
























Fine-tune Amazon Nova models for accurate email data extraction
In this post, you'll learn how fine-tuning Amazon Nova models using Amazon SageMaker AI addresses these specific issues by teaching the models to recognize your exact data patterns, distinguish between similar fields, and process information more efficiently—achieving up to 94.77% extraction accuracy while reducing costs 50%.

The authors would also like to thank Karan Bhandarkar, Sue Cha, Yash Shah and Nieves Garcia for their contributions in making this initiative possible.
If you process millions of email messages daily, fine-tuning Amazon Nova models can help you automate accurate data extraction while reducing costs and hallucinations. Parcel Perform, a leading AI Delivery Experience Platform for ecommerce businesses worldwide, faced this exact challenge when extracting structured information from diverse email formats, ranging from simple notifications to complex HTML documents with extensive JavaScript elements.
Common challenges include model hallucinations, confusion between similar data types (such as order numbers and tracking numbers), and prohibitively high token costs when processing HTML-formatted email.
In this post, you’ll learn how fine-tuning Amazon Nova models using Amazon SageMaker AI addresses these specific issues by teaching the models to recognize your exact data patterns, distinguish between similar fields, and process information more efficiently—achieving up to 94.77% extraction accuracy while reducing costs 50%.
The collaboration
Parcel Perform worked with the AWS Generative AI Innovation Center (GenAIIC), which provides business and technical consultancy throughout the customer journey. Working backward from Parcel Perform’s problem statement, the team scoped a project to optimize Nova models through various customization techniques and parameter optimization.
This collaboration allowed concurrent improvement of multiple metrics: accuracy, latency, and cost. Le Vy, AI Team Lead at Parcel Perform, reported that the fine-tuned Nova Micro models achieved up to 94.77% extraction accuracy on the testing dataset, an improvement of up to 16.6 percentage points over the baseline. The fine-tuned Nova Micro reduced inference latency by more than 30 percent and halved costs compared with Parcel Perform’s previous model, while matching or exceeding the fine-tuned Nova Lite model at lower cost. With these results, Parcel Perform moved the solution into production to improve its e-commerce logistics operations.
Solution overview
You can use Amazon SageMaker AI custom model fine-tuning to adapt Amazon Nova Lite and Amazon Nova Micro models for specialized entity extraction from ecommerce email. This solution uses supervised fine-tuning (SFT) with Parameter-Efficient Fine-Tuning (PEFT) through Low-Rank Adaptation (LoRA). With PEFT, you can customize models effectively with limited training data while maintaining computational efficiency.
You can also use PEFT to deploy the model into Amazon Bedrock and invoke it with on-demand inference priced per token. Amazon Bedrock offers flexible deployment options: with PEFT, you can deploy using on-demand inference, while full-rank SFT supports deployment through either Provisioned Throughput on Amazon Bedrock or a SageMaker AI endpoint.
The custom model fine-tuning uses Amazon Nova recipes, which are YAML configuration files that provide details to Amazon SageMaker AI on how to run your model customization job, including the base model name, training hyperparameters, optimization settings, and additional options. The following diagram illustrates the solution architecture.
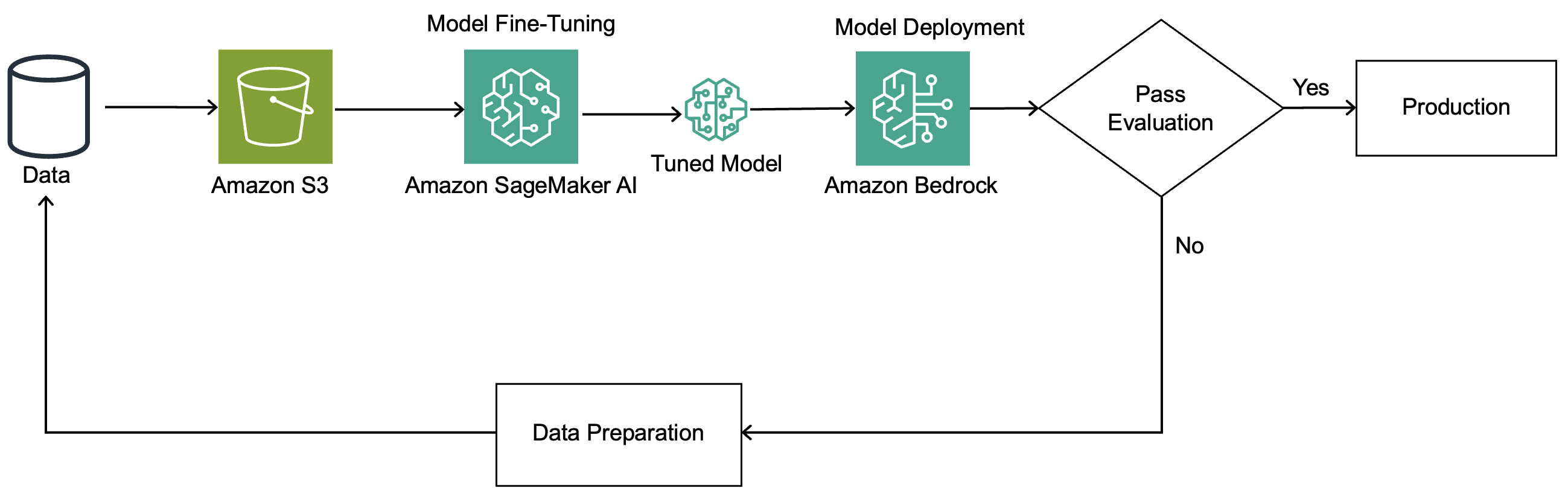
Here’s how the workflow works:
- Prepare training data in the Amazon Bedrock conversation format with email content as input and extracted entities as output.
- Upload training data to Amazon Simple Storage Service (Amazon S3).
- Create a fine-tuning job in SageMaker AI using Low-Rank Adaptation (LoRA) configuration.
- Deploy the fine-tuned model using Amazon Bedrock with on-demand inference.
- Run inference to extract entities from new email.
Prerequisites
You will need the following to fine-tune and deploy Nova models:
- AWS account with appropriate permissions: Required to access AWS services and create resources.
- Access to Amazon Bedrock and Amazon Nova models: Must be available in your chosen AWS Region.
- IAM service role: An AWS Identity and Access Management (IAM) role with permissions for Amazon Bedrock model customization.
- S3 bucket: For storing training data and output artifacts.
- Training data in JSONL format: Follow the data format and preparation guidance.
- Sufficient Service Quotas: Establish adequate quota for your chosen instance type and size in SageMaker AI Training.
For instructions on creating the service role, see Create a service role for model customization.
Prepare the training data
Your training data must follow the Amazon Bedrock conversation schema format. Each sample contains the email content as user input and the extracted entities as the assistant response.
Here’s a simplified example of the required format:
In our experiment, we prepared two training datasets: a smaller set with 1,300 samples and a larger set with 4,900 samples. This allowed us to evaluate how training data size impacts model performance.
You can use Amazon SageMaker Studio as your development environment to run Jupyter Notebook for the data preparation step.
Upload training data to an S3 bucket
SageMaker AI Training runs jobs in separate environments from your code and data development environment. With SageMaker AI Training, you can efficiently use one or multiple powerful GPU-powered instances that automatically stop when training finishes. Because the instances are separate from your data preparation environment, you will need to upload the data to a centralized location: Amazon S3.
The following code illustrates uploading data from SageMaker Studio to an S3 bucket:
Fine-tune the Amazon Nova model
With your training data prepared, you can create a fine-tuning job using the Amazon SageMaker AI API through the SageMaker SDK. Follow the examples in the Amazon Nova Customization Hub. This provisions a training job with Amazon SageMaker AI Training that runs on a container on one or multiple separate instances with the type and size you choose.
The following table summarizes the key fine-tuning parameters in our experiment:
| Parameters | Description |
| model_type | “amazon.nova-lite-v1:0:300k” or “amazon.nova-micro-v1:0:128k” |
| model_name_or_path | “nova-lite/prod” or “nova-micro/prod” |
| replicas | 1 for g5/g6 4 for p5 |
| max_length | 8192 for g5/g6 32768 for p5 |
| global_batch_size | 64 |
| max_epochs | 2 |
| peft_scheme | lora |
| loraplus_lr_ratio | 8.0 |
| alpha | 32 |
We selected Nova Lite and Nova Micro because of their lower cost and competitive performance compared with Amazon Nova Pro and other models.
Deploy and run inference
When your fine-tuning job completes successfully, you can create a custom model in Amazon Bedrock to import the PEFT-tuned Nova model trained by Amazon SageMaker AI. Follow Create a custom model for detailed steps. Then you can run inference using the custom model as shown in the following example:
The function returns extracted fields similar to the following:
You also have the option of iteratively training the model with a different method. For example, you can use the checkpoint from SFT-PEFT tuning as a base for downstream Direct Preference Optimization (DPO) training. See the documentation on iterative training.
Evaluation results
Fine-tuned models improved accuracy by 5.6–16.6 percentage points over baselines, with Nova Micro achieving the highest overall accuracy of 94.77 percent despite being the smaller model. Fine-tuning also reduced inference latency by approximately 32 percent and cut costs by approximately 50 percent through PEFT tuning on lighter models compared to existing models with pay-per-use pricing. These combined gains in accuracy, speed, and cost enabled Parcel Perform to deploy the tuned Amazon Nova model into production.
Accuracy comparison
Parcel Perform evaluated the fine-tuned models against baseline models using Parcel Perform’s weighted accuracy metric, which combines extraction accuracy across the data fields. We tested on two representative datasets with 100 samples and 200 samples, respectively.
Key findings:
Fine-tuning delivered accuracy gains across all models, with improvements ranging from 5.6 to 16.6 percentage points over their baseline counterparts. Nova Micro showed the largest jump, climbing from 76.63 percent to 93.27 percent after fine-tuning. Scaling the training data from 1,300 to 4,900 samples further boosted performance by up to 3.3 percent, showing that modest increases in training volume continue to yield meaningful returns. Despite being the smaller model, Nova Micro achieved the highest overall accuracy of 94.77 percent on the 200-sample test set. A well-tuned compact model can outperform larger alternatives on domain-specific tasks.
Latency improvements
Fine-tuning also reduced inference latency significantly: 31 percent for Nova Lite and 32 percent for Nova Micro because of Nova Micro’s smaller model size and fewer parameters compared with Parcel Perform’s previous model. This represents about 7.7 seconds per inference, making it faster to process large volumes of email daily.
Impact
Processing time decreased significantly compared with Parcel Perform’s previous model. Costs reduced by approximately 50 percent because PEFT lets lighter models perform better at specific tasks while supporting deployment with pay-per-use pricing. The improved accuracy, paired with reduced cost and latency, lets Parcel Perform use the fine-tuned Amazon Nova model in production.
Conclusion
In this post, we demonstrated how you can fine-tune Amazon Nova models using Amazon SageMaker AI for accurate entity extraction from e-commerce email. Our collaboration with Parcel Perform showed that Parameter-Efficient Fine-Tuning using LoRA can achieve significant accuracy improvements while reducing inference latency by more than 30 percent.
Key takeaways from this engagement:
Fine-tuning proved effective at reducing hallucinations. The models correctly distinguished between order numbers and tracking numbers without fabricating data that doesn’t exist in the source material. You don’t need massive datasets to see real results: meaningful accuracy gains were achieved with as few as 1,300 training samples across 25 entities, making fine-tuning a practical option even for teams with limited labeled data. In a counterintuitive finding, the smaller Nova Micro model outperformed the larger Nova Lite after fine-tuning, showing that task-specific optimization can more than compensate for differences in base model size. This has cost implications: pairing a smaller, faster model like Nova Micro with reduced inference latency creates a cost-effective solution for processing large volumes of email at scale. The ability to deploy PEFT-tuned models directly into Amazon Bedrock with on-demand, token-based pricing means you can run a fully customized model on a pay-per-use basis, removing the need to provision and maintain dedicated LLM-hosting infrastructure.
Get started
To implement this solution, start by preparing your training data in the preceding format. Begin with a dataset of at least 1,300 samples as shown in this post for meaningful results. To get optimal results, make sure your training data represents the variety of email formats that you will encounter in production.
If you face similar entity extraction challenges, you can use SageMaker AI model customization to build accurate, production-ready solutions. This approach shows how you can adapt fast and cost-effective models like Nova Micro and Nova Lite for production use cases that deliver accuracy, speed, and cost-effectiveness.
Ready to try it yourself? Explore these resources:
- Customize models in Amazon Bedrock: Learn more about Amazon Bedrock model customization.
- Amazon Nova Forge product details page: Discover custom model development using Nova.
- Generative AI Innovation Center: Work with AWS GenAIIC on similar use cases.
AWS GenAIIC is a program launched by AWS in 2023 to help organizations turn generative AI potential into business value. The center brings together AWS science and strategy experts who work with customers across the generative AI journey, helping prioritize use cases, build strategic roadmaps, and move AI solutions from concept into production. Since its inception, the innovation center has collaborated with more than 1,000 customers across industries, including Formula 1, Nasdaq, Ryanair, and S&P Global, with more than 65 percent of projects in recent years reaching production deployment. AWS has since doubled its investment in the program to expand the support available to customers building generative AI solutions.





![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




