























Implementing super resolution by deploying SeedVR2 on Amazon SageMaker AI
In this post, we demonstrate how to implement video upscaling using SeedVR2 on SageMaker AI. We cover the solution architecture, walk through the deployment steps, and show performance comparisons that highlight the quality improvements and processing efficiency you can achieve. By the end of this post, you’ll have the practical knowledge needed to implement this super resolution solution.

As display technologies advance to higher resolutions, many organizations face a common challenge: their existing video libraries contain lower-resolution content that appears pixelated or blurry on modern high-definition displays. Traditional video upscaling approaches often struggle with computational limits, inconsistent quality, and scalability issues when processing large video collections. Many existing solutions also lack the techniques needed to restore fine details, sharpen edges, and reduce noise artifacts.
SeedVR2 is an open-source video restoration model developed by ByteDance’s Seed team. Running SeedVR2 on Amazon SageMaker AI addresses these challenges by providing a scalable solution for upscaling and video quality enhancement, also known as super resolution. This approach analyzes visual information frame by frame to restore details and improve video quality, so you don’t need to repurchase content in higher resolutions. With SageMaker managed infrastructure, you can process video collections at scale while maintaining cost efficiency and performance.
In this post, we demonstrate how to implement video upscaling using SeedVR2 on SageMaker AI. We cover the solution architecture, walk through the deployment steps, and show performance comparisons that highlight the quality improvements and processing efficiency you can achieve. By the end of this post, you’ll have the practical knowledge needed to implement this super resolution solution.
Use cases
Video upscaling has many applications across industries. Archives, museums, and broadcasters can restore and digitize historical footage at higher resolutions. This preserves cultural heritage and makes it suitable for modern viewing services. Streaming services can upscale older TV shows and movies to 4K or higher resolutions. This enhances subscriber experiences without requiring complete remasters of vast content libraries.
An emerging and valuable application is upscaling AI-generated videos, which often start at lower resolutions because of the computational intensity of generation models. By applying specialized upscaling algorithms to these synthetic videos, creators can turn computationally efficient rough drafts into polished, high-resolution final products. This avoids the much higher processing requirements of generating directly at high resolutions. The result is a two-stage workflow where you can rapidly prototype ideas at lower resolutions before enhancing them. This approach reduces the time and computing resources needed for AI video production while maintaining visual quality that meets modern display standards.
Solution architecture
The solution uses a three-tier AWS architecture defined with AWS Cloud Development Kit (AWS CDK) for infrastructure as code. The SecurityStack establishes the foundation with Amazon Virtual Private Cloud (Amazon VPC) configuration, AWS Identity and Access Management (AWS IAM) roles with least-privilege access, and AWS Key Management Service (AWS KMS) encryption keys. This stack creates the security perimeter that isolates the video processing workloads within private subnets while maintaining secure access to AWS services through VPC endpoints.
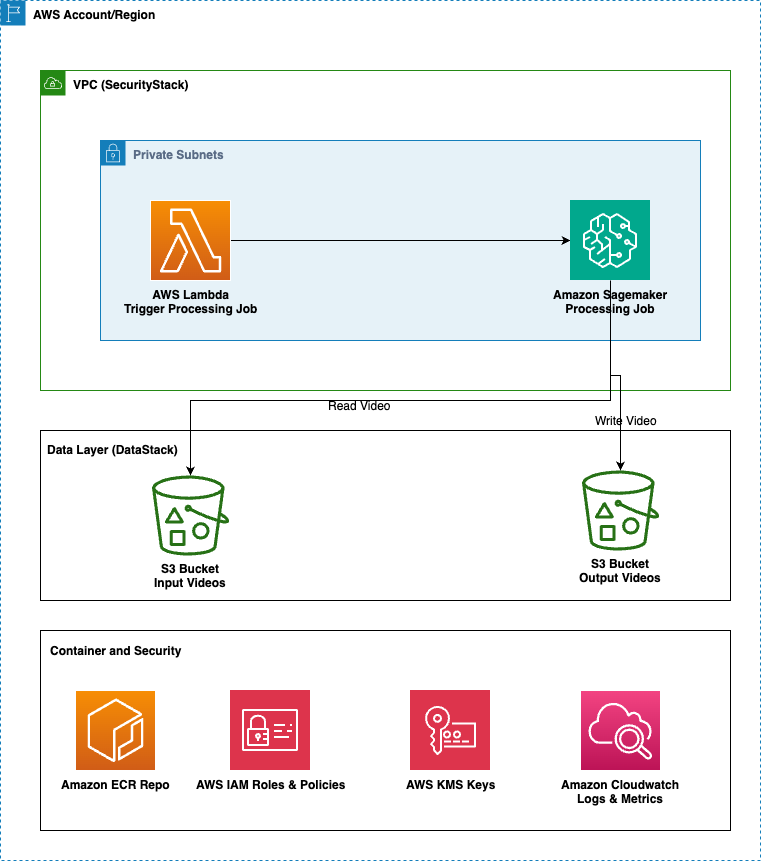
The DataStack implements the storage layer using Amazon Simple Storage Service (Amazon S3) buckets with server-side encryption for both input and output video files. The input bucket stores raw videos, and the output bucket stores the upscaled videos. Both buckets implement versioning with lifecycle policies for object management.
The core processing pipeline runs through an AWS Lambda function that starts an Amazon SageMaker AI processing job. The job uses ml.g5.4xlarge instances that run a custom Docker container. This container packages the SeedVR2 model for ComfyUI and provides high-quality video upscaling with configurable parameters for resolution and batch processing. The solution uses ComfyUI as the inference framework to run SeedVR2, which provides hardware-optimized execution.
The processing workflow begins when you upload videos to the input S3 bucket. The Lambda function then creates a SageMaker processing job that pulls the custom container from Amazon Elastic Container Registry (Amazon ECR), mounts the input and output S3 buckets, and runs the video upscaling algorithm on GPU-enabled infrastructure. The processed videos are saved to the output bucket. Amazon CloudWatch provides logging for monitoring and troubleshooting throughout the pipeline.
SeedVR2 data flow
The following diagram shows how data flows through the solution.
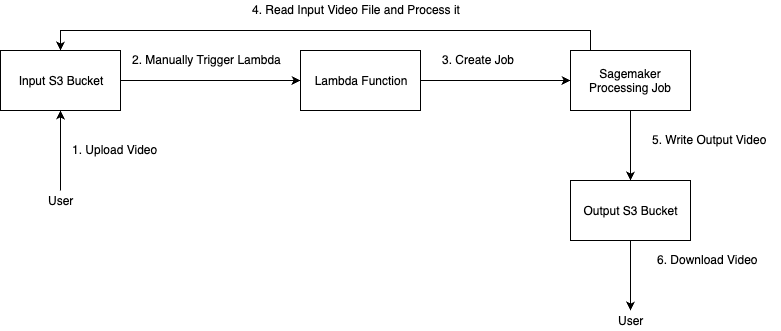
The processing workflow begins when you upload a raw video to the S3 input bucket. You then trigger the Lambda function, which creates a SageMaker processing job with a unique timestamp name. SageMaker starts an ml.g5.4xlarge GPU instance, pulls the SeedVR2 container from Amazon ECR, and mounts the S3 input bucket to read the video files for processing. The SeedVR2 model upscales the videos on the GPU and writes the processed output to the S3 output bucket. The instance then terminates. You can retrieve the upscaled videos from the output bucket.
Deployment steps
Prerequisites
Before you begin, make sure you have the following tools and resources installed and configured:
- Python 3.13+
- The AWS Command Line Interface (AWS CLI)
- Docker
- AWS Cloud Development Kit (AWS CDK) v2
- An AWS account with appropriate permissions
- A service quota request for
ml.g5.4xlargein SageMaker processing jobs
Step 1: Clone the project and set up your environment
Clone the repository and create your environment configuration file:
Edit your .env file with your AWS account details:
Step 2: Install dependencies and bootstrap AWS CDK
Install dependencies using uv, a fast Python package manager, and create a virtual environment:
Bootstrap AWS CDK in your AWS account. This is a one-time setup step. If you encounter permission errors, verify your credentials with aws sts get-caller-identity.
Step 3: Authenticate with Amazon ECR
Authenticate Docker with the AWS Deep Learning Container Amazon ECR registry in us-east-1. This is required to pull the PyTorch base image during the local Docker build, regardless of your deployment Region. If the Docker build fails, check your Amazon ECR authentication and run docker system prune -a to clear cached images.
Step 4: Deploy the infrastructure
Deploy your entire infrastructure with a single command. This creates your VPC, S3 buckets, Lambda function, SageMaker processing job definition, and Amazon ECR repository. Deployment takes 15–20 minutes to complete, depending on your compute and network speed.
Step 5: Test the pipeline
Upload a test video to the input S3 bucket:
Trigger the Lambda function to start the processing job:
Monitor the process through Amazon CloudWatch Logs for Lambda execution, the SageMaker console for processing job status, and the S3 console for your enhanced video output. If the processing job fails, review the CloudWatch logs under /aws/sagemaker/ProcessingJobs. Also verify that the output bucket contains your upscaled video file.
Tuning performance
You can customize your processing parameters in config/config.yaml:
For a full list of models, see the SeedVR2 ComfyUI models on the Hugging Face website.
Cost management
The ml.g5.4xlarge instance costs approximately USD 1.20 per hour (at the time of writing, depending on your Region), and you only pay for instance uptime. S3 storage costs are minimal for most use cases.
Scaling and beyond
This pipeline handles everything from single videos to batch processing automatically. For larger datasets, consider using multiple parallel instances by changing S3DataDistributionType to ShardedByS3Key in the create_processing_job boto3 call. For more information, see the ProcessingS3Input API reference.
How SeedVR2 works
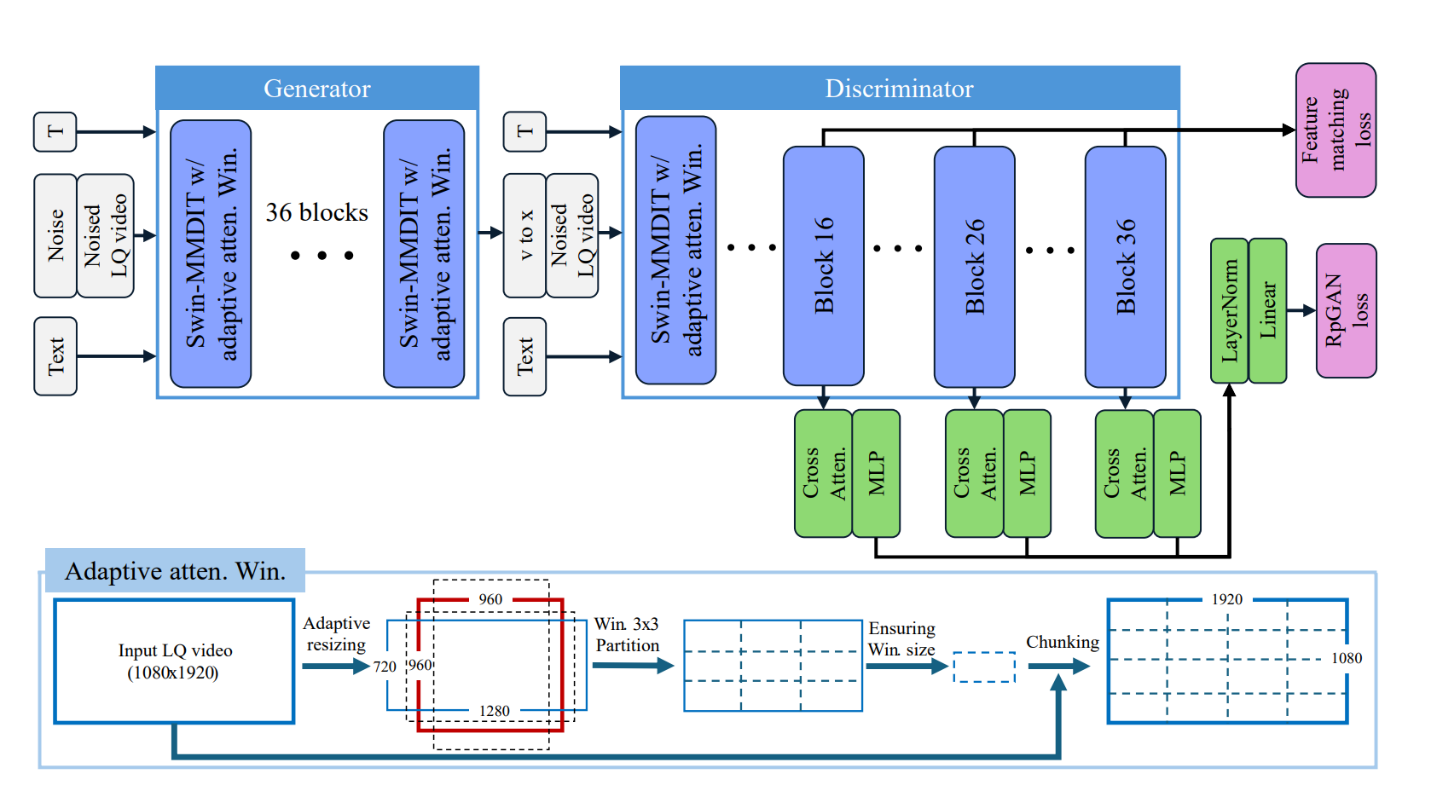
SeedVR2 is a video restoration model that combines diffusion models and generative adversarial networks (GANs) through a process called diffusion adversarial post-training (APT). At its core, the technology uses AI to reconstruct missing details and is built on a 16 billion parameter GAN architecture. The system operates through a two-stage APT process. This process includes progressive distillation that compresses 64 steps down to 1, and real data training that learns from actual high-resolution videos. The architecture uses a Swin Transformer for adaptive window attention and incorporates multiple safeguards, including relativistic pairing GAN (RpGAN) loss, R1/R2 regularization, and feature matching loss. Like regular GANs, RpGANs are not guaranteed to converge to the global minimum. However, the combination of R1 and R2 regularization provides strong stability and mode coverage. The model’s key innovation combines the reliability of diffusion models with the efficiency of GANs. This lets it process entire frames while dynamically adjusting to target resolutions.
Sample results
You can best understand video upscaling results through direct comparison. The following three samples show the progression of quality enhancement, from the original source material through different upscaling methods.
Raw video
The original source footage shown here is a 240p resolution video clip. Note the visible pixelation, especially around edges, and the overall lack of detail and clarity. This is particularly noticeable in the texture of the bird, plant, and peanuts. The low resolution produces a blurry appearance that becomes more apparent on modern high-resolution displays.

Bicubic algorithm upscaling
When you apply traditional bicubic upscaling to achieve 540p resolution, you see minor improvements in overall sharpness compared to the raw footage. However, the limitations of this mathematical interpolation method become evident. The image is larger, but there are still noticeable artifacts like texture smoothing. The algorithm struggles to recreate authentic detail. Instead, it produces somewhat artificial-looking results that lack the natural characteristics of high-resolution footage.

SeedVR2 upscaling
The SeedVR2 upscaled result shows improvement in visual quality while increasing the resolution to 540p. The AI-powered enhancement reconstructs fine details while maintaining natural-looking textures. Notice the improved clarity in the textures of the bird, plant, peanuts, and other elements. The processed footage achieves a more film-like quality with better color consistency and edge definition.

Clean up
To avoid incurring additional costs, remove the resources you created by following these steps.
Step 1: Empty the S3 buckets
Delete all objects from the input and output buckets:
Step 2: Destroy the AWS CDK stacks
Tear down all deployed infrastructure:
Step 3: Clean local files
Remove CDK build artifacts and Python cache files from your local environment:
Step 4: Verify cleanup
Confirm that all resources have been removed:
Conclusion
In this post, we showed how to implement SeedVR2 on Amazon SageMaker AI for scalable video enhancement. By combining SeedVR2’s AI-driven upscaling with AWS cloud infrastructure, this solution provides a cost-effective approach to video quality enhancement that you can deploy at scale. The on-demand architecture supports efficient resource use, and the automated workflow reduces manual intervention. This makes high-quality video enhancement accessible to organizations of all sizes.
As video content continues to grow and display technologies advance, the need for efficient upscaling solutions also grows. This implementation shows how cloud architecture can improve access to advanced video processing. With it, you can meet rising quality expectations without large infrastructure investments.
This solution gives you a framework that balances performance, cost, and operational efficiency. The detailed deployment steps help you start using these capabilities quickly while maintaining security and scalability best practices.
To get started, explore the sample-sagemaker-video-upscaler repository on the GitHub website and deploy the solution for your own use case. You can also contribute to the project by submitting pull requests or opening issues for enhancements and bug fixes.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




