
Generate recommendations from production traces, validate them with batch evalua...

Business leaders across industries rely on operational dashboards as the shared ...

In this post, we walk through the full journey, from setting up your migration w...

In this post, we take a deeper look at how RLAIF or RL with LLM-as-a-judge works...

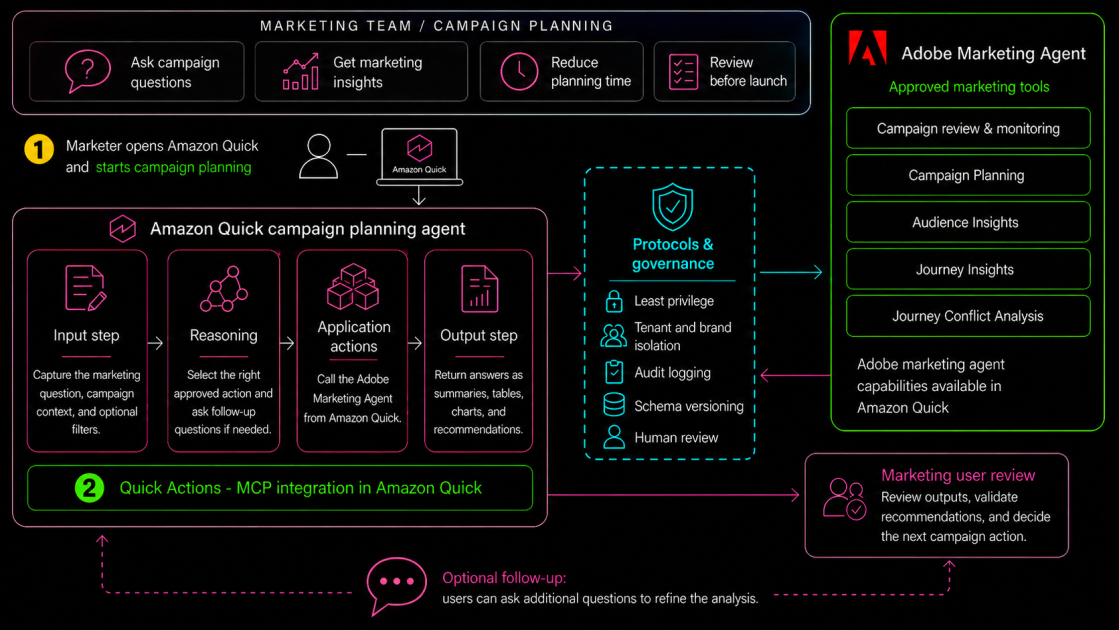
This post demonstrates how agentic AI assistant from Amazon Quick transform data...

In this post, we show how Sun Finance used Amazon Bedrock, Amazon Textract, and ...

In this post, you will configure Amazon Bedrock AgentCore Gateway to access priv...
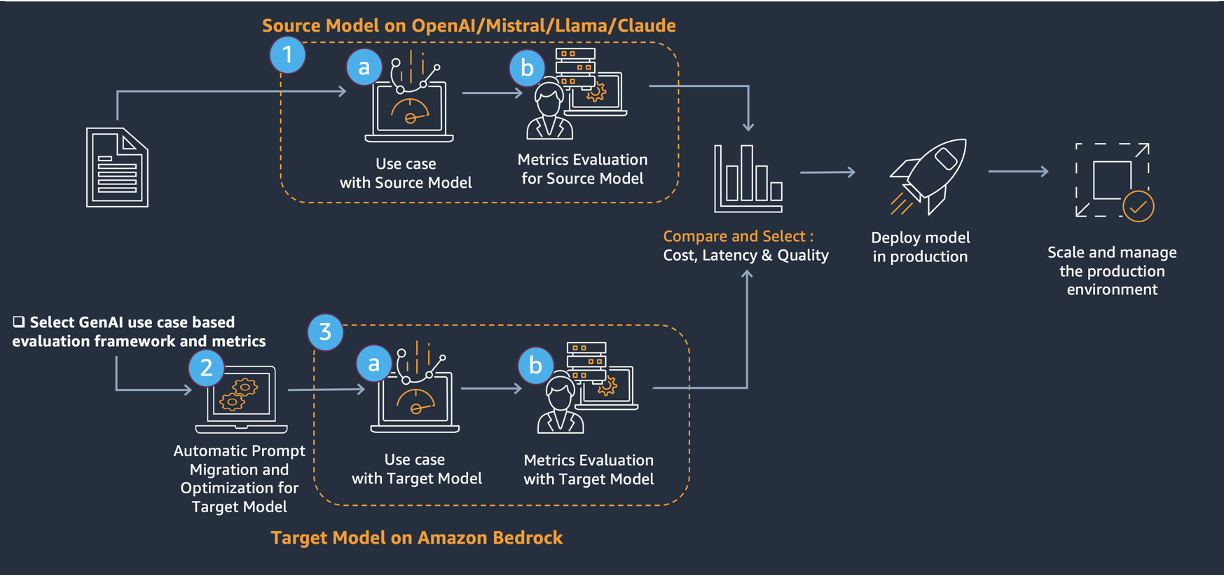
In this post, we introduce a systematic framework for LLM migration or upgrade i...

This post was co-written with Yash Munsadwala, Adam Hood, Justin Guse, and Hecto...
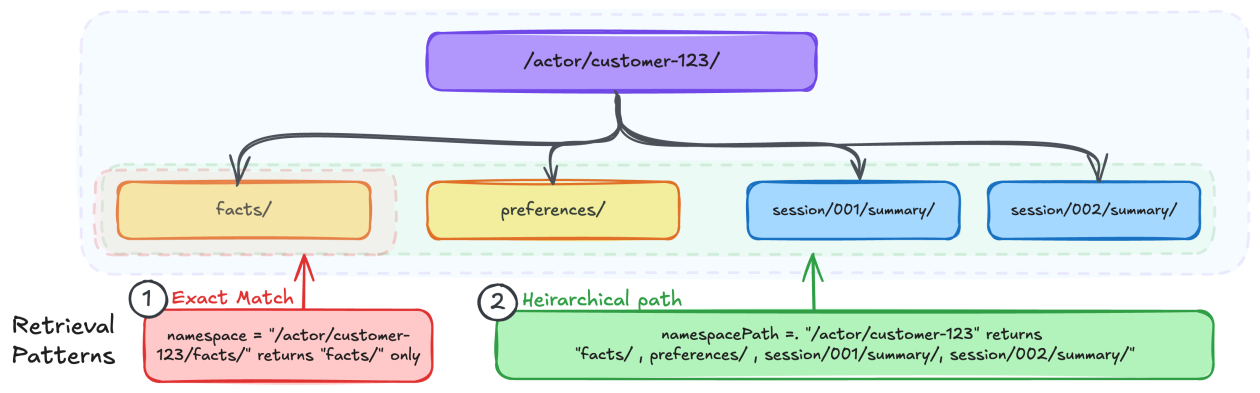
In this post, you will learn how to design namespace hierarchies, choose the rig...

This post shows you how to deploy a serverless MCP proxy on Amazon Bedrock Agent...

In this post, you'll learn how Vanguard built their Virtual Analyst solution by ...

Today, we are excited to announce the day zero availability of NVIDIA Nemotron 3...

In this post, we explore what it takes to migrate a traditional text agent into ...

In this post, we share how we applied Amazon Bedrock and the Amazon Nova family ...

In this post, we demonstrate how to build AI agents using Strands Agents SDK wit...


























![KAIZEN Locations & Map Guide – Boss, Chest, Weapon, Style [KASHIMO]](https://www.destructoid.com/wp-content/uploads/2026/02/kaizen-locations-and-map-guide.jpg)




