
























Build custom code-based evaluators in Amazon Bedrock AgentCore
In this post, you will implement four Lambda-based custom code evaluators for a financial market-intelligence agent, register each with AgentCore, and run them in on-demand and online modes. You will also see how to combine custom code-based evaluators with built-in evaluators and how to call other AWS services for grounded fact-checking, PII detection, and real-time alerting.

Special thanks to everyone who contributed to this launch: Stephanie Yuan, Lefan Zhang, Ritvika Pillai, Irene Wang, Carter Williams, T.J Ariyawansa, Gitika Jha, Shoaib Javed and the product leadership from Vivek Singh.
Moving prototype agents to production requires measuring quality across multiple dimensions. Amazon Bedrock AgentCore Evaluations provides large language model (LLM)-as-a-Judge checks and extensible code-based evaluators that capture domain-specific requirements you need for assessing your agentic application.
In financial services and specialized domains, the critical quality dimensions often extend beyond language. A market-intelligence agent must quote stock prices within a configurable live band, follow a mandatory broker-identification workflow before accessing financial profiles, return tool outputs that conform to a strict JSON schema, and withhold personally identifiable information (PII). These checks require deterministic code that produces the same result on identical input. They can also be expensive to run with LLM-as-a-Judge when an objective piece of code is the straightforward choice.
With custom code-based evaluators, you can bring an AWS Lambda function as the evaluation engine. With custom code-based evaluators, you control the scoring logic: regex and structural validation, external data lookups, calls to other services, or business rules. The same evaluator can be used in multiple ways without requiring foundation model (FM) tokens for each request. In on-demand evaluations, it acts as a gate within development workflows and continuous integration and delivery (CI/CD) pipelines. In online evaluation setups, it can score live production traffic. With full control over the evaluation logic through AWS Lambda, you can tailor custom code-based evaluators to your needs. Even if traces come from different agent frameworks, you can use this approach to consistently assess agent quality using your own logic.
In this post, you will implement four Lambda-based custom code evaluators for a financial market-intelligence agent, register each with AgentCore, and run them in on-demand and online modes. You will also see how to combine custom code-based evaluators with built-in evaluators and how to call other AWS services for grounded fact-checking, PII detection, and real-time alerting.
Quality dimensions suited to code-based evaluation
Agents depend on structured tool outputs like JSON from search, retrieval, or business APIs. A contract change, parsing bug, or upstream outage can produce malformed data that the agent weaves into a wrong answer. Tool response schema validation catches structural issues at the tool boundary and is well suited as a code-based check, while LLM-as-a-Judge evaluators complement it to judge usefulness and clarity.
Agents quote prices, metrics, thresholds, and quotas, and deviations as small as 0.1 percent can change a financial trading decision. LLMs are prone to arithmetic errors, while a code-based evaluator calls the reference system, computes the tolerance, and flags each discrepancy. Numerical accuracy against a reference source is most effectively verified deterministically.
Agents operating under ordering and policy constraints should identify the user before reading sensitive data, capture approvals before executing actions, and follow a specific tool sequence to maintain data integrity. Verifying workflow contract compliance requires inspecting the sequence of tool calls across a session. A code-based evaluator checks that the agent followed the process, and LLM-as-a-Judge measures how well it communicated the outcome.
Agents working over profiles, documents, or logs must withhold names, account IDs, contact details, and secrets. A response that exposes this data is a compliance or security failure. Code-based evaluators call PII-detection or secret-scanning services and enforce hard rules on response content, complementing language-quality and helpfulness scores.
Paired with LLM-as-a-Judge evaluators, code-based checks validate both how the agent communicates and whether it respected contracts, numbers, workflows, and data-handling rules. This combination moves agent reliability from “sounds right” to contract-verified.
Evaluator lifecycle: from spans to scored results
A code-based evaluator is a Lambda function registered with the AgentCore control plane. When an evaluation runs, AgentCore assumes an AWS Identity and Access Management (IAM) role in your account, invokes the Lambda with a payload containing the agent’s OpenTelemetry (OTel) spans, and writes the Lambda response to Amazon CloudWatch Logs as an evaluation result. The payload contains a schema version, evaluator ID, evaluator name, evaluation level, and an evaluation input object holding the array of OTel spans for the session. For trace-level evaluators, a separate evaluation target field identifies the specific trace to score. For session-level evaluators, AgentCore omits the target and the Lambda scores the full conversation.
The Lambda response follows a fixed contract. On success, it returns a dictionary with a label (for example, PASS or FAIL), an optional numeric score between 0.0–1.0, and an optional explanation string. On failure, it returns a dictionary with an error code and an error message. You must include a label on every success response. The score and explanation fields are optional, but feed directly into CloudWatch metrics and the AgentCore Observability dashboard, which helps you debug when your scores are low.Every evaluator runs at one of three levels set at registration: TRACE, TOOL_CALL, or SESSION, as shown in following figure. To score the same Lambda at multiple levels, register it separately at each level pointing to the same function.
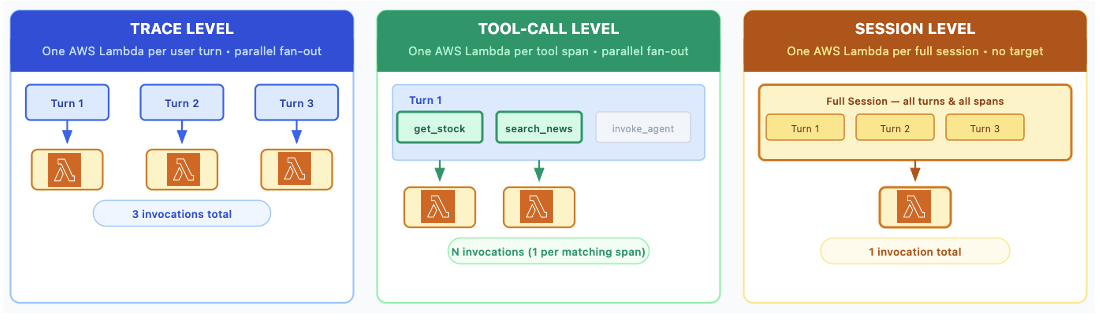
Figure: Code based evaluators are registered separately at each level: trace, tool call and session.
On-demand and online modes of custom code-based evaluators
AgentCore Evaluations supports code-based evaluators in both on-demand and online modes. A single evaluator ID is used for development, testing, continuous integration and delivery (CI/CD) gates, and continuous production monitoring. The Lambda contract, including the payload, response format, and IAM configuration, remains the same in both modes. The following figure illustrates the flow for online evaluation; on-demand evaluation follows the same path, with the Evaluate API call replacing the scheduled sampling step.
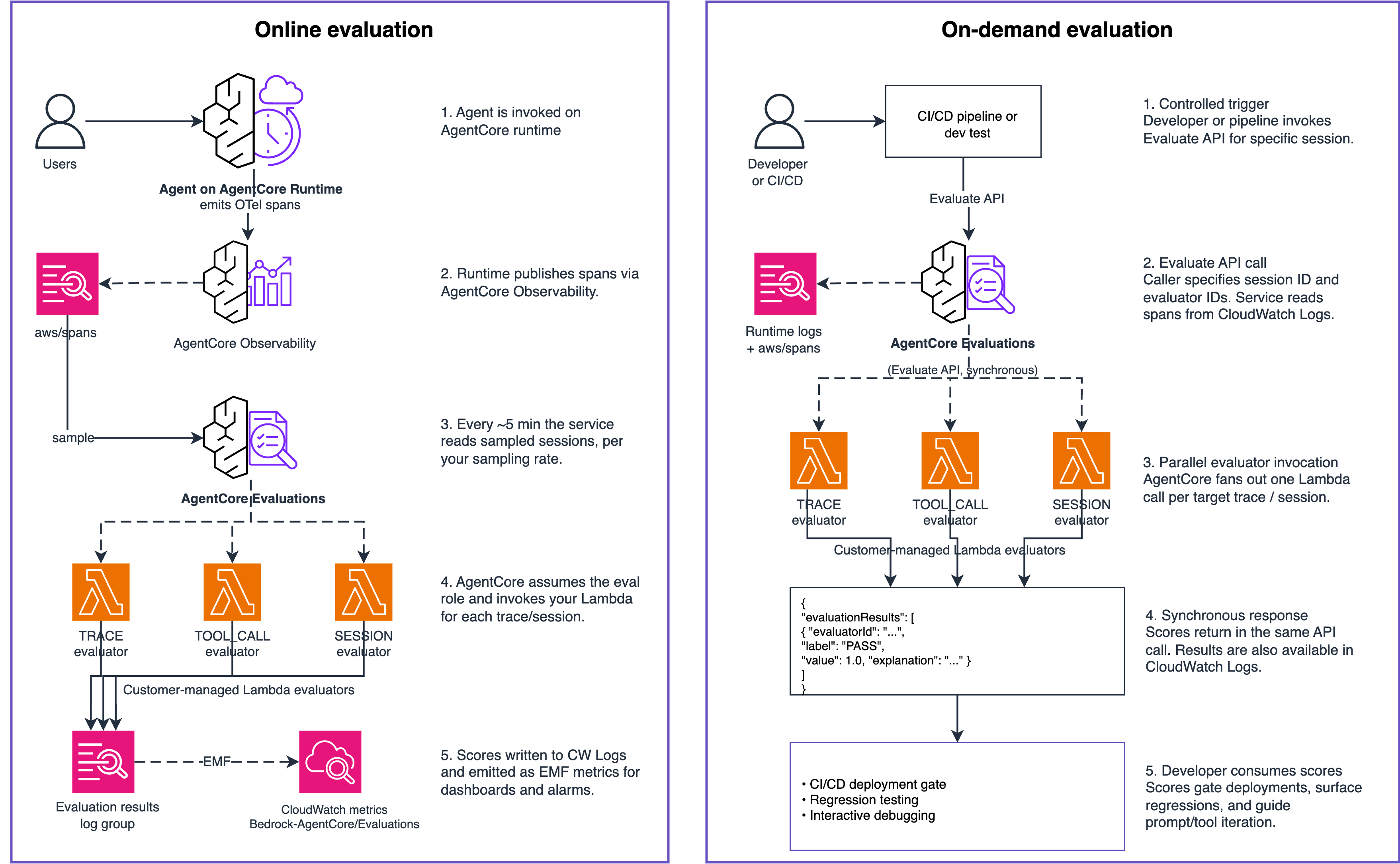
Figure 2: End-to-end flow for a code-based evaluator in online evaluation.
On-demand evaluation for development and CI/CD
On-demand evaluation fits three scenarios:
- Development iteration. Capture a session, run the evaluator suite, inspect per-evaluator scores and explanations, and use the feedback to guide the next change to the prompt, tool definitions, or memory workflow.
- Regression testing. Maintain a library of representative sessions, including sessions that previously revealed failures, and run the evaluator suite against them in your test suite. An evaluator that scores below threshold signals a regression.
- CI/CD deployment gate. Before promoting a new agent version to production, run the evaluator suite against a set of smoke-test sessions and block the deployment if a code-based evaluator fails.
A single on-demand call can reference up to 10 evaluators across code-based and built-in types. For the Market Trends Agent, a pre-deployment pass runs the Helpfulness and Correctness built-in evaluators alongside the four code-based evaluators. The combined result confirms language quality, tool contract integrity, price accuracy, workflow ordering, and PII safety in one pass.
Online evaluation for continuous production monitoring
Online evaluation continuously samples live agent traffic and scores it against configured evaluators on a recurring schedule. To set up online evaluation, you need to create an online evaluation configuration once through the AgentCore control plane, specifying:
- Evaluators: up to 10 evaluator IDs, mixing code-based and built-in types
- Data source: CloudWatch log group and OTel service name for the agent’s spans
- Sampling: the percentage of sessions to evaluate (0.01–100 percent)
The online evaluation is attached to an agent by directly pointing it to the agent on AgentCore Runtime or by referencing the CloudWatch log group used by the agent. AgentCore then uses these data source settings to find completed sessions by grouping spans that represent an entire conversation for that agent and running evaluation on them.
You can fine-tune how much traffic gets evaluated by setting the sampling percentage anywhere between 0.01–100 percent. You also set a session timeout, which tells AgentCore how long to wait after the last span before treating a session as complete. This timeout should match your agent’s typical session duration so that you avoid scoring sessions that are still in progress.
After the configuration is enabled, AgentCore takes care of the recurring schedule for you. For each sampled session, it reads spans from CloudWatch, invokes each evaluator you configured, and writes the evaluation results into a dedicated evaluation-results CloudWatch log group. When it does this, AgentCore assumes the evaluation execution IAM role defined in the configuration, so the Lambda and CloudWatch permissions attach to that role instead of to the agent’s runtime role.
Every evaluator score also shows up as a CloudWatch metric in Embedded Metric Format under the Bedrock-AgentCore/Evaluations namespace, keyed by evaluator name and configuration ID. With this, you can build CloudWatch dashboards that plot schema validity, workflow compliance, and PII cleanliness alongside Helpfulness and Correctness, providing a unified view of both language and structural quality. On top of that, you can configure CloudWatch Alarms on these metrics to alert your operators whenever a particular quality dimension slips below an important threshold.
Solution overview
In this solution, we use a Market Trends Agent as an example. The Market Trends Agent is an investment-intelligence assistant built on LangGraph and deployed to Amazon Bedrock AgentCore Runtime. The full sample is at 02-use-cases/market-trends-agent in the AgentCore samples repository. The agent serves financial brokers with stock data, multi-source news analysis, and broker profiles stored in AgentCore Memory, tailoring analysis to each broker’s strategy, interests, and risk tolerance.
The agent exposes tools for stock price retrieval, financial news, search, broker identity extraction, profile reads and writes, and market briefing generation. LangGraph’s OTel instrumentation publishes spans to Amazon CloudWatch through AgentCore Observability, making the agent a testbed for code-based and LLM-as-a-Judge evaluators. We use this agent to demonstrate how to set up custom code-based evaluations in online and on-demand modes.
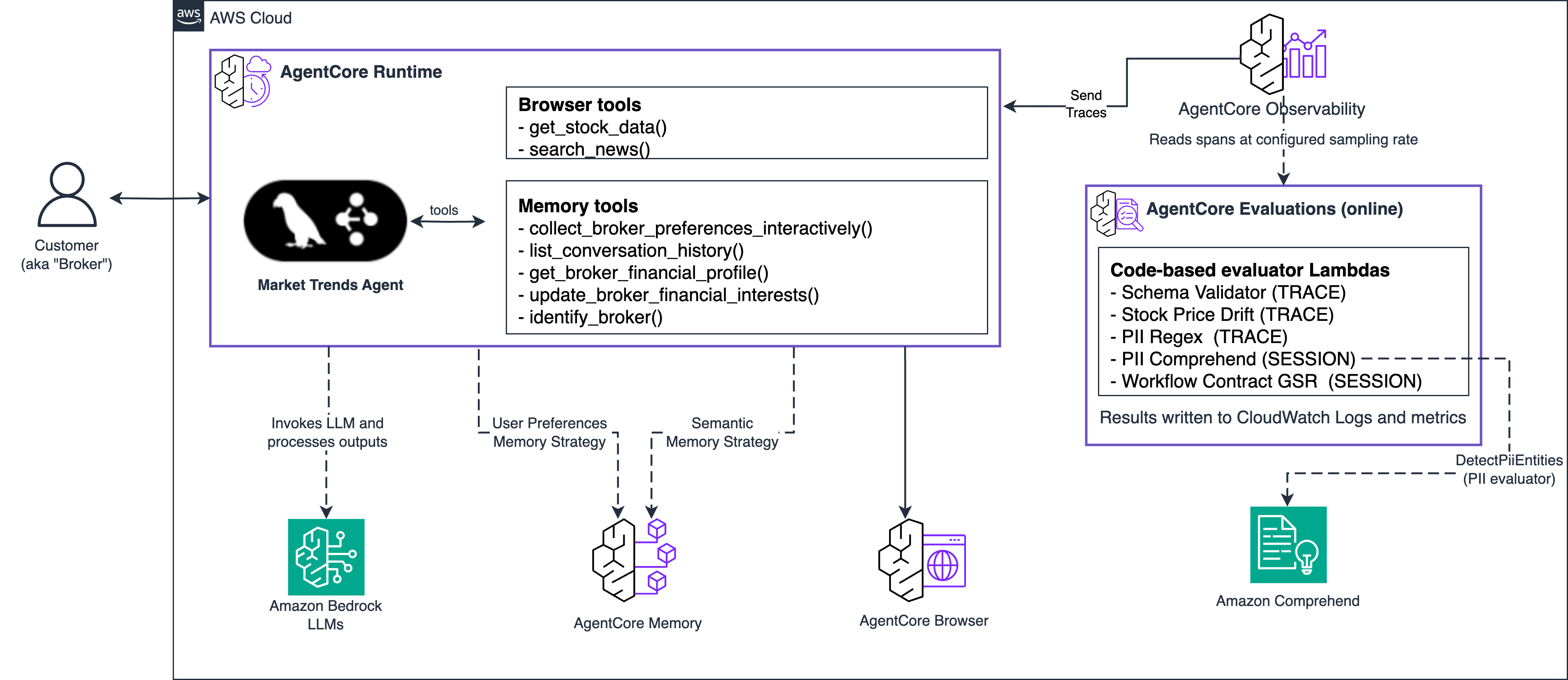
Figure 3: Architecture of Market Trends Agent
The sample includes four evaluators covering schema validation, numerical accuracy, workflow compliance, and PII detection.
- ToolResponseSchemaValidator (trace level) – This evaluator filters spans to the target trace, identifies tool-call spans, and checks each tool’s response against an expected pattern—ticker and price for stock data, length and formatting for news summaries.
- StockPriceDriftChecker (trace level) – Verifies prices quoted in the agent’s responses against an external source of truth within a configurable tolerance (default 2 percent). This evaluator extracts ticker-plus-price pairs from the response text, fetches reference prices from a market data endpoint, and computes the percent deviation per pair.
- WorkflowContractGSR (session level) – Enforces a three-step workflow contract across the session: identify the broker, operate on the broker profile, then call market data and news tools. This evaluator reconstructs the ordered list of tool calls from session spans and verifies that each step occurred in order.
- BrokerPIILeakChecker (session level) – Scans every agent response in a session for PII using the Amazon Comprehend DetectPiiEntities API. The Lambda classifies detected entities into high-risk types (SSN, payment card, bank account, government ID, credential) and lower-risk contact details (name, email, phone, address), applying different thresholds to each. High-risk PII returns FAIL; overuse of lower-risk PII returns a partial score with counts. A regex-based variant is included for environments that cannot depend on Comprehend.
Prerequisites
This walkthrough takes 45 minutes of hands-on time and costs under $5 in AWS charges at default sampling rates. To follow along, you need:
- An AWS account with an IAM role granting access to Amazon Bedrock AgentCore Runtime, Memory and Evaluations, AWS Lambda, Amazon CloudWatch.
- The AWS Command Line Interface (AWS CLI) installed and configured with permissions to deploy AgentCore resources, Lambda functions, CloudWatch logs, and (optionally) Amazon Comprehend.
- AgentCore Observability and CloudWatch Transaction Search enabled, so OTel spans land in both the runtime log group and the shared aws/spans log group. Transaction Search is a one-time account-level opt-in. AgentCore Evaluations cannot sample spans without it. Evaluations cannot sample spans without it.
- The agentcore-samples repository cloned.
Implementation steps
The full sample, including the agent code, all four evaluator Lambdas, and the deployment scripts, is available in the market trend agent directory Follow the README there to complete these steps:
- Deploy the Market Trends Agent — a single uv run python
deploy.pycommand provisions the AgentCore Runtime, Memory, IAM role, and Amazon Elastic Container Registry (Amazon ECR) container. - Deploy the evaluators —
uv run python evaluators/scripts/deploy.pypackages the four Lambda functions, creates the IAM roles, registers each evaluator with the AgentCore control plane, and creates an online evaluation configuration at 100 percent sampling. - Generate test traffic — uv run python
evaluators/scripts/invoke.pyruns four built-in scenarios (happy-path broker workflow, returning broker, PII bait with a fabricated SSN, and anonymous chitchat) to produce sessions that exercise passing, failing, and edge-case behaviors. - Run on-demand evaluation — use the AgentCore CLI or SDK to evaluate a specific session synchronously, inspect per-evaluator labels and explanations, and validate behavior before promoting to production.
- View online evaluation results — uv run python
evaluators/scripts/results.pypulls scored results from CloudWatch, grouped by evaluator. Results also appear as CloudWatch metrics under the Bedrock-AgentCore/Evaluations namespace for dashboards and alarms.
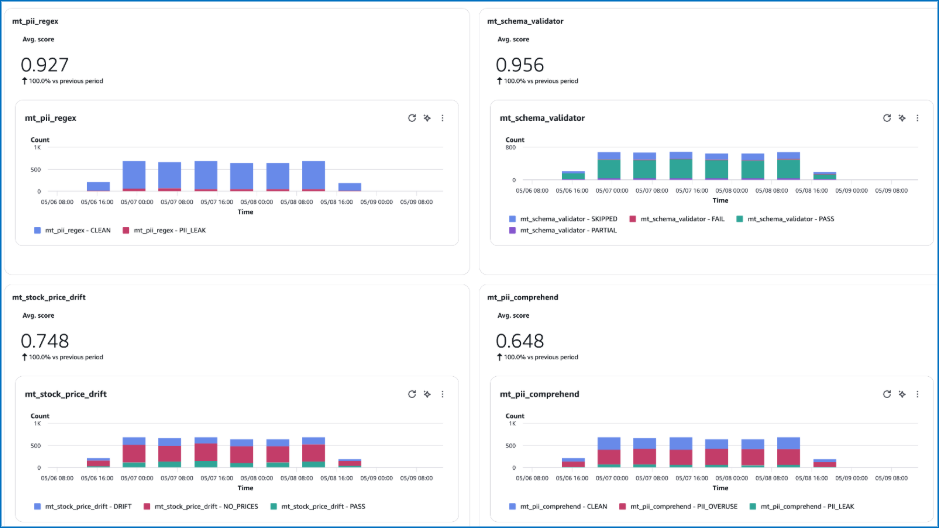
After you ‘ve completed the instructions in the README, you can start monitoring the evaluation metrics in AgentCore Observability console as shown in the following figures. If your AgentCore Evaluation configuration isn’t producing results, or if you’re seeing errors or empty evaluation scores, you can use the AgentCore Evaluation Diagnostic Skill to troubleshoot the issue.
Cleanup
To avoid ongoing charges, remove all resources created during this walkthrough. Delete the evaluator resources first (Lambda functions, IAM roles, and the online evaluation configuration), then run the agent cleanup script to remove the AgentCore Runtime, Memory, ECR repository, and remaining infrastructure. The repository README provides the exact commands for both steps under the Cleanup Evaluators and Complete Resource Cleanup sections.
Best practices for using custom code-based evaluators
When you start evaluating agents in production, you quickly find that some quality issues are subjective while others are rigid and rule-based. Custom code-based evaluators in AgentCore are designed to cover that second category, so you can enforce deterministic checks with your own logic. The workflow for adding these evaluators is the same every time, whether you’re building your first one or scaling out a full evaluation suite.
Decide what to check with code
Start by identifying the deterministic quality dimensions where you want zero ambiguity. These are the places where human judgment or LLM reasoning alone is not sufficient. For example, exact data constraints like IDs or amounts that must match a specific format or value, structural constraints such as required tool-call sequences or workflow steps, and compliance requirements including PII policies or regulatory rules that need provable enforcement.
Keep using built-in or custom LLM-as-a-Judge evaluators for subjective dimensions like helpfulness, tone, coherence, reasoning capabilities, and overall conversational quality. Code-based evaluators are there to cover the hard, binary edges where you want deterministic guarantees.
To map each problem to the right place in the interaction, pick an evaluation level:
| Level | Granularity | Invocation pattern | Typical use |
| TRACE | Single user turn | One Lambda invocation per trace, fanned out in parallel | Per-response schema validation, numerical accuracy checks, per-response PII scan |
| TOOL_CALL | Single tool invocation | One Lambda invocation per matching span, identified by the evaluation target | Validating tool parameters, checking retrieval freshness |
| SESSION | Entire conversation | One Lambda invocation per session, no evaluation target | Workflow-ordering checks, session-wide PII scans, goal-success evaluation |
This mapping keeps you from overcomplicating checks to plug each business rule into the agent’s lifecycle.
Test against real failure modes in on-demand mode
You generally want evidence on real traffic before a new evaluator has any say in deployment decisions or on-call alerts, and that is where on‑demand evaluation fits naturally. Instead of going straight to broad adoption, you exercise the evaluator against a small set of known sessions and confirm that it reliably catches the specific issues you care about, with explanations that clearly highlight the span or tool call responsible for the failure. If the evaluator reaches out to external systems, such as a PII detector or a policy engine, this is also the moment to validate that permissions, timeouts, and other integration details are behaving as expected.
The same mechanism can then become part of your CI/CD pipeline as a deployment gate. After you’re comfortable with how the evaluator performs on a curated test set, you invoke the on‑demand evaluation API from the pipeline and fail the build when it flags critical issues. That gives you a way to enforce hard guarantees, like schema validity, numerical correctness, or PII hygiene, before changes ever reach production, while keeping online evaluation focused on catching drift and long‑tail failures instead of obvious regressions.
Wire it into continuous monitoring
You promote a custom evaluator to online evaluation after you’re confident that it behaves the way you expect, letting it score live traffic rather than just test runs. In practice, that means defining an online evaluation configuration where the evaluator ID sits alongside the built-in evaluators that you already rely on, and the data source is wired to your agent’s CloudWatch log group and OTel service name. The sampling percentage then becomes your main dial for balancing coverage and cost: low-volume agents often make sense at 100 percent so every session is inspected, while high-volume agents typically land in the 10–20 percent range to preserve signal without overwhelming your budget.
After this is in place, results flow into a dedicated results log group and each evaluator score shows up as a CloudWatch metric. Those metrics give you the raw material to build dashboards that surface custom evaluation signals and to wire up CloudWatch Alarms that notify the team whenever a metric dips below the threshold you care about most. At that point, your evaluators are no longer hidden implementation details; they’re visible, trackable signals you can point to when you need to understand whether quality has drifted and whether the system still satisfies the compliance standards for a particular use case.
Conclusion
Code-based evaluators extend the coverage of AgentCore to the quality dimensions that require deterministic logic. In on-demand mode, they act as development checks and CI/CD deployment gates, returning synchronous scores and span-level explanations. In online mode, the same registered evaluator scores live production sessions alongside built-in LLM-as-a-Judge evaluators and emits results as CloudWatch metrics.Paired with built-in evaluators, custom code-based evaluators move agent reliability from “sounds right” to contract-verified paradigm. Because the logic lives in your own Lambda, you can evolve checks as business rules change. A single evaluator registration serves local development, CI/CD gates, and continuous production monitoring, giving your team one consistent quality signal from prototype through scale.
To get started, review the Amazon Bedrock AgentCore Evaluations documentation, identify the structural and compliance properties of your agent that call for deterministic checks, and deploy the sample evaluators from the amazon-bedrock-agentcore-samples repository.



![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




