Beyond the basics: A comprehensive foundation model selection framework for generative AI
As the model landscape expands, organizations face complex scenarios when selecting the right foundation model for their applications. In this blog post we present a systematic evaluation methodology for Amazon Bedrock users, combining theoretical frameworks with practical implementation strategies that empower data scientists and machine learning (ML) engineers to make optimal model selections.

Most organizations evaluating foundation models limit their analysis to three primary dimensions: accuracy, latency, and cost. While these metrics provide a useful starting point, they represent an oversimplification of the complex interplay of factors that determine real-world model performance.
Foundation models have revolutionized how enterprises develop generative AI applications, offering unprecedented capabilities in understanding and generating human-like content. However, as the model landscape expands, organizations face complex scenarios when selecting the right foundation model for their applications. In this blog post we present a systematic evaluation methodology for Amazon Bedrock users, combining theoretical frameworks with practical implementation strategies that empower data scientists and machine learning (ML) engineers to make optimal model selections.
The challenge of foundation model selection
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies such as AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming soon), Stability AI, TwelveLabs (coming soon), Writer, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. The service’s API-driven approach allows seamless model interchangeability, but this flexibility introduces a critical challenge: which model will deliver optimal performance for a specific application while meeting operational constraints?
Our research with enterprise customers reveals that many early generative AI projects select models based on either limited manual testing or reputation, rather than systematic evaluation against business requirements. This approach frequently results in:
- Over-provisioning computational resources to accommodate larger models than required
- Sub-optimal performance because of misalignment between model strengths and use case requirements
- Unnecessarily high operational costs because of inefficient token utilization
- Production performance issues discovered too late in the development lifecycle
In this post, we outline a comprehensive evaluation methodology optimized for Amazon Bedrock implementations using Amazon Bedrock Evaluations while providing forward-compatible patterns as the foundation model landscape evolves. To read more about on how to evaluate large language model (LLM) performance, see LLM-as-a-judge on Amazon Bedrock Model Evaluation.
A multidimensional evaluation framework—Foundation model capability matrix
Foundation models vary significantly across multiple dimensions, with performance characteristics that interact in complex ways. Our capability matrix provides a structured view of critical dimensions to consider when evaluating models in Amazon Bedrock. Below are four core dimensions (in no specific order) – Task performance, Architectural characteristics, Operational considerations, and Responsible AI attributes.
Task performance
Evaluating the models based on the task performance is crucial for achieving direct impact on business outcomes, ROI, user adoption and trust, and competitive advantage.
- Task-specific accuracy: Evaluate models using benchmarks relevant to your use case (MMLU, HELM, or domain-specific benchmarks).
- Few-shot learning capabilities: Strong few-shot performers require minimal examples to adapt to new tasks, leading to cost efficiency, faster time-to-market, resource optimization, and operational benefits.
- Instruction following fidelity: For the applications that require precise adherence to commands and constraints, it is critical to evaluate model’s instruction following fidelity.
- Output consistency: Reliability and reproducibility across multiple runs with identical prompts.
- Domain-specific knowledge: Model performance varies dramatically across specialized fields based on training data. Evaluate the models base on your domain-specific use-case scenarios.
- Reasoning capabilities: Evaluate the model’s ability to perform logical inference, causal reasoning, and multi-step problem-solving. This can include reasoning such as deductive and inductive, mathematical, chain-of-thought, and so on.
Architectural characteristics
Architectural characteristics for evaluating the models are important as they directly impact the model’s performance, efficiency, and suitability for specific tasks.
- Parameter count (model size): Larger models typically offer more capabilities but require greater computational resources and may have higher inference costs and latency.
- Training data composition: Models trained on diverse, high-quality datasets tend to have better generalization abilities across different domains.
- Model architecture: Decoder-only models excel at text generation, encoder-decoder architectures handle translation and summarization more effectively, while mixture of experts (MoE) architectures can be a powerful tool for improving the performance of both decoder-only and encoder-decoder models. Some specialized architectures focus on enhancing reasoning capabilities through techniques like chain-of-thought prompting or recursive reasoning.
- Tokenization methodology: The way models process text affects performance on domain-specific tasks, particularly with specialized vocabulary.
- Context window capabilities: Larger context windows enable processing more information at once, critical for document analysis and extended conversations.
- Modality: Modality refers to type of data a model can process and generate, such as text, image, audio, or video. Consider the modality of the models depending on the use case, and choose the model optimized for that specific modality.
Operational considerations
Below listed operational considerations are critical for model selection as they directly impact the real-world feasibility, cost-effectiveness, and sustainability of AI deployments.
- Throughput and latency profiles: Response speed impacts user experience and throughput determines scalability.
- Cost structures: Input/output token pricing significantly affects economics at scale.
- Scalability characteristics: Ability to handle concurrent requests and maintain performance during traffic spikes.
- Customization options: Fine-tuning capabilities and adaptation methods for tailoring to specific use cases or domains.
- Ease of integration: Ease of integration into existing systems and workflow is an important consideration.
- Security: When dealing with sensitive data, model security—including data encryption, access control, and vulnerability management—is a crucial consideration.
Responsible AI attributes
As AI becomes increasingly embedded in business operations and daily lives, evaluating models on responsible AI attributes isn’t just a technical consideration—it’s a business imperative.
- Hallucination propensity: Models vary in their tendency to generate plausible but incorrect information.
- Bias measurements: Performance across different demographic groups affects fairness and equity.
- Safety guardrail effectiveness: Resistance to generating harmful or inappropriate content.
- Explainability and privacy: Transparency features and handling of sensitive information.
- Legal Implications: Legal considerations should include data privacy, non-discrimination, intellectual property, and product liability.
Agentic AI considerations for model selection
The growing popularity of agentic AI applications introduces evaluation dimensions beyond traditional metrics. When assessing models for use in autonomous agents, consider these critical capabilities:
Agent-specific evaluation dimensions
- Planning and reasoning capabilities: Evaluate chain-of-thought consistency across complex multi-step tasks and self-correction mechanisms that allow agents to identify and fix their own reasoning errors.
- Tool and API integration: Test function calling capabilities, parameter handling precision, and structured output consistency (JSON/XML) for seamless tool use.
- Agent-to-agent communication: Assess protocol adherence to frameworks like A2A and efficient contextual memory management across extended multi-agent interactions.
Multi-agent collaboration testing for applications using multiple specialized agents
- Role adherence: Measure how well models maintain distinct agent personas and responsibilities without role confusion.
- Information sharing efficiency: Test how effectively information flows between agent instances without critical detail loss.
- Collaborative intelligence: Verify whether multiple agents working together produce better outcomes than single-model approaches.
- Error propagation resistance: Assess how robustly multi-agent systems contain and correct errors rather than amplifying them.
A four-phase evaluation methodology
Our recommended methodology progressively narrows model selection through increasingly sophisticated assessment techniques:
Phase 1: Requirements engineering
Begin with a precise specification of your application’s requirements:
- Functional requirements: Define primary tasks, domain knowledge needs, language support, output formats, and reasoning complexity.
- Non-functional requirements: Specify latency thresholds, throughput requirements, budget constraints, context window needs, and availability expectations.
- Responsible AI requirements: Establish hallucination tolerance, bias mitigation needs, safety requirements, explainability level, and privacy constraints.
- Agent-specific requirements: For agentic applications, define tool-use capabilities, protocol adherence standards, and collaboration requirements.
Assign weights to each requirement based on business priorities to create your evaluation scorecard foundation.
Phase 2: Candidate model selection
Use the Amazon Bedrock model information API to filter models based on hard requirements. This typically reduces candidates from dozens to 3–7 models that are worth detailed evaluation.
Filter options include but aren’t limited to the following:
- Filter by modality support, context length, and language capabilities
- Exclude models that don’t meet minimum performance thresholds
- Calculate theoretical costs at projected scale so that you can exclude options that exceed the available budget
- Filter for customization requirements such as fine-tuning capabilities
- For agentic applications, filter for function calling and multi-agent protocol support
Although the Amazon Bedrock model information API might not provide the filters you need for candidate selection, you can use the Amazon Bedrock model catalog (shown in the following figure) to obtain additional information about these models.
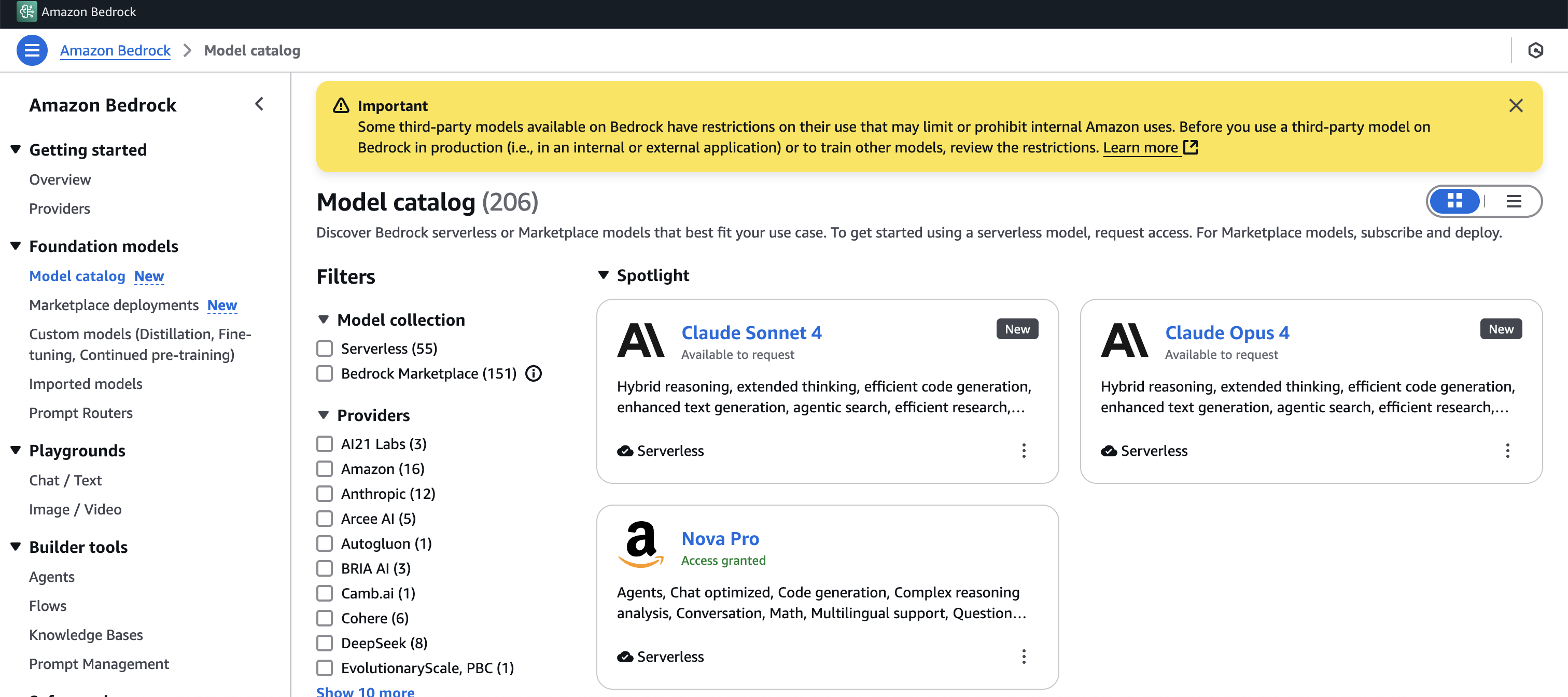
Phase 3: Systematic performance evaluation
Implement structured evaluation using Amazon Bedrock Evaluations:
- Prepare evaluation datasets: Create representative task examples, challenging edge cases, domain-specific content, and adversarial examples.
- Design evaluation prompts: Standardize instruction format, maintain consistent examples, and mirror production usage patterns.
- Configure metrics: Select appropriate metrics for subjective tasks (human evaluation and reference-free quality), objective tasks (precision, recall, and F1 score), and reasoning tasks (logical consistency and step validity).
- For agentic applications: Add protocol conformance testing, multi-step planning assessment, and tool-use evaluation.
- Execute evaluation jobs: Maintain consistent parameters across models and collect comprehensive performance data.
- Measure operational performance: Capture throughput, latency distributions, error rates, and actual token consumption costs.
Phase 4: Decision analysis
Transform evaluation data into actionable insights:
- Normalize metrics: Scale all metrics to comparable units using min-max normalization.
- Apply weighted scoring: Calculate composite scores based on your prioritized requirements.
- Perform sensitivity analysis: Test how robust your conclusions are against weight variations.
- Visualize performance: Create radar charts, efficiency frontiers, and tradeoff curves for clear comparison.
- Document findings: Detail each model’s strengths, limitations, and optimal use cases.
Advanced evaluation techniques
Beyond standard procedures, consider the following approaches for evaluating models.
A/B testing with production traffic
Implement comparative testing using Amazon Bedrock’s routing capabilities to gather real-world performance data from actual users.
Adversarial testing
Test model vulnerabilities through prompt injection attempts, challenging syntax, edge case handling, and domain-specific factual challenges.
Multi-model ensemble evaluation
Assess combinations such as sequential pipelines, voting ensembles, and cost-efficient routing based on task complexity.
Continuous evaluation architecture
Design systems to monitor production performance with:
- Stratified sampling of production traffic across task types and domains
- Regular evaluations and trigger-based reassessments when new models emerge
- Performance thresholds and alerts for quality degradation
- User feedback collection and failure case repositories for continuous improvement
Industry-specific considerations
Different sectors have unique requirements that influence model selection:
- Financial services: Regulatory compliance, numerical precision, and personally identifiable information (PII) handling capabilities
- Healthcare: Medical terminology understanding, HIPAA adherence, and clinical reasoning
- Manufacturing: Technical specification comprehension, procedural knowledge, and spatial reasoning
- Agentic systems: Autonomous reasoning, tool integration, and protocol conformance
Best practices for model selection
Through this comprehensive approach to model evaluation and selection, organizations can make informed decisions that balance performance, cost, and operational requirements while maintaining alignment with business objectives. The methodology makes sure that model selection isn’t a one-time exercise but an evolving process that adapts to changing needs and technological capabilities.
- Assess your situation thoroughly: Understand your specific use case requirements and available resources
- Select meaningful metrics: Focus on metrics that directly relate to your business objectives
- Build for continuous evaluation: Design your evaluation process to be repeatable as new models are released
Looking forward: The future of model selection
As foundation models evolve, evaluation methodologies must keep pace. Below are further considerations (By no means this list of considerations is exhaustive and is subject to ongoing updates as technology evolves and best practices emerge), you should take into account while selecting the best model(s) for your use-case(s).
- Multi-model architectures: Enterprises will increasingly deploy specialized models in concert rather than relying on single models for all tasks.
- Agentic landscapes: Evaluation frameworks must assess how models perform as autonomous agents with tool-use capabilities and inter-agent collaboration.
- Domain specialization: The growing landscape of domain-specific models will require more nuanced evaluation of specialized capabilities.
- Alignment and control: As models become more capable, evaluation of controllability and alignment with human intent becomes increasingly important.
Conclusion
By implementing a comprehensive evaluation framework that extends beyond basic metrics, organizations can informed decisions about which foundation models will best serve their requirements. For agentic AI applications in particular, thorough evaluation of reasoning, planning, and collaboration capabilities is essential for success. By approaching model selection systematically, organizations can avoid the common pitfalls of over-provisioning, misalignment with use case needs, excessive operational costs, and late discovery of performance issues. The investment in thorough evaluation pays dividends through optimized costs, improved performance, and superior user experiences.
About the author
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.