










NVIDIA RTX PC 与 DGX Spark 加速由 Hermes 解锁的自主进化 AI 智能体
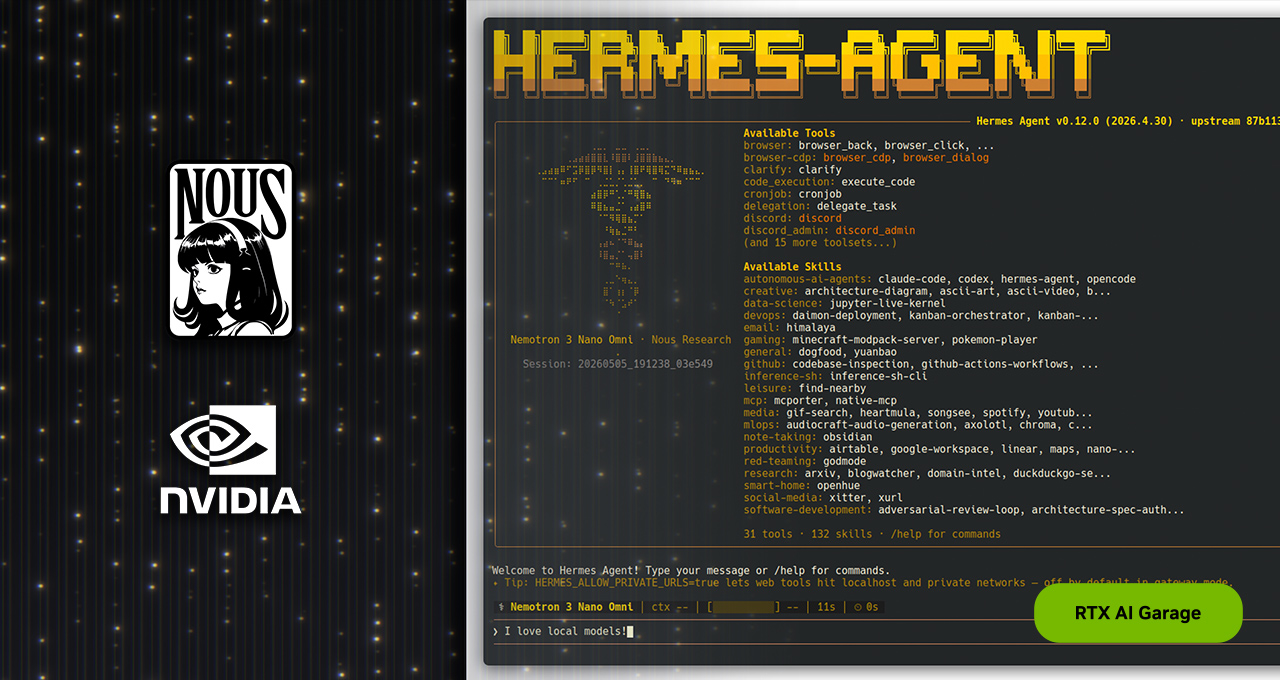
代理式 AI 正在改变用户完成工作的方式。继 OpenClaw 取得成功之后,社区正积极拥抱新的开源代理式框架。最新框架是 Hermes Agent,在不到 3 个月内突破 140,000 GitHub 星标。截至上周,根据 OpenRouter 的数据,它已成为全球使用量最高的智能体。 Nous Research 开发的 Hermes 专为可靠性与自我改进而设计,这两项特质一直以来都很难在智能体中实现。Hermes 特意不绑定提供商和模型,并针对始终在线的本地使用场景进行优化,因此 NVIDI
代理式 AI 正在改变用户完成工作的方式。继 OpenClaw 取得成功之后,社区正积极拥抱新的开源代理式框架。最新框架是 Hermes Agent,在不到 3 个月内突破 140,000 GitHub 星标。截至上周,根据 OpenRouter 的数据,它已成为全球使用量最高的智能体。
Nous Research 开发的 Hermes 专为可靠性与自我改进而设计,这两项特质一直以来都很难在智能体中实现。Hermes 特意不绑定提供商和模型,并针对始终在线的本地使用场景进行优化,因此 NVIDIA RTX PC、NVIDIA RTX PRO 工作站和 NVIDIA DGX Spark 成为全天候全速运行它的理想硬件。
Qwen 3.6 是阿里巴巴推出的新一代高性能开放权重大语言模型 (LLM) 系列,非常适合运行 Hermes 这样的本地智能体。Qwen 3.6 27B 和 35B 参数模型的表现超过了上一代 120B 和 400B 参数模型,并可在 NVIDIA RTX 与 DGX Spark 上运行,为代理式 AI 提供加速。
Hermes:加速本地 AI 智能体能力
与其他热门智能体一样,Hermes 可集成消息应用,访问本地文件和应用,并全天候 24 小时运行。但以下 4 项突出能力让它脱颖而出:
- 自主进化技能:Hermes 会编写并改进自己的技能。每当智能体遇到复杂任务或收到反馈时,它都会将学习成果保存为技能,从而随着时间推移持续适应和改进。
- 受控子智能体:Hermes 将子智能体视为面向子任务的,生命周期很短的单独工作单元,并为其配备专用的上下文和工具集。这可以让任务组织更清晰,减少智能体混淆,并让 Hermes 以更小的上下文窗口运行,非常适合本地模型。
- 可靠性源于设计:Nous Research 会整理并压力测试 Hermes 随附的每一项技能、工具和插件。即使搭配 30B 参数级别的本地模型,Hermes 也能开箱即用,无需像大多数其他智能体框架那样持续调试。
- 同一模型,更好结果:开发者在不同框架中使用相同模型进行比较时,Hermes 始终展现出更好的结果。差异来自框架本身:Hermes 是一个主动编排层,而不是轻量封装器,可支持持久运行的本地端侧智能体,而非逐项任务执行。
Hermes 智能体和底层 LLM 都为本地运行而构建,这意味着硬件质量将直接决定用户体验质量。NVIDIA RTX GPU 正是为这类工作负载而打造。
Qwen 3.6:在本地提供数据中心级智能
最新 Qwen 3.6 模型基于广受认可的 Qwen 3.5 系列打造,为本地 AI 智能体带来又一次飞跃。全新 Qwen 3.6 35B 模型可在约 20GB 内存上运行,同时生成结果超越需要 70GB 以上内存的 120B 参数模型。
Qwen 3.6 27B 是一款新的稠密模型,拥有更多活跃参数,在仅为 Qwen 3.5 397B 等 400B 参数模型 1/16 大小的同时,达到相似的准确率。高端 RTX GPU 可为该模型提供实现高速体验所需的计算能力。这些模型非常适合 Hermes 这样的本地智能体,而 NVIDIA GPU 和 DGX Spark 是运行它们的最快方式。NVIDIA Tensor Cores 可加速 AI 推理,带来更高吞吐量和更低延迟,让 Hermes 能够在数秒而非数分钟内完成多步骤任务,或改进自身的一项技能。
DGX Spark:始终在线的代理式计算机
Hermes 这样的智能体专为持续运行而构建,可以响应请求、规划多步骤任务、自主执行并自我改进。NVIDIA DGX Spark 是理想搭档,它是一台紧凑、高效的独立设备,专为持续全天候代理式工作流而打造。
128GB 统一内存和 1 petaFLOP AI 性能让 NVIDIA DGX Spark 可全天运行 120B 参数混合专家模型。而全新 Qwen 3.6 35B 模型以更精简的占用空间提供同等智能,不仅运行速度更快,还让用户有能力运行并发工作负载。
要最大限度提升性能并简化使用体验,请阅读 Hermes DGX Spark Playbook。欢迎注册 NVIDIA“Build It Yourself”代理式 AI 系列即将举办的实践课程,了解如何使用 NemoClaw 和 OpenShell 构建自主 AI 智能体。NVIDIA DGX Spark 现已可通过 NVIDIA合作伙伴订购,相关信息请查看购买渠道。
开始在 NVIDIA 硬件上使用 Hermes
在 NVIDIA 硬件上本地运行 Hermes 非常简单。
访问 Hermes GitHub 代码库即可开始使用并将其与用户偏好的本地模型和运行时搭配,并通过 llama.cpp、LM Studio 或 Ollama 运行 Qwen 3.6 以搭配 Hermes。Hermes Agent 原生支持 LM Studio 和 Ollama,为本地智能体提供最简单的上手路径。
无论是探索个人智能体前沿的本地 AI 爱好者,还是为自身工作流构建本地工具的开发者,NVIDIA 硬件上的 Hermes 都能提供独特强大且可靠的基础。
敬请关注 RTX AI Garage,了解针对 NVIDIA RTX 硬件优化的最新开放模型和智能体的更多更新。
#别错过:NVIDIA RTX AI Garage 最新动态
 NVIDIA RTX PRO GPU 在运行 Qwen 3.6 模型与 llama.cpp 时,可实现最高 3 倍更快的 token 生成速度。它可为本地 AI 提供所需的实时响应能力,让智能体处理多步骤任务并改进自身技能,从而保持工作流顺畅无缝。
NVIDIA RTX PRO GPU 在运行 Qwen 3.6 模型与 llama.cpp 时,可实现最高 3 倍更快的 token 生成速度。它可为本地 AI 提供所需的实时响应能力,让智能体处理多步骤任务并改进自身技能,从而保持工作流顺畅无缝。
Google Gemma 4 26B 和 31B 模型现已推出 NVFP4 checkpoint,可在 NVIDIA Blackwell GPU 上实现更快性能。将 NVFP4 checkpoint与 Google 全新 Multi-Token Prediction 草稿模型搭配使用,可在相同输出质量下实现最高 3 倍更快推理,让前沿级推理能够在 NVIDIA GPU 上本地运行。
Mistral Medium 3.5 版已于 4月发布,包含与 llama.cpp 和 Ollama 的兼容性更新,使用户能够在 NVIDIA RTX PRO 和 DGX Spark 系统上运行。
 NVIDIA 最近推出了 NVIDIA NemoClaw,这是一个可通过增强安全性和支持本地模型的开源堆栈,在 NVIDIA 设备上优化 OpenClaw 体验。NemoClaw 现已支持 Windows Subsystem for Linux (WSL2),为微软平台上的爱好者和开发者带来支持。开始在 DGX Spark 上使用 NemoClaw,请查看 Playbook。
NVIDIA 最近推出了 NVIDIA NemoClaw,这是一个可通过增强安全性和支持本地模型的开源堆栈,在 NVIDIA 设备上优化 OpenClaw 体验。NemoClaw 现已支持 Windows Subsystem for Linux (WSL2),为微软平台上的爱好者和开发者带来支持。开始在 DGX Spark 上使用 NemoClaw,请查看 Playbook。





