









NVIDIA 推理软件栈如何助力实现更低 Token 成本
随着企业从 AI 试点转向生产型 AI 工厂,基础设施的决策核心已从芯片峰值规格转向每 Token 成本:即每美元、每瓦特以及在规定的延迟目标内能够交付多少有用的 Token。 NVIDIA 的全栈推理软件与 NVIDIA GPU、CPU、网络和系统协同设计,并在广泛的开源生态系统支持下,持续提升硬件性能。在 NVIDIA Blackwell 平台上,该软件栈仅在一个月内就已经将 DeepSeek V4 模型的 Token 成本降低至原来的五分之一。 领先的企业与推理服务提供商已经看到了 NVI

随着企业从 AI 试点转向生产型 AI 工厂,基础设施的决策核心已从芯片峰值规格转向每 Token 成本:即每美元、每瓦特以及在规定的延迟目标内能够交付多少有用的 Token。
NVIDIA 的全栈推理软件与 NVIDIA GPU、CPU、网络和系统协同设计,并在广泛的开源生态系统支持下,持续提升硬件性能。在 NVIDIA Blackwell 平台上,该软件栈仅在一个月内就已经将 DeepSeek V4 模型的 Token 成本降低至原来的五分之一。
领先的企业与推理服务提供商已经看到了 NVIDIA 推理软件栈在 Blackwell 上带来的复利价值:
- Baseten 使用 NVIDIA TensorRT LLM 开源库在 Blackwell GPU 上运行 DeepSeek V4 Pro,用于推理、编码和长上下文工作负载,并应用专有的运行时优化,将每秒生成的 Token 数量提升了高达 50%。
- Cognition 正在使用 NVIDIA Dynamo 推理框架来管理推理 GPU,为其团队提供了一条现成的路径,无需从头开始构建基础设施即可扩展强化学习工作负载。
- Deep Infra 使用 NVIDIA 推理软件栈,从发布首日起便在 Blackwell 上高效提供包括 DeepSeek V4 在内的前沿开源模型服务。
- DigitalOcean 协助 Hippocratic AI 在 Blackwell GPU 上使用 NVIDIA 推理软件,更快捷且高效地提供医疗 AI 服务。此举不仅将推理吞吐量提升了 30%,更在高达 1,000 万次的患者呼叫中,将首次响应时间维持在半秒以内。
- Together AI 在 Blackwell 上使用 NVIDIA TensorRT LLM,帮助 Cursor 加速从模型优化到生产端点的路径,以实现实时编码体验。
软件为何对推理经济学至关重要
传统的网络、搜索和软件即服务工作负载相对可预测:用户可能会加载页面、刷新信息流或更新业务记录。这些请求通常会遵循类似的软件路径,从数据库中读取或写入数据,并通过添加更多相同服务器来扩展。
代理式 AI 则不同。
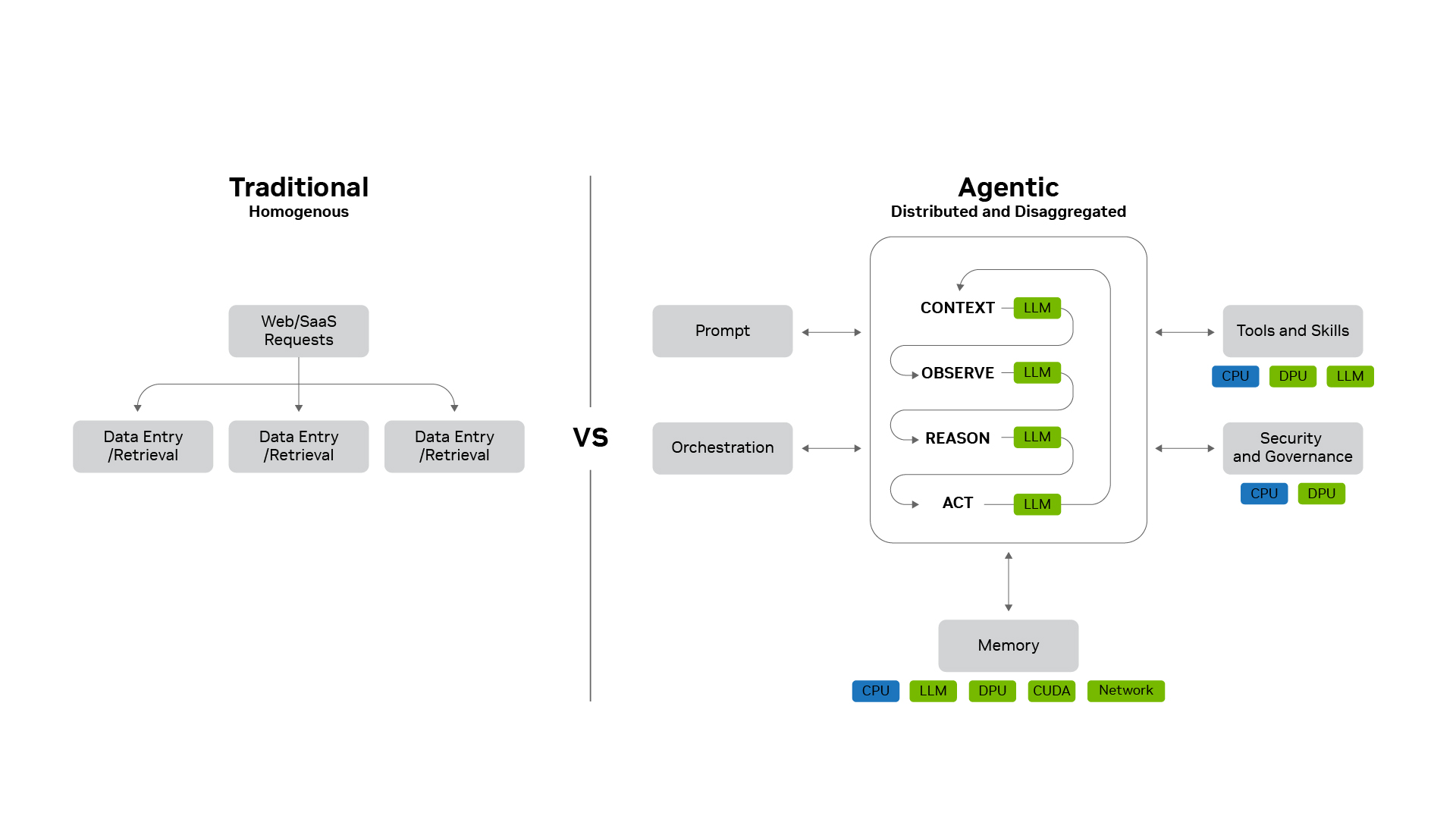
智能体能够进行推理、规划、调用工具、启动专用子智能体,并在多轮工作流中管理海量上下文。它们将单个请求转化为分布式计算问题,该问题可以涉及数百个子智能体、数千项任务和多个大语言模型,并在 GPU、CPU、DPU 和存储系统上运行。
软件栈决定了这种复杂性是否会变成容量的浪费,还是转化为更低的每 Token 成本。
降低每 Token 成本的关键在于将单点优化转化为系统级性能。NVIDIA 推理软件栈通过连接以下三个层级来实现这一点:
- 生产运营:协调分布式服务、编排、自动扩展和内存管理,以便在合适的计算和存储资源上运行推理。
- 应用加速:在运行高性能模型的同时,通过使用计算和通信重叠以及内核融合等运行时优化技术,为开发者提供调优和定制的空间。
- 基础设施访问:开放 NVIDIA GPU、网络、内存和系统功能,无需开发者直接管理每个设备指令集或数据传输协议。
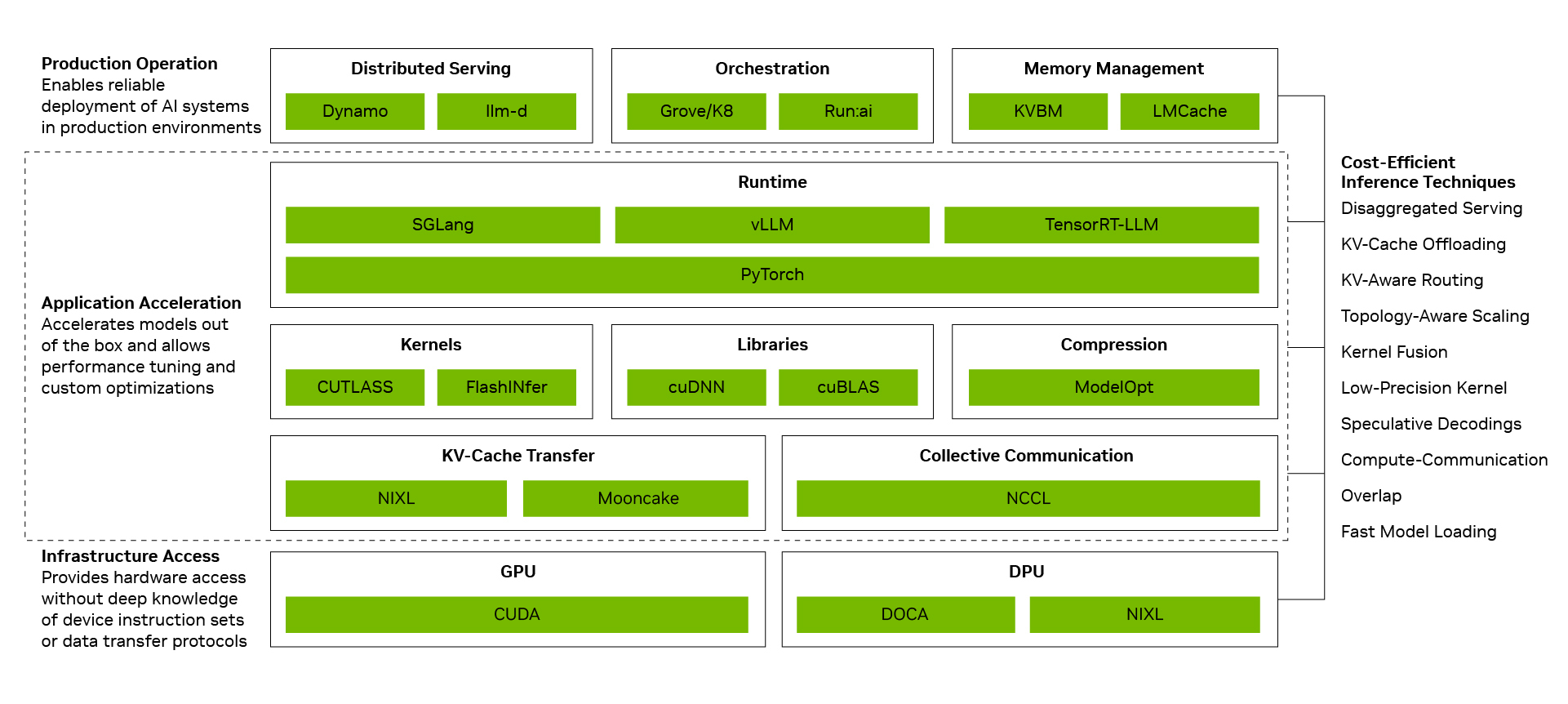
当这些层级作为一个统一的系统工作时,单点优化便会产生复利效应。
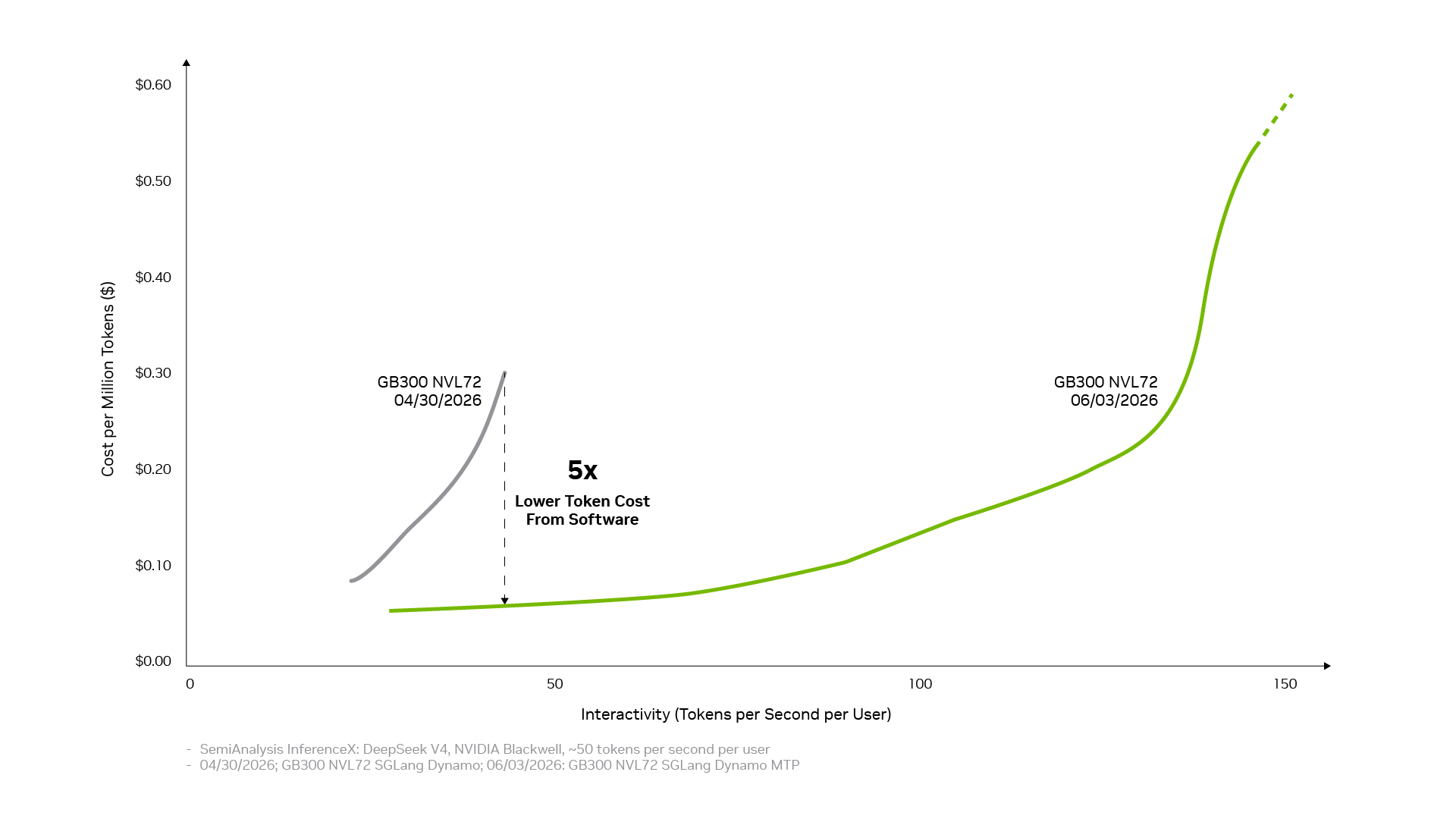
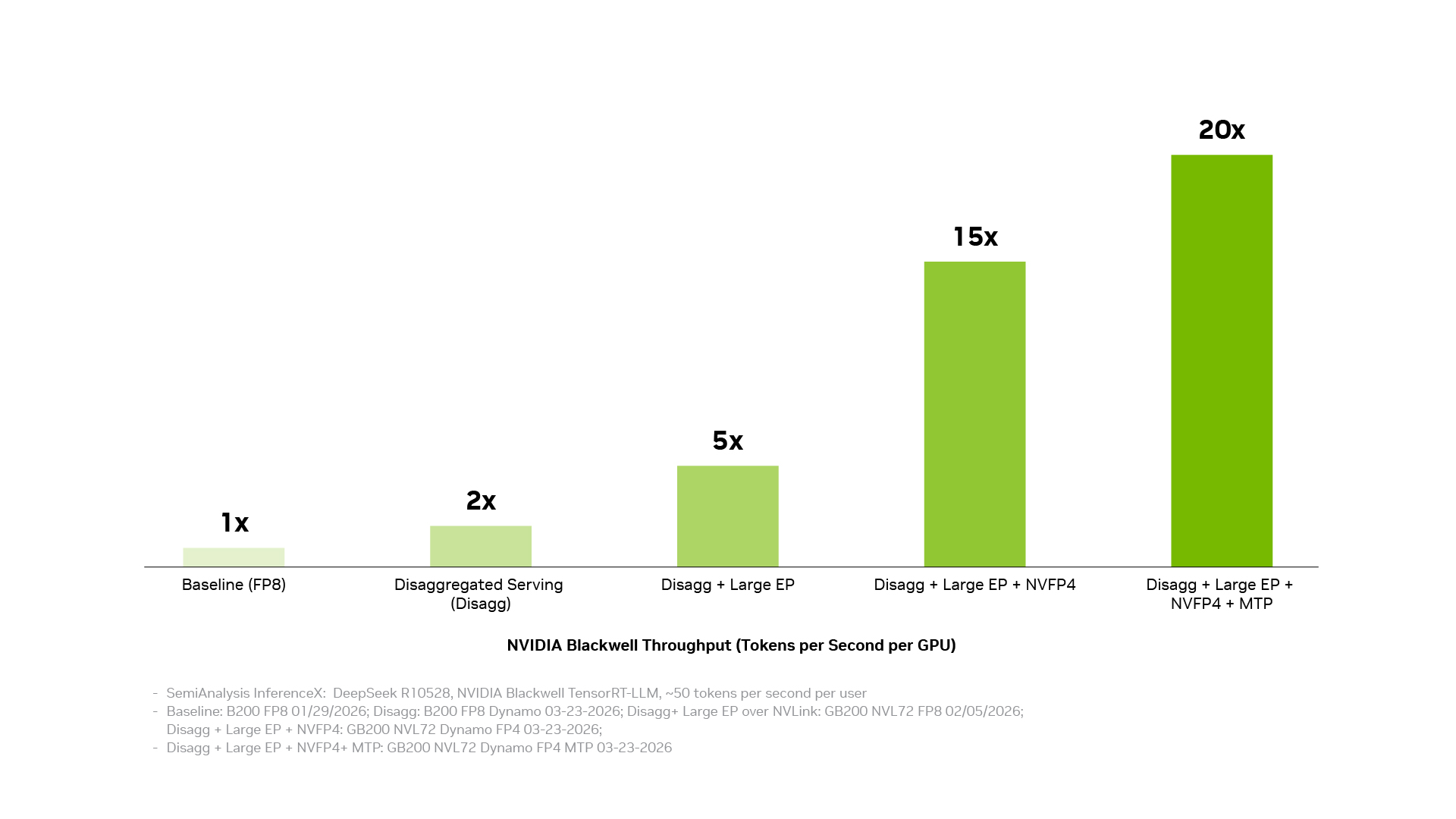
分离式服务、基于 NVIDIA NVLink 互连技术的大规模专家并行、NVFP4 精度和多 Token 预测,每一项技术都能带来显著提升。而当它们相结合,能够将吞吐量提升高达 20 倍。
下图显示了这一结果。在生产环境中实现这种收益十分复杂,需要整个推理堆栈的协同配合 —— 从生产运营和模型运行时,到内核、通信库和硬件访问。NVIDIA 推理软件栈旨在让这些层级协同工作,使每项优化都能建立在其他优化基础之上。
开源生态放大全栈优势
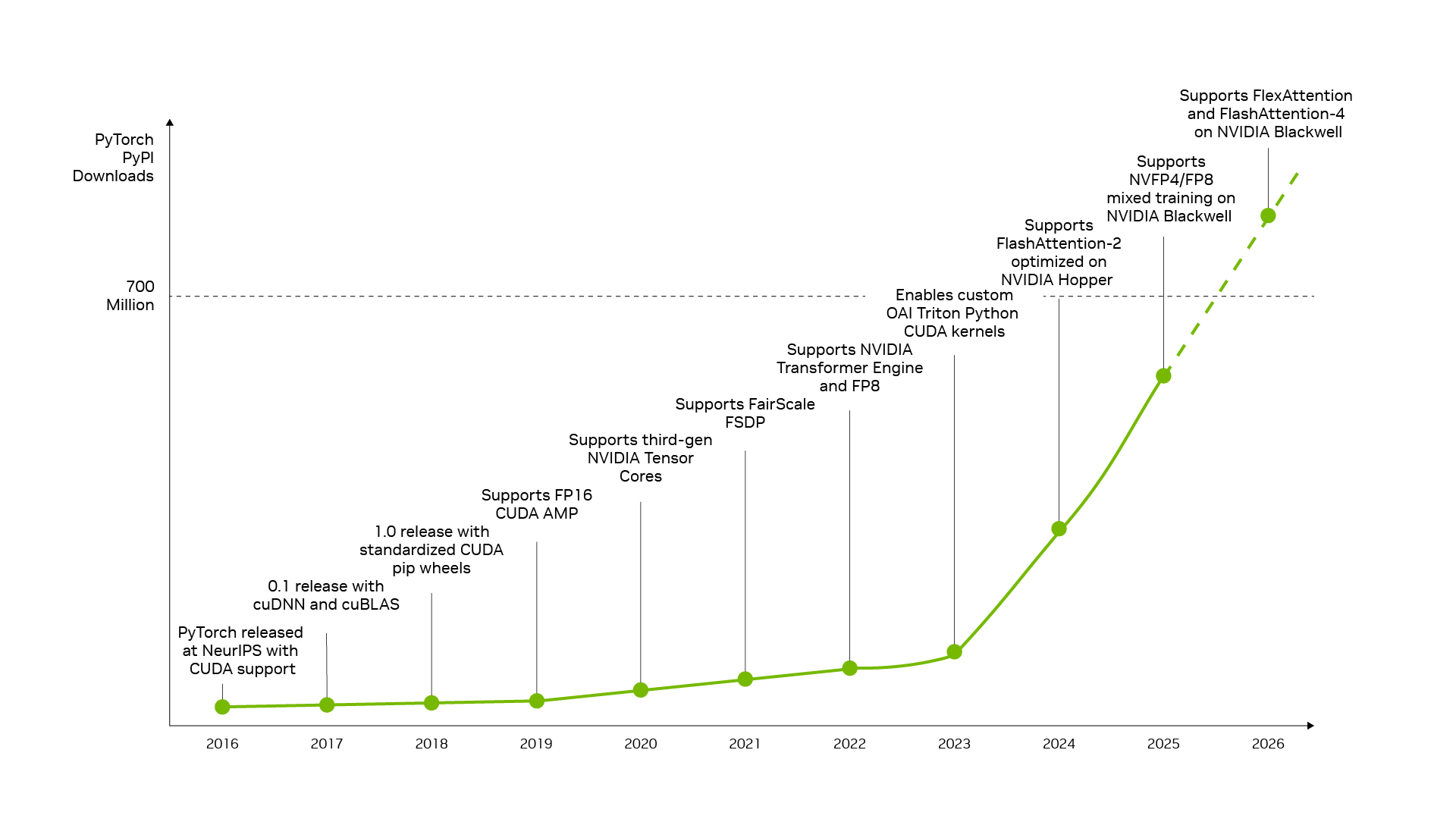
同样的全栈基础在开源生态系统作用下进一步被放大。当今许多广泛使用的开源 AI 框架和推理项目都是基于 NVIDIA CUDA 原生构建的,这意味着从发布首日起,新的研究和软件优化即可在 NVIDIA GPU 上以具有优势的性能运行。
PyTorch 就是一个典型的例子。PyTorch 于 2016 年发布并支持原生 CUDA,它与 NVIDIA 架构共同演进,使开发者能够通过熟悉的框架直接使用 Tensor Core、Transformer Engine 和 NVFP4 等创新技术。
当例如 DFlash 投机解码 (可在现有硬件基础上提供高达 15 倍的吞吐量),或 FastVideo (在五秒内生成 1080p 视频) 这样的突破性成果落地 PyTorch 时,它们可以立即在 NVIDIA 上运行,帮助 AI 工厂将研究进展转化为更低的 Token 成本。
同样的开源势头也解释了为什么在发布 DeepSeek V4 等全新前沿开放模型时,像 vLLM 和 SGLang 等优秀的推理框架能为 NVIDIA Blackwell 架构提供首日部署方案 —— 使模型能够在数百万个 Blackwell GPU 上运行。这也是为什么在 vLLM 和 SGLang 框架下,DeepSeek V4 在 Blackwell 上的性能在约一个月内提升了高达 5 倍,将 Token 成本降低到之前水平的约五分之一。
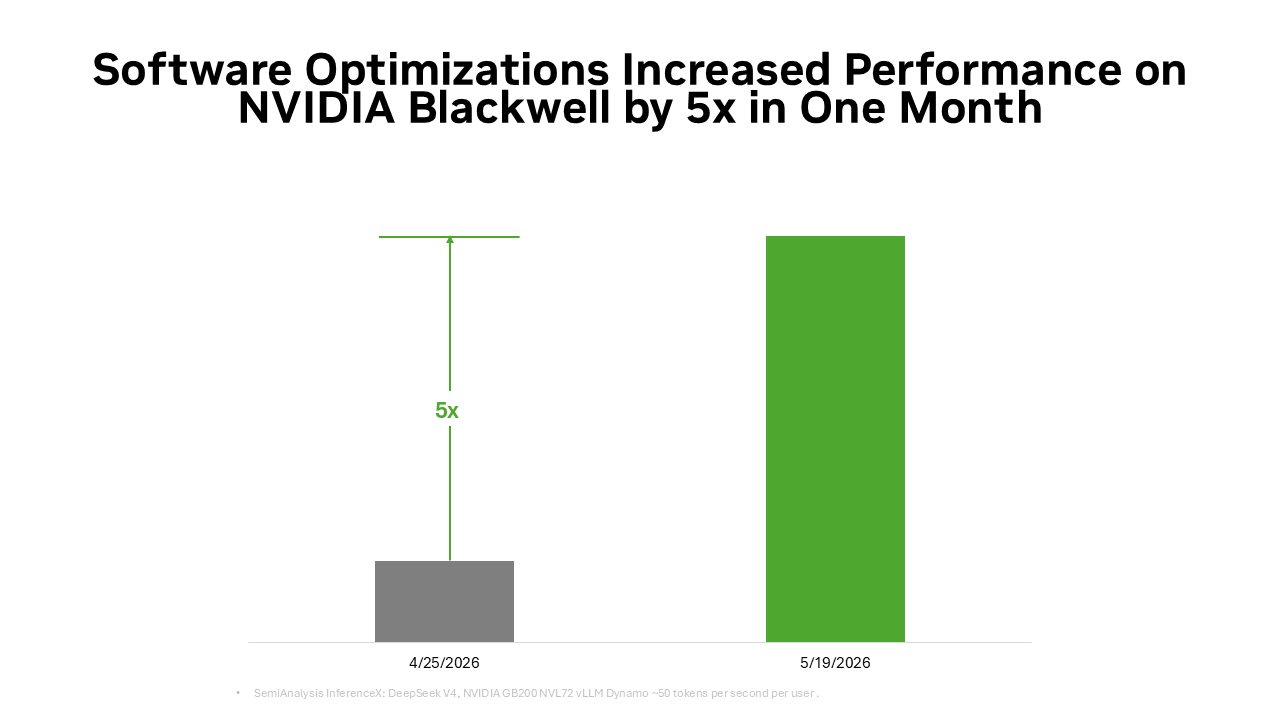
这就是开源的飞轮效应:越来越多的开发者优化 CUDA 原生推理路径,就会有越来越多的生产部署反馈到生态系统,每一次软件改进都会增加交付的 Token 输出,同时降低每 Token 成本。
请在关于 Token 经济学的 NVIDIA AI 播客和该推理解决方案页面,探索软件如何成倍提升硬件性能。





