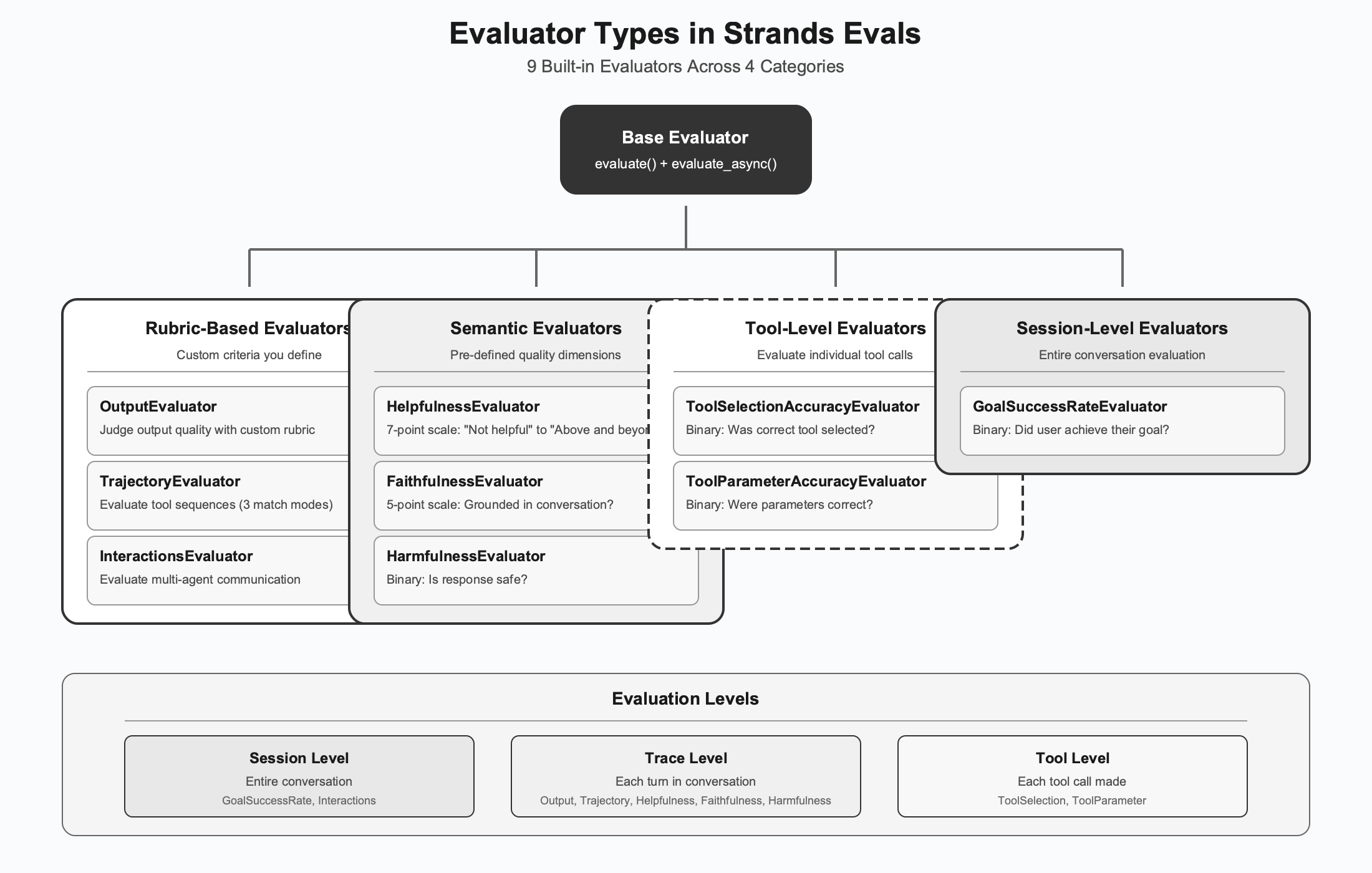
Figure: Evaluator Types
Rubric-based evaluators
The most flexible evaluators let you define custom criteria through natural language rubrics.
- OutputEvaluator judges the final response that your agent produces. You provide a rubric, a description of what good looks like, and the evaluators use an LLM to score the output against that criteria. This works well for general quality checks where you want to define specific standards for your use case.
from strands_evals.evaluators import OutputEvaluator
output_evaluator = OutputEvaluator(
rubric="Score 1.0 if the response correctly answers the question and is well-structured. "
"Score 0.5 if partially correct. Score 0.0 if incorrect or irrelevant."
)- TrajectoryEvaluator extends this to examine the sequence of actions (typically tool calls) that your agent took. Beyond just looking at the final answer, you can verify that the agent used appropriate tools in a logical order. The evaluators include three built-in scoring functions for comparing actual versus expected trajectories: exact match, in-order match, and any-order match. These scorers are provided as tools to the evaluation LLM, which chooses the most appropriate one based on your rubric.
- InteractionsEvaluator handles multi-agent systems where multiple components communicate. It evaluates sequences of interactions between agents or system components. This is useful when your architecture involves orchestrators, sub-agents, or complex tool chains.
Semantic evaluators
Some quality dimensions are common enough that Strands Evals provides pre-built evaluators with carefully designed prompts and scoring scales.
- HelpfulnessEvaluator assesses responses from the user’s perspective using a seven-point scale ranging from “Not helpful at all” to “Above and beyond.” It evaluates whether the response actually addresses the user’s needs, not only whether it is technically correct.
- FaithfulnessEvaluator checks whether the response is grounded in the conversation history. This is particularly important for Retrieval Augmented Generation (RAG) systems where you need to make sure that the agent doesn’t hallucinate information. The five-point scale ranges from “Not at all” faithful to “Completely yes.”
- HarmfulnessEvaluator performs safety checks, helping determine whether responses contain harmful, inappropriate, or dangerous content. It provides binary yes/no judgments for clear decision-making.
Tool-level evaluators
When your agent uses tools, you often need to evaluate not only the final outcome, but the quality of individual tool invocations.
- ToolSelectionAccuracyEvaluator examines each tool call in context and judges whether selecting that particular tool was justified given the conversation state. It answers: “At this point in the conversation, was it reasonable to call this tool?”
- ToolParameterAccuracyEvaluator goes deeper, checking whether the parameters passed to each tool were correct and appropriate. It helps catch subtle errors where the right tool was chosen but called with wrong or incomplete arguments.
Session-level evaluators
- GoalSuccessRateEvaluator takes the broadest view, evaluating entire conversation sessions to determine whether the user ultimately achieved their goal. For task-oriented agents, success is defined by outcomes rather than a single response.
Choosing the right evaluators
The choice depends on what matters most for your application. A customer service agent might prioritize helpfulness and goal success. A research assistant might emphasize faithfulness. Start with a small set of evaluators that cover your core quality dimensions, then add more as you learn how your agent fails.
Simulating users for multi-turn testing
The previously mentioned evaluators work well for single-turn interactions where you provide an input, get an output, and evaluate it. Multi-turn conversations present a harder challenge. Real users don’t follow scripts. They ask follow-up questions, change direction, and express confusion. How do you test this? Strands Evals includes an ActorSimulator that creates AI-powered simulated users to drive multi-turn conversations with your agent.
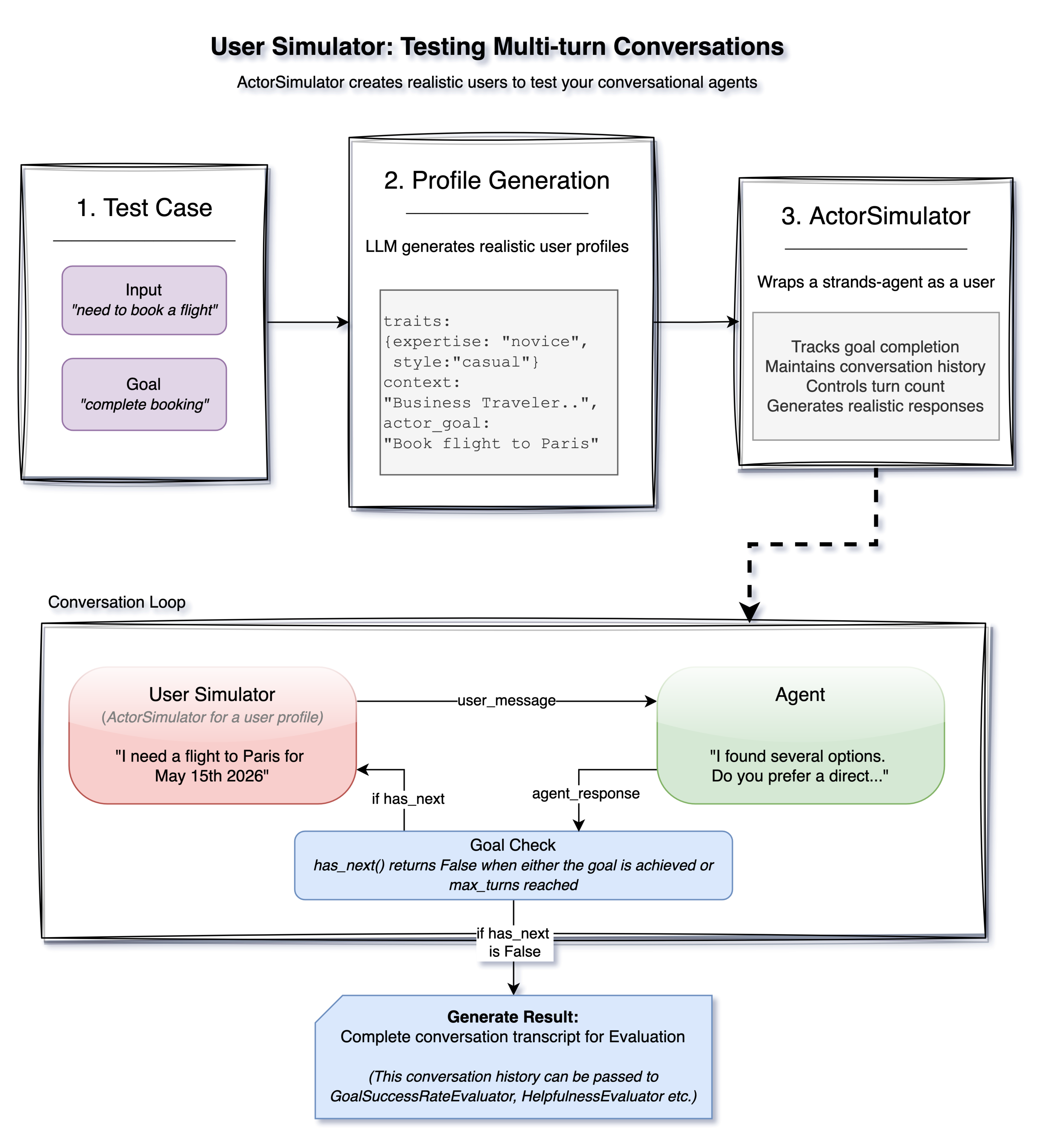
Figure: User Simulator Flow
ActorSimulator starts with a test case that defines what the user wants to achieve. From this, it generates a realistic user profile using an LLM, including personality traits, expertise level, communication style, and a specific goal. This profile shapes how the simulated user behaves throughout the conversation.
from strands_evals import Case, ActorSimulator
from strands import Agent
case = Case(
input="I need help setting up a new bank account",
metadata={"task_description": "Successfully open a checking account"}
)
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=10
)During the interaction, the simulated user sends messages to your agent, receives responses, and decides what to say next. This loop continues until either the goal is achieved, indicated by emitting a special stop token, or the maximum turn count is reached.
agent = Agent(system_prompt="You are a helpful banking assistant.")
user_message = case.input
while user_sim.has_next():
agent_response = agent(user_message)
user_result = user_sim.act(str(agent_response))
user_message = str(user_result.structured_output.message)You can then pass the resulting conversation transcript to session-level evaluators like GoalSuccessRateEvaluator to assess whether your agent successfully helped the simulated user achieve their goal. Instead of manually writing multi-turn scripts, you define goals and let the simulator create realistic interaction patterns. It might ask unexpected follow-up questions, express confusion, or take the conversation in directions that you didn’t anticipate, catching edge cases that scripted tests can miss.
Evaluation levels: understanding the hierarchy
Whether using simulated or real conversations, different evaluators operate at different granularities. Strands Evals uses a TraceExtractor to parse session data into the format that each evaluator needs.
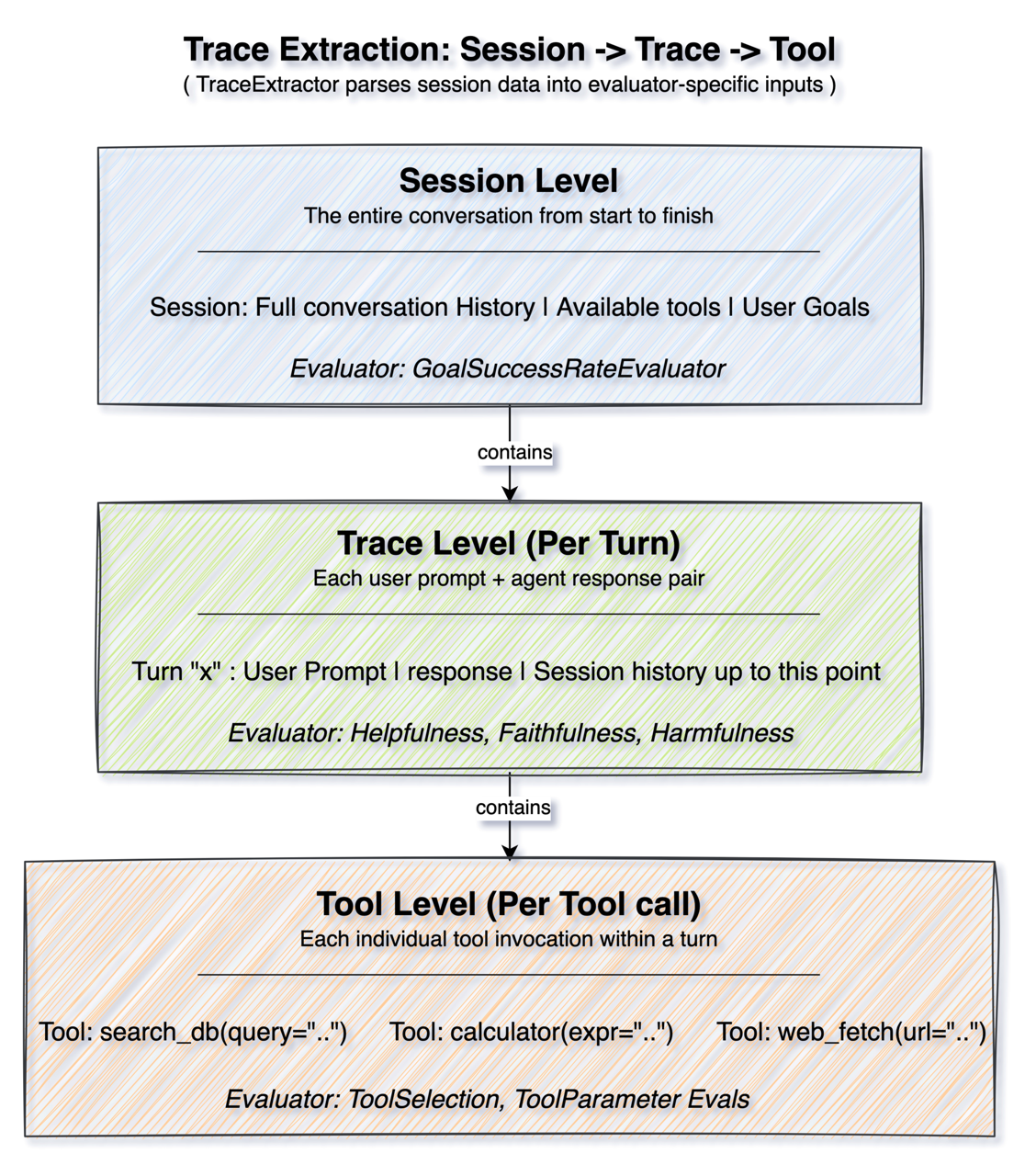
Session level evaluation looks at the complete conversation from beginning to end. The evaluator receives the full history, the tool executions, and understands the entire context. GoalSuccessRateEvaluator works at this level because determining goal achievement requires understanding the whole interaction.
Trace level evaluation focuses on individual turns, each user prompt, and agent response pair. Evaluators at this level receive the conversation history up to that point and judge the specific response. Helpfulness, Faithfulness, and Harmfulness evaluators work here because these qualities can be assessed turn by turn.
Tool level evaluation drills down to individual tool invocations. Each tool call is evaluated in context, with access to the available tools, the conversation so far, and the specific arguments passed. Tool Selection and Tool Parameter evaluators operate at this granularity.
You can use the hierarchical design to compose evaluation suites that check quality at multiple levels simultaneously. Within a single evaluation run, you can verify that individual tool calls are sensible, responses are helpful, and overall goals are achieved.
Ground truth and expected behaviors
At many different evaluation levels, evaluators can benefit from having reference points for comparison. Strands Evals provides first-class support for ground truth through three expected fields on Cases.
The expected_output field specifies what the agent should say. This is useful when there are correct answers or standard response formats. The expected_trajectory field defines the sequence of tools or actions that the agent should take. You might require that a customer service agent checks account status before making changes, or that a research agent queries multiple sources before synthesizing. Not every Case needs every field. You define expectations based on what matters for your evaluation goals. When expected values are provided, evaluators receive both expected and actual results, enabling comparison-based scoring alongside standalone quality assessment.
Putting it all together
Let’s walk through a typical evaluation workflow to see how these concepts come together.
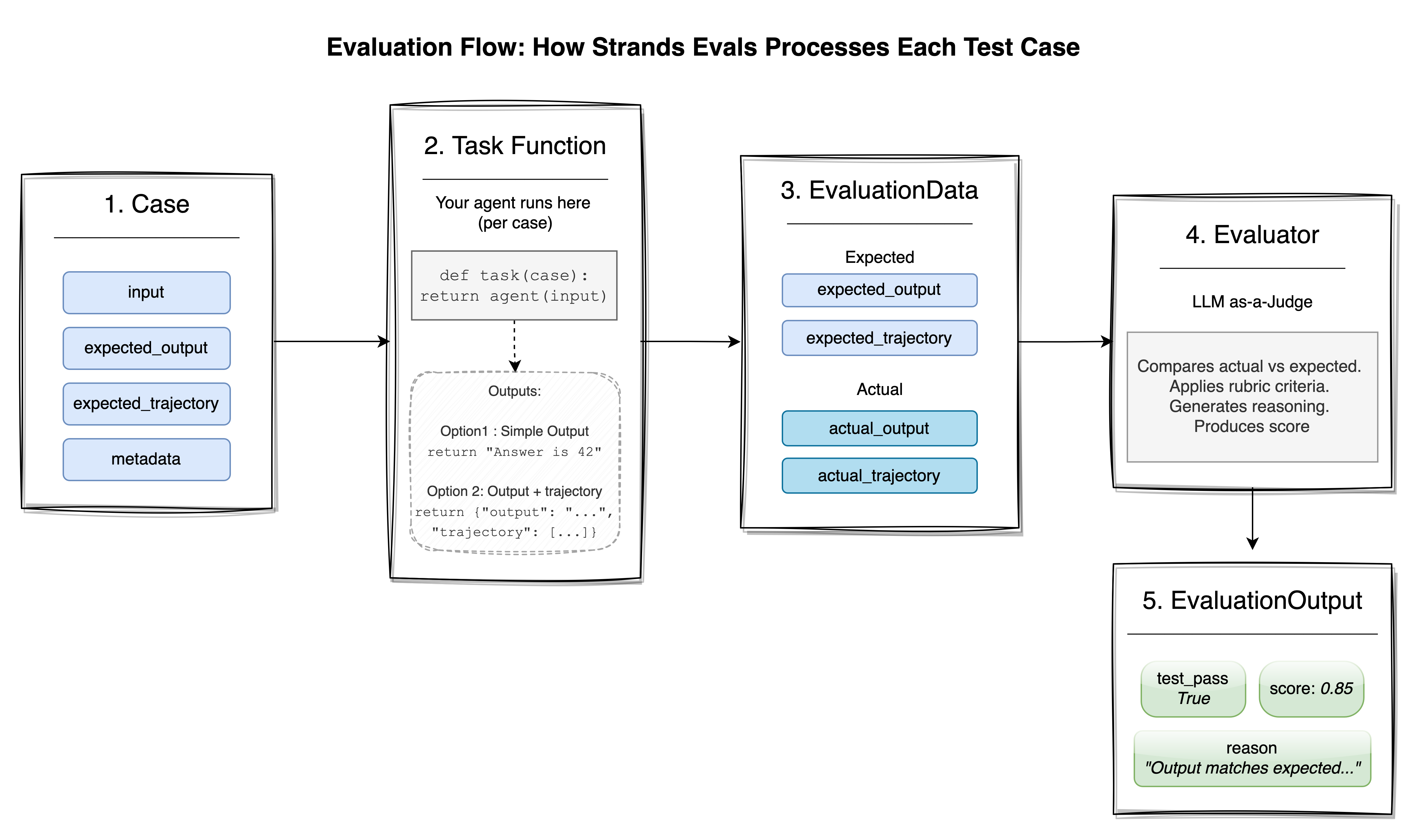
Figure: Evaluation Flow
First, you define your test cases, meaning the scenarios you want your agent to handle well. They might come from real user queries, synthetic generation, or edge cases that you have identified.
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator, TrajectoryEvaluator
from strands_evals.extractors import tools_use_extractor
cases = [
Case(
name="Weather Query",
input="What is the weather like in Tokyo?",
expected_output="Should include temperature and conditions",
expected_trajectory=["weather_api"]
),
Case(
name="Calculator Usage",
input="What is 15% of 847?",
expected_output="127.05",
expected_trajectory=["calculator"]
)
]
Next, you configure evaluators with appropriate rubrics or settings.
output_evaluator = OutputEvaluator(
rubric="Score 1.0 if the response is accurate and directly answers the question. "
"Score 0.5 if partially correct. Score 0.0 if incorrect or irrelevant."
)
trajectory_evaluator = TrajectoryEvaluator(
rubric="Verify the agent used appropriate tools for the task."
)Then, you create an experiment bundling cases and evaluators.
experiment = Experiment(
cases=cases,
evaluators=[output_evaluator, trajectory_evaluator]
)Finally, you run the evaluation with your Task Function and examine the results.
def my_task(case):
agent = Agent(tools=[weather_tool, calculator_tool])
result = agent(case.input)
return {
"output": str(result),
"trajectory": tools_use_extractor.extract_agent_tools_used(agent.messages)
}
reports = experiment.run_evaluations(my_task)
for report in reports:
report.display()The EvaluationReport provides overall scores, per-case breakdowns, pass/fail status, and detailed reasoning from each evaluator. You can display results interactively in the console, export to JSON for further analysis, or integrate into CI/CD pipelines. For larger test suites, Strands Evals supports asynchronous evaluation with configurable parallelism:
reports = await experiment.run_evaluations_async(my_task, max_workers=10)Generating test cases at scale
The previous workflow assumes that you have test cases ready. Creating comprehensive test suites by hand is tedious as your agent’s capabilities grow. Strands Evals includes an ExperimentGenerator that uses LLMs to create test cases and evaluation rubrics from high-level descriptions.
from strands_evals.generators import ExperimentGenerator
from strands_evals.evaluators import OutputEvaluator
generator = ExperimentGenerator(
input_type=str,
output_type=str,
include_expected_output=True
)
experiment = await generator.from_context_async(
context="A customer service agent for an e-commerce platform",
task_description="Handle customer inquiries about orders, returns, and products",
num_cases=20,
evaluator=OutputEvaluator
)
The generator creates diverse test cases covering different aspects of the specified context, with appropriate difficulty levels. It can also generate evaluation rubrics that are tailored to the task. Generated cases are particularly valuable during early development when you want broad coverage but have not yet identified specific failure patterns. As your evaluation practice matures, supplement generated Cases with hand-crafted scenarios targeting known edge cases.
Integrating evaluation into your workflow
Evaluation helps deliver the most value as part of your regular development workflow. During development, run evaluations frequently as you make changes. Fast feedback helps you catch regressions early and understand how changes affect different quality dimensions.
In CI/CD pipelines, include evaluation as a quality gate before deployment. Set score thresholds that must be met for a build to pass. This helps prevent quality regressions from reaching production. For production monitoring, use offline evaluation to assess real user interactions periodically. This reveals patterns that development testing might miss: unusual queries, edge cases you did not anticipate, or gradual drift in agent behavior. Track evaluation results over time. Trending metrics help you understand whether quality is improving or degrading.
Best practices for agent evaluation
- Start small and iterate : Begin with a handful of test cases covering your most critical user scenarios. As you observe how your agent fails in practice, add targeted cases that address those specific failure modes. A focused test suite that catches real problems is more valuable than a large suite with poor coverage.
- Match Evaluators to your quality goals : Choose evaluators that directly measure what matters for your use case. A customer-facing agent might prioritize
HelpfulnessEvaluatorandGoalSuccessRateEvaluator, while a research assistant might weighFaithfulnessEvaluatormore heavily. Avoid the temptation to add every available evaluator, as this increases cost and can dilute focus. - Write clear, specific rubrics : Rubric-based evaluators are only as good as the rubrics you provide. Avoid vague criteria like “good response” in favor of specific, measurable standards. Include examples of what constitutes high, medium, and low scores. Test your rubrics on sample outputs before running full evaluations.
- Combine online and offline evaluation : Use online evaluation during development for fast feedback on code changes. Complement this with offline evaluation of production traces to catch issues that only appear with real user behavior. The two approaches reveal different types of problems.
- Set meaningful thresholds : Define pass/fail thresholds based on your actual quality requirements, not arbitrary numbers. A 0.8 threshold means nothing if your users need 0.95 accuracy. Analyze evaluation results to understand what scores correlate with good user outcomes, then set thresholds accordingly.
- Track trends over time : Individual evaluation runs provide snapshots, but trends reveal the trajectory. Store evaluation results and track key metrics across releases. Gradual degradation can be harder to notice than sudden failures, but equally damaging.
- Invest in test case diversity : Cover the full range of inputs that your agent will encounter: common queries, edge cases, adversarial inputs, and multi-turn conversations. Use the
ExperimentGeneratorfor broad coverage, then supplement with hand-crafted Cases targeting known weaknesses. - Evaluate at multiple levels : Session-level success can mask tool-level problems, and the reverse. An agent might achieve user goals through inefficient or incorrect intermediate steps. Compose evaluation suites that check quality at session, trace, and tool levels to get a complete picture.
Conclusion
Building reliable AI agents requires more than intuition and spot checks. It requires systematic evaluation that tracks quality across multiple dimensions over time. Strands Evals helps provide this foundation through a framework designed specifically for the unique challenges of agent evaluation.
Task Functions separate agent invocation from evaluation logic, enabling both online testing during development and offline analysis of production traces. LLM-based evaluators provide the judgment that quality assessment requires. Hierarchical evaluation levels allow assessment at multiple granularities, from individual tool calls to complete conversation sessions. And the user simulator transforms multi-turn testing from a scripting exercise into realistic user behavior simulation.
These capabilities help you build confidence in your AI agents through evidence rather than assumptions. You can measure whether changes improve or degrade quality, catch regressions before they reach production, and demonstrate to stakeholders that your agents meet defined quality standards.
We encourage you to explore Strands Evals for your agent evaluation needs. The samples repository contains practical examples that you can adapt to your own use cases. Start with a few test cases representing your most important user scenarios, add evaluators that match your quality criteria, and run evaluations as part of your development workflow. Over time, expand your test suite to cover more scenarios. Systematic evaluation is the foundation that helps you ship AI agents with confidence.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




