









NVIDIA DGX Spark 赋能 AIPC,GoAgent 数字员工正式上岗
案例简介 *基于内部评测数据,结果因任务类型和测评标准而异 应用技术栈 项目背景 九维图灵作为一家 NVIDIA 初创加速计划会员企业,专注于 AI 智能体技术的研发与商业化落地。公司致力于让每个企业都能用上高质量的 AI 智能体技术,通过生成式 AI 赋能办公自动化、内容创作和业务流程。 GoAgent 平台基于自研的 AIOS (人工智能操作系统) 架构,构建了一套完整的企业级数字员工解决方案: 核心架构: 五大 AI 数字员工 (开箱即用): 企业级特性:

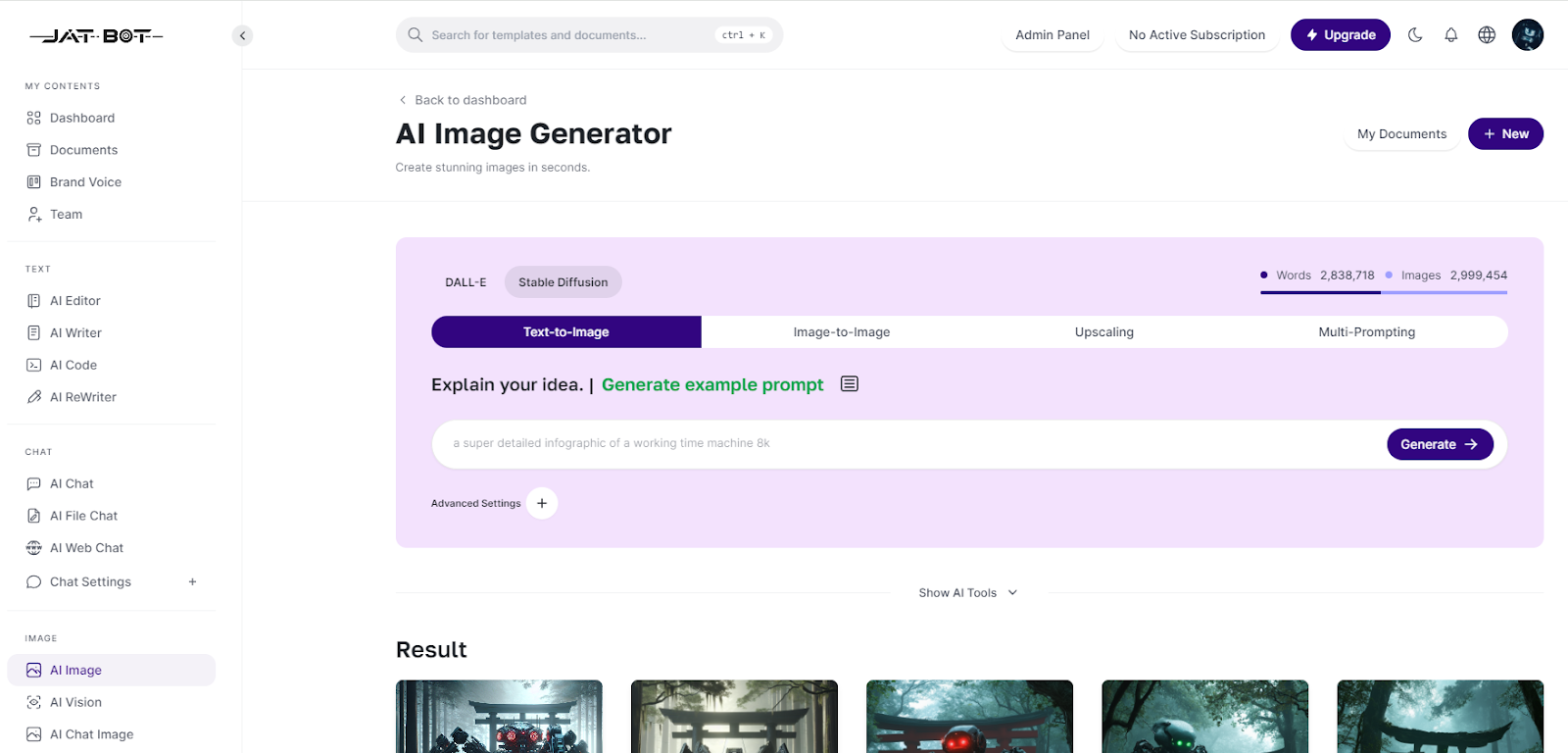
案例简介
- GoAgent 是一个 AI 虚拟数字员工平台,支持多种数字员工以提升用户的办公生产力,并支持直接生成众多格式的文件。
- 本案例中,9Dimension Technology 依托 NVIDIA DGX Spark
 设备 (搭载 GB10 Grace Blackwell Superchip) 的统一内存异构架构,成功实现在 30B 级别模型上生成高质量文档,在特定办公文档生成任务上可达到接近300B通用模型的效果。*
设备 (搭载 GB10 Grace Blackwell Superchip) 的统一内存异构架构,成功实现在 30B 级别模型上生成高质量文档,在特定办公文档生成任务上可达到接近300B通用模型的效果。*
*基于内部评测数据,结果因任务类型和测评标准而异
应用技术栈
- NVIDIA DGX Spark 设备 (GB10 Grace Blackwell Superchip)
- NVIDIA Megatron-LM 分布式训练框架
- NVIDIA NGC 容器镜像
- NVIDIA CUDA 并行计算加速平台
项目背景
九维图灵作为一家 NVIDIA 初创加速计划会员企业,专注于 AI 智能体技术的研发与商业化落地。公司致力于让每个企业都能用上高质量的 AI 智能体技术,通过生成式 AI 赋能办公自动化、内容创作和业务流程。
GoAgent 平台基于自研的 AIOS (人工智能操作系统) 架构,构建了一套完整的企业级数字员工解决方案:
核心架构:
- AIOS 中枢:统一的多智能体协作引擎,支持多数字员工协同完成复杂业务链条
- GoData 知识库:企业级向量知识库,支持向量化语义检索,赋予数字员工”企业记忆”
- GoModel 资源调度:动态算力分配、多级权限管理、模型服务编排
五大 AI 数字员工 (开箱即用):

企业级特性:
- 三级权限分层与细粒度访问控制
- 沙箱隔离机制与完整审计日志
- 全栈本地化部署,数据不出域
- 7×24 小时技术支持与企业级 SLA 保障
GoAgent 已与多家企业客户达成合作,落地智能办公自动化、营销内容快速生产、行业研究报告生成等典型应用场景。平台通过多阶段微调和强化学习方法,在 30B 级别模型上实现了在特定办公文档生成任务上接近 300B 以上参数模型的生成质量。
GoAgent的解决方案
GoAgent 通过 NVIDIA 的全栈技术,实现了从模型训练到推理部署的全面优化:
1. NVIDIA Megatron 加速模型训练
GoAgent 采用了 NVIDIA Megatron Core 分布式训练框架,实现了多阶段微调的高效训练。Megatron 提供张量并行、流水线并行和序列并行等多种并行策略,支持在多个 GPU 上高效训练大语言模型。
借助 Megatron 框架,GoAgent 对训练参数进行了深度优化,实现了长轨迹训练数据的高效训练,训练资源利用率提升显著。这使得团队能够以更低的成本、更快地迭代模型版本,持续优化 Word、Excel、PPT等多种任务的Agent能力。
2. NVIDIA NGC 容器镜像加速推理
在推理部署环节,GoAgent 采用 NVIDIA NGC 优化容器镜像。NGC 目录提供一系列经过性能、安全性和可扩展性测试的 GPU 优化容器,涵盖深度学习、机器学习等应用。
通过使用 NGC 预优化容器,GoAgent 避免了从零构建推理环境的复杂性,实现了开箱即用的 GPU 加速推理。相比自建容器,NGC 镜像的推理性能提升约 20-30%,同时大幅降低了部署和维护成本。
3. NVIDIA DGX Spark 统一内存架构降低推理成本
GoAgent搭载 NVIDIA DGX Spark 设备 (搭载 GB10 Grace Blackwell Superchip)。GB10 Superchip 采用 NVLink-C2C 互连技术,提供 CPU+GPU 一致性内存模型,双向带宽高达 1.8 TB/s,远超传统 PCIe 互联方案。
NVIDIA DGX Spark 配备 128GB LPDDR5x 统一系统内存,CPU 和 GPU 共享数据,避免了频繁的内存复制和同步开销。这种设计带来以下优势:
- 降低显存成本:128GB 统一系统内存既可作为 CPU 内存,也可作为 GPU 显存使用,无需单独购买昂贵的高带宽显存,大幅降低了硬件成本
- 提升推理效率:结合 Blackwell GPU 架构,GB10 提供高达 1 PFLOPS 的 FP4 AI 算力,足以高效运行 30B 参数模型的推理任务
- 高内存带宽:273 GB/s 的内存带宽确保数据传输不会成为推理瓶颈
- 能效优异:GB10 热设计功耗 (TDP) 仅 140W
“NVIDIA DGX Spark 的统一内存架构是我们选择深度合作的关键原因。传统架构中,价格高昂的显存需求使得推理成本居高不下。NVIDIA DGX Spark 采用一致性内存模型,让我们能够以更低的硬件投入,实现甚至超越超大模型的生成质量。”——GoAgent 技术负责人
4. 多阶段微调与强化学习实现质量突破
GoAgent 平台的核心技术突破在于:通过多阶段微调 (Multi-stage Fine-tuning) 和强化学习 (Reinforcement Learning) 方法,在 30B 级别模型上实现了在特定办公文档生成任务上接近 300B 以上参数模型的生成质量。
具体而言,GoAgent 采用以下策略:
- 指令微调 (SFT):使用高质量的 Word、Excel、PPT 生成任务数据对基础模型进行微调,使其掌握文档生成的专业技能
- 偏好对齐 (DPO):通过直接偏好对齐 (Direct Preference Alignment) 技术,将模型的输出与人类的偏好进行对齐,提升模型的生成质量
- 强化学习优化:通过强化学习手段,在基于沙盒环境反馈下,进一步提升生成内容的质量和可用性
- NVIDIA Megatron-LM 加速:利用 Megatron 的张量并行和序列并行技术,高效完成多阶段训练
GoAgent 数字员工通过 Function Call 机制调用 Skills Hub 中的工具,实现从需求理解到文档生成的完整闭环。Skills Hub 内置数据爬虫、文档解析、图表生成、知识库检索等能力,让 AI 数字员工具备执行复杂办公任务的能力。

通过这些技术的结合,GoAgent 成功实现了”小模型、大质量”的突破,在降低推理成本的同时保持了出色的生成质量。
5. 向量数据集驱动的 RAG 增强:让 30B 模型拥有企业级知识
企业知识动态变化——新的产品线、更新的财务数据、调整的排版规范…… 仅靠微调无法实时同步。RAG 的核心理念是:不把知识塞进模型参数,而是在推理时按需检索、精准注入,让小模型也能”站在巨人的肩膀上”生成高质量内容。
GoData 向量知识库的技术实现:
- 多模态 Embedding 编码:采用 BGE-M3 等多功能嵌入模型,同时支持 Dense Retrieval (稠密向量检索)、Sparse Retrieval (稀疏词项匹配) 和 Multi-vector Retrieval (多向量交互) 三种模式,覆盖语义相似度与精确关键词匹配场景
- 智能文档分块 (Chunking):针对不同文档类型采用差异化分块策略——Word 按语义段落切分,Excel 按数据区域/工作表切分,PPT 按幻灯片主题切分,并保留上下文重叠 (overlap) 确保语义连贯性
- 两阶段检索架构 (Retrieve-then-Rerank):第一阶段通过向量数据库 (HNSW 索引) 快速召回 Top-K 候选文档;第二阶段使用 Cross-Encoder Reranker 对候选结果精排序,显著提升检索准确率
- Hybrid Search 混合检索:结合 Dense Retrieval (语义理解) 与 BM25/Sparse Retrieval (关键词匹配),兼顾同义词泛化能力与专有名词/编号的精确召回
- 动态知识更新:企业知识变更后,仅需重新编码增量文档,无需重新微调模型,知识更新从”天级”缩短至”分钟级”
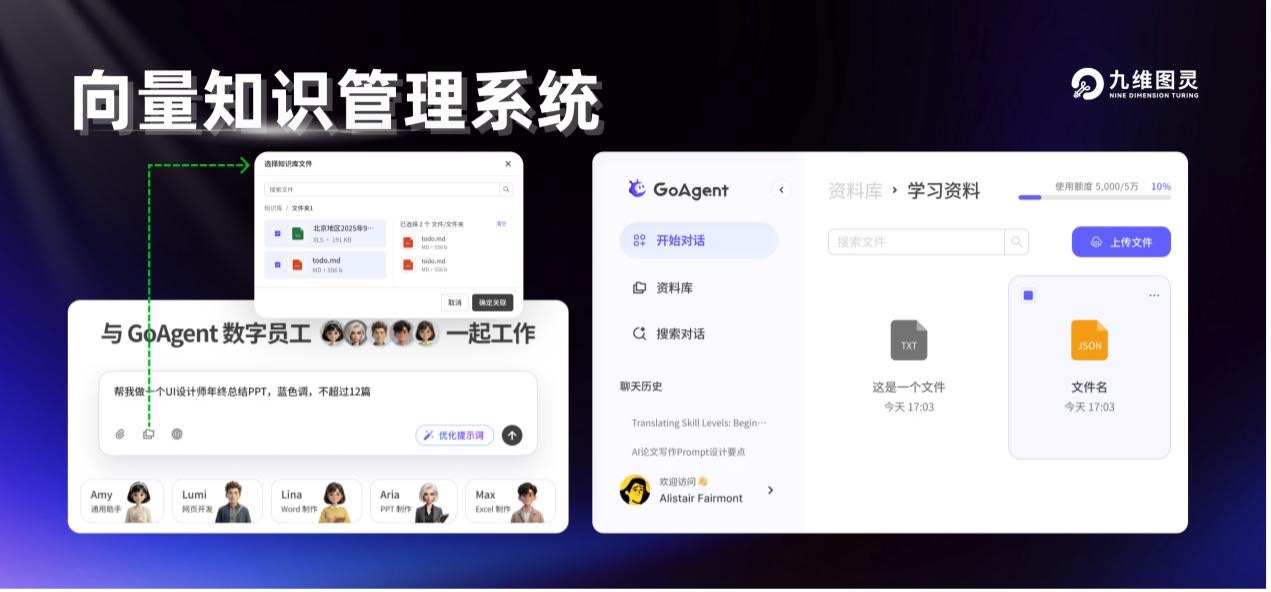
RAG 如何赋能数字员工:
数字员工 RAG注入的知识类型 效果提升 Lina (Word) 企业文档模板、排版规范、历史报告风格 生成文档符合企业品牌标准,格式一致性显著提升 Max (Excel) 行业指标定义、财务计算公式、数据校验规则 报表公式准确率提高,减少人工校对环节 Aira (PPT) 品牌视觉规范、版式模板库、配色方案 演示文稿风格统一,视觉专业度提升 Lumi (Web) 组件库规范、交互设计模式、样式指南 网页符合企业设计系统,开发返工率降低 Amy (通用) 业务流程文档、FAQ 知识库、操作手册 回答准确度提升,任务执行成功率提高
部署架构:RAG 管线与生成模型共置 NVIDIA DGX Spark
RAG 管线中的 Embedding 编码和向量检索需要与生成模型协同工作。GoAgent 充分利用 NVIDIA DGX Spark 的架构特点,实现端到端本地化部署:
- 统一内存降低部署成本:NVIDIA DGX Spark 的 128GB CPU+GPU 统一内存可同时容纳 Embedding 模型 (约 2-4GB)、向量索引和 30B 生成模型,无需单独配置高显存设备,显著降低硬件投入
- 统一寻址减少数据流转:CPU 与 GPU 共享统一地址空间,Embedding 编码、向量检索与文本生成之间的数据传递无需跨设备拷贝,降低编程复杂度与数据同步开销
- 端到端本地部署:从用户提问到知识检索再到文档生成,全流程在 NVIDIA DGX Spark 本地完成,数据不出域,满足企业数据安全合规要求
通过 RAG 增强,GoAgent 的 30B 模型不再受限于参数记忆,而是拥有了动态更新的企业级知识底座,真正实现了”小模型、大知识、高质量”的突破。
6. Harness Engineering 管控体系:从“聪明”到“可靠”的关键跨越
GoAgent 的架构设计在实践中形成了一套完整的 Agent 管控体系,这与 2026年AI Agent 领域最热门的核心概念——Harness Engineering (驾驭工程) 高度契合。
GoAgent的前瞻性实践
- 上下文工程 (Context Engineering):不同于简单的对话历史拼接,GoAgent实现了多轮交互中的智能上下文压缩与关键信息萃取,让Agent在长达数小时的任务执行中始终保持连贯的“思维链”
- 外化记忆系统 (GoData):将企业知识向量化存储,形成可检索、可更新的持久记忆层——正如 Harness Engineering 所强调的“Memory is just a form of context”,GoAgent早早便让数字员工拥有了真正的“企业记忆”
- 环境隔离与约束机制:通过沙箱化执行环境、分级权限管控,为 Agent 划定安全边界——这与Harness “构建让AI不容易犯错的环境”的理念异曲同工
- 反馈回路设计:从结果验证到审计追踪,形成完整的自纠正闭环,确保输出质量可控可溯
这一架构让GoAgent的数字员工能够稳定、可靠地完成复杂的办公文档生成任务,实现了从“聪明”到“可靠”的关键跨越,也是 Harness Engineering 所追求的终极目标。
影响
NVIDIA 的全栈技术切实推动了 GoAgent 的技术、产品和业务层面的全面突破:
技术层面:NVIDIA Megatron Core 分布式训练框架通过张量并行、序列并行等技术,使 GoAgent 能够在有限的显存资源上高效训练30B参数模型,显著降低了训练硬件成本。NVIDIA NGC 容器镜像提供了开箱即用的 GPU 优化推理环境,确保了部署的稳定性和一致性。NVIDIA DGX Spark 的统一内存架构大幅降低了推理硬件成本,使 30B 模型的高质量推理成为可能。在推理加速方面,团队针对 VLLM 引擎进行了深度调优,通过优化调度策略、批处理参数及 KVCache 管理,结合 MoE 模型的稀疏计算优势,成功将 token 生成速率从 45 tokens/s推升至 100 tokens/s,响应延迟降低 55%,吞吐量实现翻倍有余。NVIDIA CUDA 并行计算平台为训练和推理全流程提供底层算力加速,确保核心算子的高效执行。
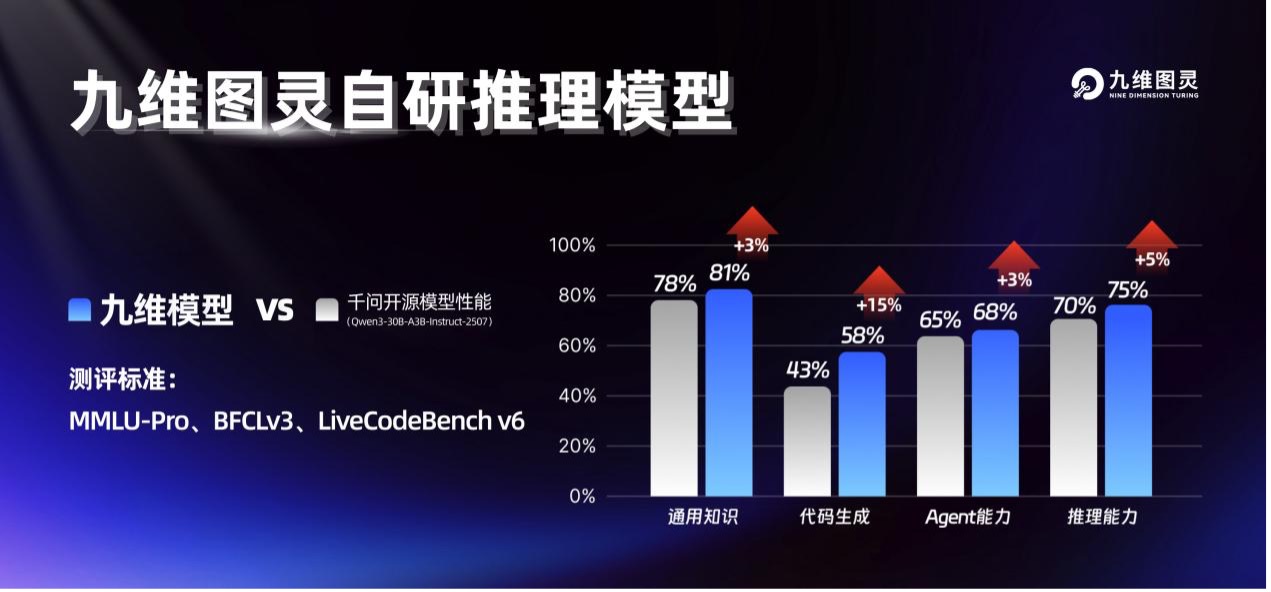
产品层面:借助 NVIDIA 技术,GoAgent 成功实现在 30B 级别模型上生成质量在特定办公文档生成任务上接近 300B 以上参数模型的 Word、Excel、PPT 和网页内容。在智能体能力分级方面,GoAgent 率先突破 30B 参数规模的 L3 级门槛。——这意味着模型能够在复杂办公场景中自主规划、调用工具并完成多步步骤任务,而无需人工逐步确认。横向评测数据亮眼:NMLU-Pro 知识推理达 81% (较基线提升约 3 个百分点)、BFCLV3 工具调用能力达 68% (提升约 3 个百分点)、LiveCodeBenchv6 代码生成能力达 58% (提升约 15 个百分点),三项指标全面验证了其作为”数字员工”的实战价值。这使得 GoAgent 平台能够以更具竞争力的成本为客户提供高质量的 AI Agent 服务。
业务层面:作为 NVIDIA 初创加速计划会员,GoAgent 获得了 NVIDIA 的技术指导、市场支持和商务对接机会。NVIDIA 初创加速计划提供的技术资源、云服务商 GPU credits 以及行业曝光机会,对 GoAgent 的快速发展起到了关键推动作用。
“AI Agent 的未来不仅仅是单个模型的能力提升,更是整个工作流的重构。NVIDIA 提供的 GPU 解决方案和全栈技术栈,解决了我们在模型训练和推理部署中的核心难题。NVIDIA初创加速计划的技术支持和市场资源,让我们在 AI Agent 领域能够快速创新和商业化落地。我们与 NVIDIA 初创加速计划的合作才刚刚开始,未来会有更多创新面向企业和开发者推出。”——九维图灵创始人兼 CEO 表示。
注: 本文中图片由九维数智提供,如果您有任何疑问或需要使用图片,请联系九维数智。
NVIDIA 初创加速计划
九维数智 (上海) 科技有限公司是 NVIDIA 初创加速计划会员企业。
NVIDIA 初创加速计划 (NVIDIA Inception) 为免费会员制,旨在培养颠覆行业格局的优秀创业公司。该计划联合国内外知名的风投机构、创业孵化器、创业加速器、行业合作伙伴以及科技创业媒体等,打造创业加速生态系统。能够提供产品折扣、技术支持、市场宣传、融资对接、业务推荐等一系列服务,加速创业公司的发展。





