























Reinforcement fine-tuning on Amazon Bedrock: Best practices
In this post, we explore where RFT is most effective, using the GSM8K mathematical reasoning dataset as a concrete example. We then walk through best practices for dataset preparation and reward function design, show how to monitor training progress using Amazon Bedrock metrics, and conclude with practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases.

You can use reinforcement Fine-Tuning (RFT) in Amazon Bedrock to customize Amazon Nova and supported open source models by defining what “good” looks like—no large labeled datasets required. By learning from reward signals rather than static examples, RFT delivers up to 66% accuracy gains over base models at reduced customization cost and complexity. This post covers best practices for RFT on Amazon Bedrock, from dataset design, reward function strategy, and hyperparameter tuning for use cases like code generation, structured extraction, and content moderation.
In this post, we explore where RFT is most effective, using the GSM8K mathematical reasoning dataset as a concrete example. We then walk through best practices for dataset preparation and reward function design, show how to monitor training progress using Amazon Bedrock metrics, and conclude with practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases.
RFT use-cases: Where can RFT shine?
Reinforcement Fine-Tuning (RFT) is a model customization technique that improves foundation model (FM) behavior using reward signals. Compared to supervised fine-tuning (SFT), it doesn’t directly train on correct responses (labeled I/O pairs). Instead, RFT uses a dataset of inputs and a reward function. The reward function can be rule-based or another trained grader model, or large language model (LLM) as a judge. During training, the model generates candidate responses and the reward function scores each response. Based on the reward, the model weights are updated to increase the probability of generating responses that receive a high reward. This iterative cycle of sample responses, score responses, and update weights steers the model to learn which behaviors lead to better outcomes. RFT is particularly valuable when the desired behavior can be evaluated, but difficult to demonstrate—whether because labeled data is impractical to curate or because static examples alone can’t capture the reasoning a task demands. It excels in two primary areas:
- Tasks where a rule or test can verify correctness automatically
- Subjective tasks where another model can effectively evaluate response quality
Tasks in the first category are code generation that must pass tests, math reasoning with verifiable answers, structured data extraction that must match strict schemas, or API/tool calls that must parse and execute correctly. Because success criteria can be translated directly into reward signals, the model can discover stronger strategies than what a small set of labeled examples could teach. This pattern is known as Reinforcement Learning with Verifiable Rewards (RLVR).
In addition, RFT suits subjective tasks such as content moderation, chatbots, creative writing, or summarization that lack easily quantifiable correctness. A judge model, guided by a detailed evaluation rubric, can serve as the reward function. It scores outputs against criteria that would be impractical to encode as static training pairs. This approach is known as Reinforcement Learning with AI Feedback (RLAIF).
For RFT in Amazon Bedrock, you can implement both rule-based and model-based approaches as a custom AWS Lambda function, which is the reward function that Amazon Bedrock calls during the training loop.
A comparison of these two approaches is depicted in the following diagram:
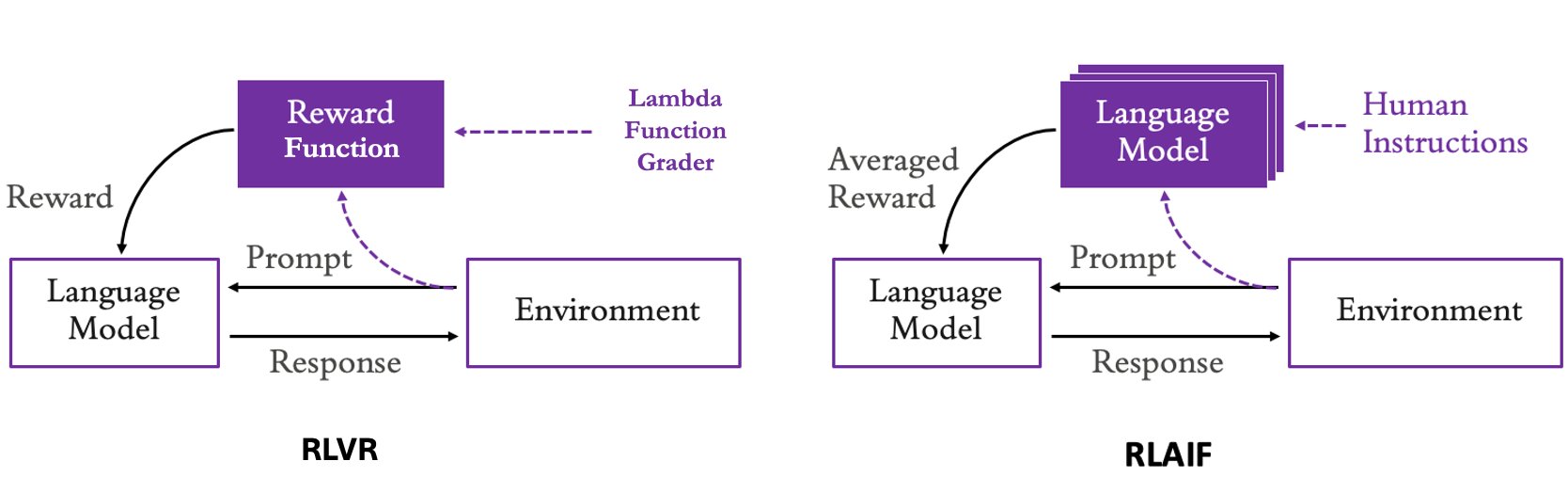
The following are a few common use cases that can be tackled through RLVR, RLAIF, or a combination of both.
| Use Case | Reward Signal |
| Code generation for production services | Unit-test pass rates, linting, and runtime checks |
| Tool and API orchestration | Successful end-to-end task completion (like, booking flows, data retrieval pipelines) |
| Complex math and algorithmic reasoning | Correct final answers and/or intermediate verification steps |
| Structured data extraction and transformation | Schema validation, exact matches, penalties for malformed outputs |
| SQL / query synthesis over databases | Query results matching expected answers or satisfying runtime properties |
| Agentic workflows | Combination of RLVR and RLAIF; RLVR for tool calling correctness; RLAIF for final task completion, for example, measured as usefulness, correctness, or robustness |
GSM8K: Using RFT to improve solutions to mathematical calculations
To illustrate how reinforcement fine-tuning works in practice, we can examine a concrete example: improving a model’s ability to solve mathematical reasoning problems. RFT is useful for mathematical problems because solutions can often be objectively verified, making it possible to design clear reward signals that guide the model toward correct reasoning and structured outputs. Let’s look at an example from the GSM8K (Grade School Math 8K) dataset:
Tina makes $18.00 an hour. If she works more than 8 hours per shift, she is eligible for overtime, which is paid by your hourly wage + 1/2 your hourly wage. If she works 10 hours every day for 5 days, how much money does she make?
Let’s look at what an ideal response might look like:
Here, we see that the problem is broken down into logical steps and shows clear reasoning paths, not only final answers. Additionally, we would like the model to respond in this specific format and have the answer exactly match the ground truth solution. Other fine-tuning methods like SFT struggle with mathematical reasoning because they primarily learn to pattern-match training data rather than truly reason. These models can memorize solution templates but often fail when presented with novel variations of a problem.
Because we can use RFT to define reward functions, exact answers like the previous answer of $990 can be objectively evaluated while also assigning partial credit for correct intermediate reasoning steps. This enables the model to discover valid solution approaches while learning to follow required structured, and in many cases achieves strong performance with relatively small datasets (around 100–1000 examples).
Best practices for preparing Your dataset
RFT requires carefully prepared datasets to achieve effective results. On Amazon Bedrock, RFT training data is provided as a JSONL file, with each record following the OpenAI chat completion format.
Dataset size guidelines
RFT supports dataset sizes between 100–10,000 training samples, though requirements vary depending on task complexity and reward function design. Tasks involving complex reasoning, specialized domains, or broad application scopes generally benefit from larger datasets and a sophisticated reward function. For initial experimentation, start with a small dataset (100–200 examples) to validate that your prompts and reward function produce meaningful learning signals and that the base model can achieve measurable reward improvements. Note that for certain domains, only customizing on small datasets can yield limited generalization and show inconsistent results across prompt variations. Typical implementations using 200–5,000 examples provide stronger generalization and more consistent performance across prompt variations. For more complex reasoning tasks, specialized domains, or sophisticated reward functions, 5,000–10,000 examples can improve robustness across diverse inputs.
For more information about the dataset requirements, see the Amazon Bedrock documentation.
Dataset quality principles
The quality of your training data fundamentally determines RFT outcomes. Consider the following principles when preparing your dataset:
1. Prompt distribution
Make sure that the dataset reflects the full range of prompts that the model will encounter in production. A skewed dataset can lead to poor generalization or unstable training behavior.
2. Base model capability
RFT assumes that the base model demonstrates basic task understanding. If the model can’t achieve a non-zero reward on your prompts, the learning signal will be too weak for effective training. A simple validation step is generating several responses from the base model (like, temperature ≈ 0.6) and confirming that the outputs produce meaningful reward signals.
3. Clear prompt design
Prompts should clearly communicate expectations and constraints. Ambiguous instructions lead to inconsistent reward signals and degraded learning. Prompt structure should also align with reward function parsing. For example, requiring final answers after a specific marker or enforcing code blocks for programming tasks, as well as the prompt structure that the base model is familiar with from pre-training.
4. Reliable reference answers
When possible, include a reference answer that represents the desired output pattern, formatting, and correctness criteria. Reference answers anchor reward computation and reduce noise in the learning signal. For example, mathematical tasks might include a correct numerical answer, while coding tasks might include unit tests or input-output pairs.
It’s also good practice to validate reference answers by confirming that a response aligned with the ground truth receives the maximum reward score.
5. Consistent reward signals within the data
Because RFT relies entirely on reward signals to guide learning, the quality of those signals is critical. Your dataset and reward function should work together to produce consistent, well-differentiated scores. This means that strong responses reliably score higher than weak ones across similar inputs. If the reward function can’t clearly distinguish between good and poor responses, or if similar outputs receive widely varying scores, the model might learn the wrong patterns or fail to improve altogether.
In the next section you will learn what to keep in mind when writing your reward function.
Preparing your reward function
Reward functions are central to RFT because they evaluate and score model responses, assigning higher rewards to preferred outputs and lower rewards to less desirable ones. This feedback guides the model toward improved behavior during training. For objective tasks like mathematical reasoning, a candidate response that produces the correct answer might receive a reward of 1, while an incorrect answer receives 0. A response with a partially correct reasoning trace and an incorrect final answer might get a reward of 0.8 (depending on how much you want to penalize an incorrect final response). For subjective tasks, the reward function encodes desired qualities. For example, in summarization it might capture faithfulness, coverage, and clarity. For more information about setting up your reward function, see setting up reward functions for Amazon Nova models.
Reward design for verifiable tasks
For tasks that can be deterministically verified, like math reasoning or coding, the simplest approach is to programmatically check correctness. Effective reward functions typically evaluate both format constraints and performance objectives. Format checks make sure that the responses can be reliably parsed and evaluated. Performance metrics determine whether the result is correct. Rewards can be implemented using binary signals (correct compared to incorrect) or continuous scoring depending on the task.
For GSM8K-style mathematical reasoning tasks, reward functions must also account for how models express numerical answers. Models can format numbers with commas, currency symbols, percentages, or embed answers within explanatory text. To address this, answers should be normalized by stripping formatting characters and applying flexible extraction that prioritizes structured formats before falling back to pattern matching. This approach makes sure that the models are rewarded for correct reasoning rather than penalized for stylistic formatting choices. You can find the full reward function implementation for GSM8K in the amazon-bedrock-samples GitHub repository.
Reward design for non-verifiable tasks
Tasks like summarization, creative writing, or semantic alignment require an LLM-based judge to approximate subjective preferences. In this setting, the judge prompt effectively acts as the reward function, defining what behaviors are rewarded and how responses are scored. A practical judge prompt should clearly define the evaluation goal and include a concise scoring rubric with numeric scales reflecting the qualities the model should improve for.
Judge prompts should also return structured outputs, for example JSON or tagged formats containing the final score and optional reasoning, so reward values can be reliably extracted during training while maintaining observability into how each response was evaluated. An example of a reward function that utilizes AI feedback can be seen in this PandaLM reward function script in GitHub.
Combining verifiable rewards with AI feedback
Reward functions for verifiable tasks can also be augmented with AI feedback to evaluate solution quality beyond numerical correctness. For example, an LLM-as-a-judge can assess the reasoning chain, verify intermediate calculations, or evaluate the clarity of explanations, providing a reward signal that captures both correctness and reasoning quality.
Iterating on reward design
Reward functions often require iteration. Early versions might produce noisy signals or during the training loop the model might learn to exploit the reward function to generate a high reward without learning the desired behavior. Refining the reward logic based on observed training behavior is essential. Before launching full training jobs, it’s also good practice to test reward functions independently using sample prompts and known outputs to ensure that the scoring logic produces stable and meaningful reward signals.
Evaluating training progress: signals that the model is learning
After your dataset and reward function are ready, you can launch RFT training using either the Amazon Bedrock API or through the console. The exact workflow depends on your preferred development environment. The Create and manage fine-tuning jobs for Amazon Nova models topic in the Amazon Bedrock User Guide provides step-by-step instructions for both approaches. After training begins, monitoring the training metrics is critical. These signals indicate whether the reward function is meaningful and whether the model is learning useful behaviors rather than overfitting or collapsing to trivial strategies. The following image shows the training metrics of one of our GSM8K training run showing healthy training dynamics.
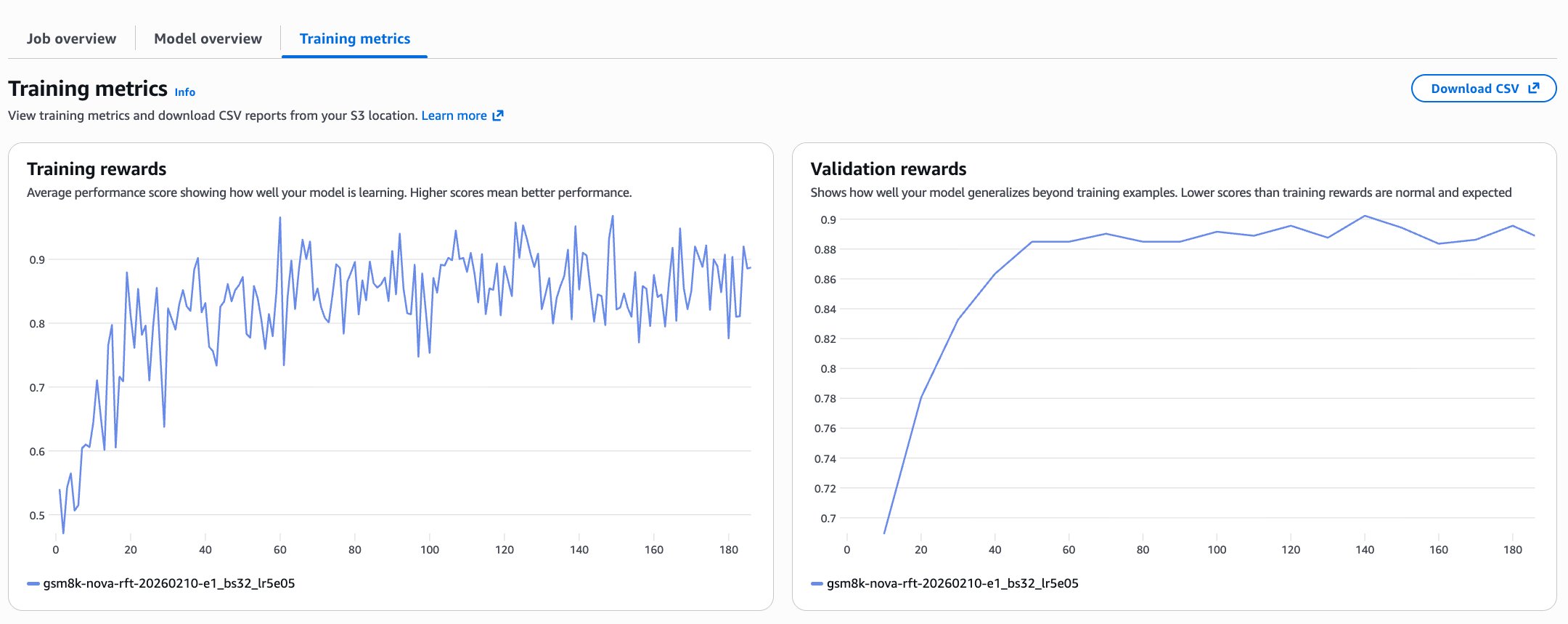
Training rewards plots the average reward score at each training step. Variance is expected because the input prompts in a batch are sampled randomly so difficulty in batches differ. In addition, the model is exploring different strategies leading to variance. What matters is the overall trend: rewards increase from roughly 0.5 to around 0.8–0.9, indicating that the model is converging on receiving higher rewards. Validation rewards provide a clearer signal because they are computed on a held-out dataset. Here we see a steep improvement during the first ~40 steps followed by a plateau around 0.88, suggesting the model is generalizing rather than memorizing training examples. Validation rewards that track closely with training rewards are typically a sign that overfitting isn’t occurring.
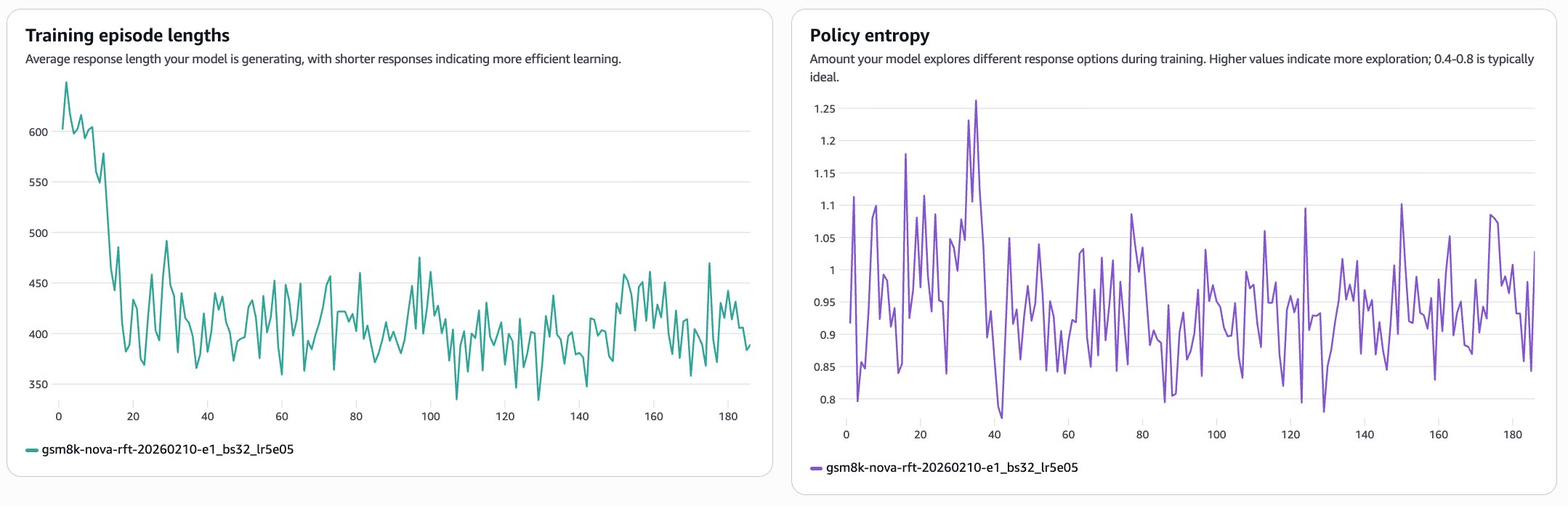
Training episode length measures the average response length. The drop from roughly 625 tokens to ~400 tokens suggests that the model is learning to reach correct answers more efficiently, producing less redundant reasoning as training progresses. Policy entropy measures how much the model is exploring different response strategies during training. Values in the 0.8–1.1 range indicate healthy exploration. If entropy collapsed toward zero it would suggest the model had prematurely converged, but sustained entropy implies the model is still exploring and improving.
Hyperparameter tuning guidelines
In this section, we cover practical hyperparameter tuning guidelines for Amazon Bedrock RFT. These recommendations are informed by a series of internal experiments that we ran across multiple models and use cases. This includes reasoning tasks like GSM8K and other structured and generative workloads. While effective values will vary by task, the patterns observed across these experiments provide useful starting points when configuring RFT jobs. For more information about the hyperparameters that you can configure before launching an RFT customization job, see the official boto3 docs.
EpochCount
Training duration and epochCount require adjustment based on dataset size and model behavior. Smaller datasets often show continued improvement through 6-12 epochs, while larger datasets may achieve optimal performance in 3-6 epochs. This relationship isn’t linear and careful monitoring of validation metrics remains essential to prevent overfitting while ensuring sufficient model adaptation.
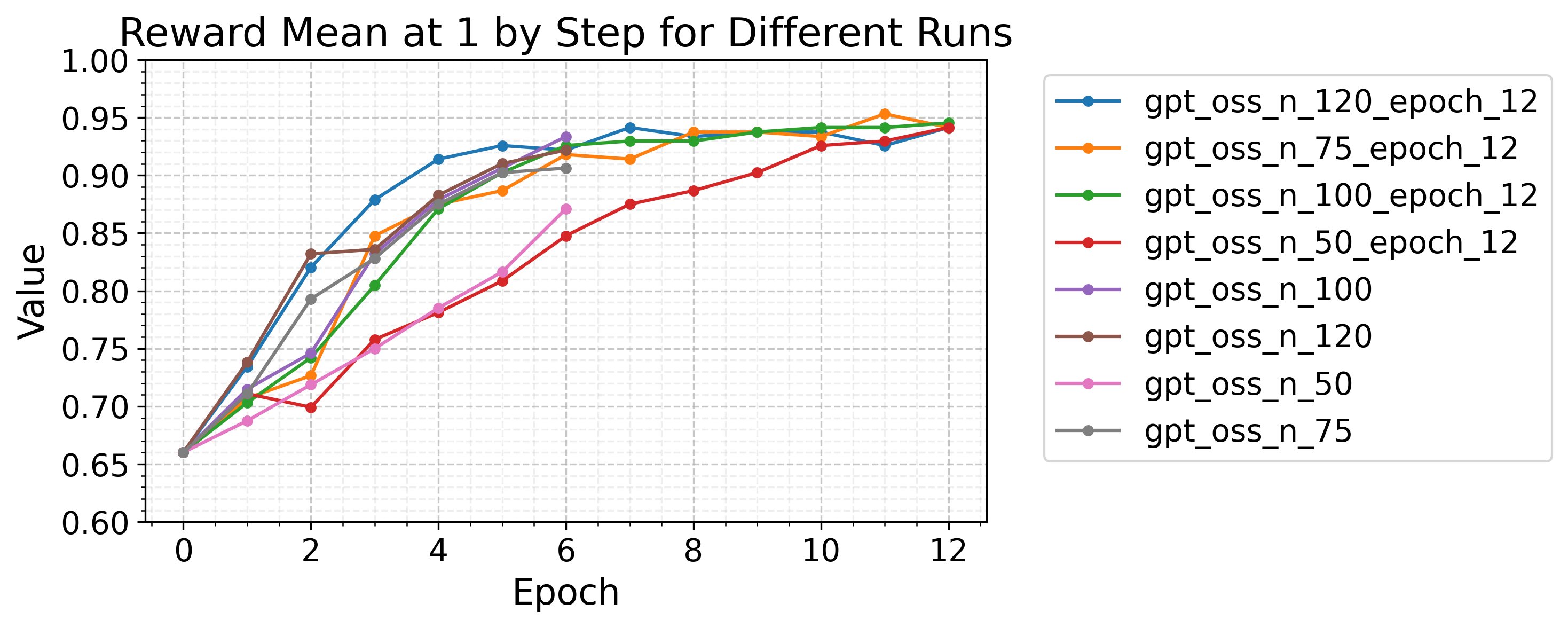
BatchSize
This parameter controls how many prompts are processed before the updated model generates a new round of candidate responses (rollouts). For example, with a batchSize of 128, the model processes, updates, and generates new rollouts for 128 prompts at a time until it has worked through the full dataset. The total number of rollout rounds equals the (filtered) dataset size divided by batchSize.
A batchSize of 128 works well for most use cases and models. Increase it if loss is erratic or reward isn’t improving. Decrease it if iterations take too long.
LearningRate
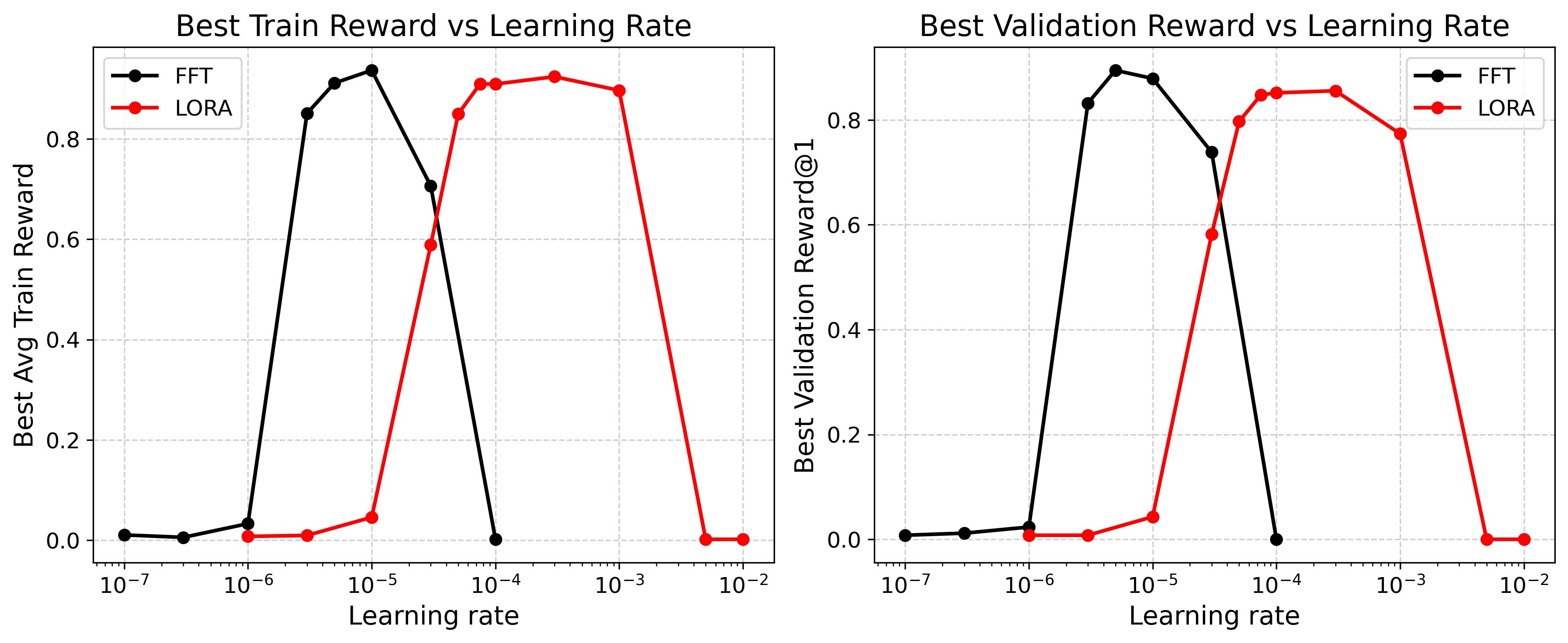
In Amazon Bedrock RFT, we perform parameter-efficient RFT using Low Rank Adaptation (LoRA) adapters with a rank of 32. Across a range of use cases, a learning rate of 1e-4 has consistently produced strong results. In the following experiment, we swept learning rates across seven orders of magnitude on Qwen3-1.7B using the GSM8K dataset (1K training samples, 256 test samples), running a single epoch with batch size 64, group size 16, and LoRA rank 1.As shown in the following figure, LoRA’s optimal learning rate peaks around 1e-4 to 1e-3, approximately one order of magnitude higher than full fine-tuning (FFT). Even with a rank of 1, LoRA achieves within ~5.5% of FFT’s best validation reward at roughly the same wall-clock time. In practice, LoRA-based RFT tends to be more forgiving and performs well across a wider range of learning rates than FFT, though both approaches can collapse outside their optimal ranges. We recommend monitoring reward curves closely and lowering the learning rate if they begin to oscillate or collapse.
Prompt length and response length
The maxPromptLength defines the maximum allowed length for input prompt in the dataset. Prompts exceeding this limit are filtered out during training. If your dataset contains unusually long prompts or other outliers, set an appropriate value that excludes outliers while retaining most samples. Otherwise, you can set it to the length of the longest prompt in your dataset. On the other hand, inferenceMaxTokens defines the maximum response length for any rollout or response generated during RL training. You can use this argument to control whether the resulting model generates detailed outputs or concise answers. We recommend that you choose a value based on the requirements of your task. An excessively large value can increase training time while a too small value could degrade model performance. For the tasks that don’t require complex reasoning, setting the maximum response length to 1,024 is typically sufficient. In contrast, for challenging tasks like coding or long-form generation, using a larger upper bound (more than 4,096) is preferable.
Early stopping and evaluation interval
Our RFT service provides two features that optimize training efficiency and model quality. EarlyStopping (enabled by default) automatically stops training when performance improvements plateau, preventing overfitting and reducing unnecessary computation costs. The system continuously monitors validation metrics and terminates training after it detects that further iterations are unlikely to yield meaningful improvements. Meanwhile, evalInterval determines how frequently the model evaluates its performance on the validation dataset during training. This hyperparameter is automatically calculated as min(10, data_size/batch_size), maintaining at least one evaluation per epoch while maintaining reasonable frequency. For datasets where data_size significantly exceeds 10×batch_size, evaluations typically occur every 10 steps, providing sufficient monitoring granularity without excessive overhead.
RFT metrics and their meaning
Amazon Bedrock exposes several training metrics through Amazon CloudWatch and the Amazon Bedrock console that give you a clear picture of whether your RFT job is progressing as expected. Understanding what each metric represents and what anomalies to watch for makes the difference between catching a problem early and waiting hours for a failed run to finish.
Training and validation rewards
The training reward is the average reward on the episodes that you’re training on. The validation reward is the same metric on a held-out set of prompts that don’t contribute gradients. In a healthy run, train reward should climb steadily early on, with validation reward rising more slowly but in the same general direction.
Train and validation episode lengths
These encode the average number of tokens generated per response. Use this to detect verbosity hacking. If lengths explode while rewards increase, the model has learned that longer = better regardless of quality. In reasoning tasks (like Chain Of Thought (CoT)), a gradual increase is healthy (learning to think), but a sudden vertical spike usually indicates a loop or failure. In some cases, you will see a gradual decrease, and that is fine too. That could mean that the model was initially exploring more to get to the answer, but later figures out shorter yet rewarding trajectories.
Policy entropy
Policy entropy measures how confident the model is in its outputs. High entropy means the model is uncertain and still exploring, while low entropy means it’s converging on consistent responses. Over a healthy training run, you’d expect a gentle decline from the initial baseline to a stable plateau as the model learns. A sharp drop to near zero is a warning sign: it typically means that the model has collapsed into repeating a single response rather than reasoning through problems. On the other end, a flat line at a persistently high value suggests the model is ignoring the reward signal entirely and not learning from feedback.
Gradient norm
The magnitude (L2 norm) of the gradients applied to the model at each update. In a stable run it fluctuates within a reasonable band, with occasional spikes; sustained growth or extreme spikes can indicate issues with learning rate, reward scaling, or numeric stability.
Common pitfalls
Even well-configured RFT jobs can run into failure modes that aren’t always obvious from the metrics alone. The two most common are reward hacking—where the model learns to game the reward function rather than improve at the actual task—and reward instability, where high variance in the reward signal undermines the learning process. Both are recoverable, but easier to address if you know what to look for.
Reward hacking
This occurs when the policy learns to exploit weaknesses in the reward function to maximize scores without improving quality. You will see training rewards climb steadily while human evaluation scores degrade or plateau. To mitigate this, ensure that the reward function captures all aspects of the behavior you want encoded through fine-tuning. If not, observe the model generations, and iterate on the reward function. Use strict length penalties in the reward function if needed.
Reward variance and instability
Even with a good average reward, high fluctuation in scores for similar inputs creates a noisy signal that destabilizes training. This manifests as jittery reward curves and wildly oscillating loss metrics. The first line of defense is rigorous normalization: standardize rewards (zero mean, unit variance) within every batch, clip extreme outliers, and ensure your reward inference is deterministic (no dropout), so the optimizer receives a consistent and stable learning signal.
Conclusion
In this post, we demonstrated how to apply Reinforcement Fine-Tuning (RFT) in Amazon Bedrock to improve model performance using feedback-driven training. Using the GSM8K mathematical reasoning dataset as a concrete example, we showed where RFT is most effective, how to structure training datasets, and how to design reward functions that reliably evaluate model outputs. We also explored how to monitor training progress using Bedrock’s training metrics and provided practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases. Together, these components form the core foundation for running successful RFT workflows. When datasets are well structured, reward functions capture the right notion of quality, and training metrics are monitored carefully. RFT can significantly improve model performance across both verifiable tasks (such as reasoning, coding, and structured extraction) and subjective tasks using AI feedback.
Next steps
Ready to start customizing with RFT in Amazon Bedrock? Log in to the Amazon Bedrock console or review the official AWS API docs and create your first RFT training job using the open source models that were fine-tuned for this use-case.
To begin:
- Explore the Documentation: Visit the comprehensive guides and tutorials: Create a reinforcement fine-tuning job
- Try the Sample Notebooks: Access ready-to-run examples in the AWS Samples GitHub repository
- Experiment with your own workloads – Apply the dataset preparation, reward design, and hyperparameter tuning practices covered in this post to your own use cases.
Acknowledgement
Thank you to the contributions from the Amazon Bedrock Applied Scientist team, Zhe Wang and Wei Zhu, who’s experimental work served as the foundation for many of the best practices listed in this blog post.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




