














![[PRO Tips] Use the BCG matrix to help you analyze the current situation, product positioning, and formulate strategies](https://i.scdn.co/image/ab6765630000ba8a165b48c48c4321b36a1df7b9?#)
![[Business Talk] BYD's Hiring Standards: A Reflection of China's Competitive Job Market](https://i.scdn.co/image/ab6765630000ba8a1a1e0af3aefae3a685793e7c?#)
![[PRO Tips] What is ESG? How is it different from CSR and SDGs? 3 keywords that companies and investors should know](https://i.scdn.co/image/ab6765630000ba8a76dbe129993a62e85226c2b4?#)
![[Business Talk] Elon Musk](https://i.scdn.co/image/ab6765630000ba8ac91eb094519def31d2b67898?#)









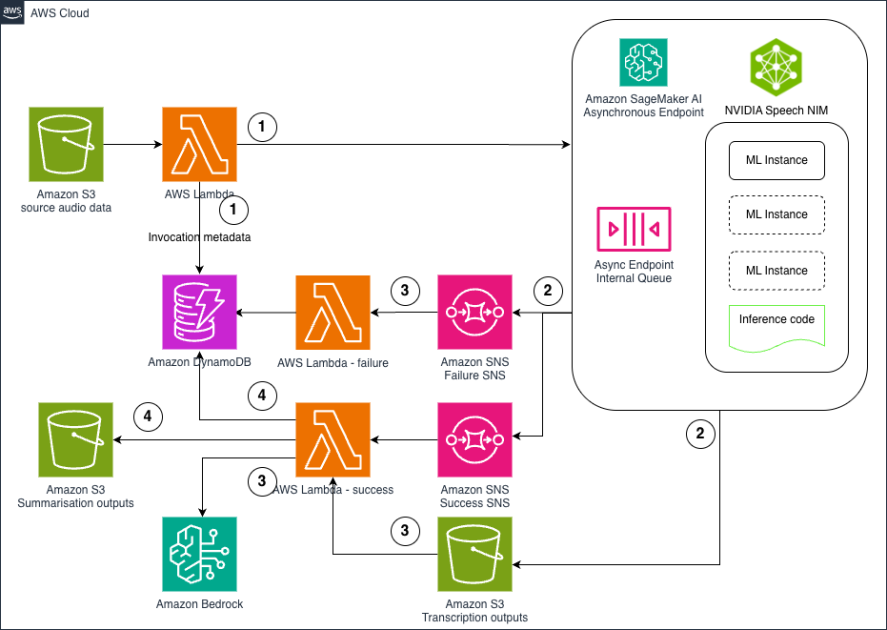
Qwen3 family of reasoning models now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
Today, we are excited to announce that Qwen3, the latest generation of large language models (LLMs) in the Qwen family, is available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Qwen3 models—available in 0.6B, 4B, 8B, and 32B parameter sizes—to build, experiment, and responsibly scale your generative AI applications on AWS. In this post, we demonstrate how to get started with Qwen3 on Amazon Bedrock Marketplace and SageMaker JumpStart.

Today, we are excited to announce that Qwen3, the latest generation of large language models (LLMs) in the Qwen family, is available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Qwen3 models—available in 0.6B, 4B, 8B, and 32B parameter sizes—to build, experiment, and responsibly scale your generative AI applications on AWS.
In this post, we demonstrate how to get started with Qwen3 on Amazon Bedrock Marketplace and SageMaker JumpStart. You can follow similar steps to deploy the distilled versions of the models as well.
Solution overview
Qwen3 is the latest generation of LLMs in the Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- Unique support of seamless switching between thinking mode and non-thinking mode within a single model, providing optimal performance across various scenarios.
- Significantly enhanced in its reasoning capabilities, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- Good human preference alignment, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- Expertise in agent capabilities, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open source models in complex agent-based tasks.
- Support for over 100 languages and dialects with strong capabilities for multilingual instruction following and translation.
Prerequisites
To deploy Qwen3 models, make sure you have access to the recommended instance types based on the model size. You can find these instance recommendations on Amazon Bedrock Marketplace or the SageMaker JumpStart console. To verify you have the necessary resources, complete the following steps:
- Open the Service Quotas console.
- Under AWS Services, select Amazon SageMaker.
- Check that you have sufficient quota for the required instance type for endpoint deployment.
- Make sure at least one of these instance types is available in your target AWS Region.
If needed, request a quota increase and contact your AWS account team for support.
Deploy Qwen3 in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace gives you access to over 100 popular, emerging, and specialized foundation models (FMs) through Amazon Bedrock. To access Qwen3 in Amazon Bedrock, complete the following steps:
- On the Amazon Bedrock console, in the navigation pane under Foundation models, choose Model catalog.
- Filter for Hugging Face as a provider and choose a Qwen3 model. For this example, we use the Qwen3-32B model.

The model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.
The page also includes deployment options and licensing information to help you get started with Qwen3-32B in your applications.
- To begin using Qwen3-32B, choose Deploy.

You will be prompted to configure the deployment details for Qwen3-32B. The model ID will be pre-populated.
- For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters).
- For Number of instances, enter a number of instances (between 1–100).
- For Instance type, choose your instance type. For optimal performance with Qwen3-32B, a GPU-based instance type like ml.g5-12xlarge is recommended.
- To deploy the model, choose Deploy.

When the deployment is complete, you can test Qwen3-32B’s capabilities directly in the Amazon Bedrock playground.
- Choose Open in playground to access an interactive interface where you can experiment with different prompts and adjust model parameters like temperature and maximum length.
This is an excellent way to explore the model’s reasoning and text generation abilities before integrating it into your applications. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results.You can quickly test the model in the playground through the UI. However, to invoke the deployed model programmatically with any Amazon Bedrock APIs, you must have the endpoint Amazon Resource Name (ARN).
Enable reasoning and non-reasoning responses with Converse API
The following code shows how to turn reasoning on and off with Qwen3 models using the Converse API, depending on your use case. By default, reasoning is left on for Qwen3 models, but you can streamline interactions by using the /no_think command within your prompt. When you add this to the end of your query, reasoning is turned off and the models will provide just the direct answer. This is particularly useful when you need quick information without explanations, are familiar with the topic, or want to maintain a faster conversational flow. At the time of writing, the Converse API doesn’t support tool use for Qwen3 models. Refer to the Invoke_Model API example later in this post to learn how to use reasoning and tools in the same completion.
The following is a response using the Converse API, without default thinking:
The following is an example with default thinking on; the reasoningContent field for the Converse API:
Perform reasoning and function calls in the same completion using the Invoke_Model API
With Qwen3, you can stream an explicit trace and the exact JSON tool call in the same completion. Up until now, reasoning models have forced the choice to either show the chain of thought or call tools deterministically. The following code shows an example:
Response:
Deploy Qwen3-32B with SageMaker JumpStart
SageMaker JumpStart is a machine learning (ML) hub with FMs, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. With SageMaker JumpStart, you can customize pre-trained models to your use case, with your data, and deploy them into production using either the UI or SDK.Deploying the Qwen3-32B model through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Let’s explore both methods to help you choose the approach that best suits your needs.
Deploy Qwen3-32B through SageMaker JumpStart UI
Complete the following steps to deploy Qwen3-32B using SageMaker JumpStart:
- On the SageMaker console, choose Studio in the navigation pane.
- First-time users will be prompted to create a domain.
- On the SageMaker Studio console, choose JumpStart in the navigation pane.
The model browser displays available models, with details like the provider name and model capabilities.

- Search for Qwen3 to view the Qwen3-32B model card.
Each model card shows key information, including:
- Model name
- Provider name
- Task category (for example, Text Generation)
- Bedrock Ready badge (if applicable), indicating that this model can be registered with Amazon Bedrock, so you can use Amazon Bedrock APIs to invoke the model

- Choose the model card to view the model details page.
The model details page includes the following information:
- The model name and provider information
- A Deploy button to deploy the model
- About and Notebooks tabs with detailed information
The About tab includes important details, such as:
- Model description
- License information
- Technical specifications
- Usage guidelines

Before you deploy the model, it’s recommended to review the model details and license terms to confirm compatibility with your use case.
- Choose Deploy to proceed with deployment.
- For Endpoint name, use the automatically generated name or create a custom one.
- For Instance type¸ choose an instance type (default: ml.g6-12xlarge).
- For Initial instance count, enter the number of instances (default: 1).
Selecting appropriate instance types and counts is crucial for cost and performance optimization. Monitor your deployment to adjust these settings as needed. Under Inference type, Real-time inference is selected by default. This is optimized for sustained traffic and low latency.
- Review all configurations for accuracy. For this model, we strongly recommend adhering to SageMaker JumpStart default settings and making sure that network isolation remains in place.
- Choose Deploy to deploy the model.

The deployment process can take several minutes to complete.
When deployment is complete, your endpoint status will change to InService. At this point, the model is ready to accept inference requests through the endpoint. You can monitor the deployment progress on the SageMaker console Endpoints page, which will display relevant metrics and status information. When the deployment is complete, you can invoke the model using a SageMaker runtime client and integrate it with your applications.
Deploy Qwen3-32B using the SageMaker Python SDK
To get started with Qwen3-32B using the SageMaker Python SDK, you must install the SageMaker Python SDK and make sure you have the necessary AWS permissions and environment set up. The following is a step-by-step code example that demonstrates how to deploy and use Qwen3-32B for inference programmatically:
You can run additional requests against the predictor:
The following are some error handling and best practices to enhance deployment code:
Clean up
To avoid unwanted charges, complete the steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, under Foundation models in the navigation pane, choose Marketplace deployments.
- In the Managed deployments section, locate the endpoint you want to delete.
- Select the endpoint, and on the Actions menu, choose Delete.
- Verify the endpoint details to make sure you’re deleting the correct deployment:
- Endpoint name
- Model name
- Endpoint status
- Choose Delete to delete the endpoint.
- In the deletion confirmation dialog, review the warning message, enter
confirm, and choose Delete to permanently remove the endpoint.
Delete the SageMaker JumpStart predictor
The SageMaker JumpStart model you deployed will incur costs if you leave it running. Use the following code to delete the endpoint if you want to stop incurring charges. For more details, see Delete Endpoints and Resources.
Conclusion
In this post, we explored how you can access and deploy the Qwen3 models using Amazon Bedrock Marketplace and SageMaker JumpStart. With support for both the full parameter models and its distilled versions, you can choose the optimal model size for your specific use case. Visit SageMaker JumpStart in Amazon SageMaker Studio or Amazon Bedrock Marketplace to get started. For more information, refer to Use Amazon Bedrock tooling with Amazon SageMaker JumpStart models, SageMaker JumpStart pretrained models, Amazon SageMaker JumpStart Foundation Models, Amazon Bedrock Marketplace, and Getting started with Amazon SageMaker JumpStart.
The Qwen3 family of LLMs offers exceptional versatility and performance, making it a valuable addition to the AWS foundation model offerings. Whether you’re building applications for content generation, analysis, or complex reasoning tasks, Qwen3’s advanced architecture and extensive context window make it a powerful choice for your generative AI needs.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
 Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
 Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS.
Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS.
 Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football.
Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football.
 John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
 Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.








